
10 近似算法
近似算法
1 近似算法
概念
- 不同的近似算法有各种各样的复杂度,但其中许多算法都是基于特定问题的直观推断贪婪算法。直观推断是一种来自于经验而不是来自于数学证明的常识性规则。如果我们使用的算法所给出的输出仅仅是实际最优解的一个逼近,我们就会想知道这个逼近有多精确。
近似算法精度
- 对于一个对某些函数 f 最小化的问题来说,可以用近似解的相对误差规模
$$
re(S_a)=\frac{f(S_*)}{f(S^a)}
$$
近似算法的性能
- 对于问题的所有实例,它们可能的r(sa)的最佳(也就是最低)上界,被称为该算法的性能比,计作RA。
- 性能比是一个来指出近似算法质量的主要指标,我们需要那些RA尽量接近1的近似算法。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2021-12-24
id
id打印真实以及有效的用户和所在组的信息 概要1id [OPTION]... [USER]... 主要用途 没有选项时,打印指定用户ID信息。 选项12345678-a 兼容性选项,没有实际作用。-Z, --context 只打印进程的安全上下文。-g, --group 只打印有效的组ID。-G, --groups 打印全部组ID。-u, --user 只打印有效的用户ID。-z, --zero 使用空字符代替默认的空格来分隔条目。--help 显示帮助信息并退出。--version 显示版本信息并退出。 只有在使用 -u -g -G 选项中一到多个时,以下选项可以使用: 12-n, --name 打印名称而不是数字。-r, --real 打印真实ID而不是有效ID。 参数user(可选):可以为一到多个,默认为当前用户。 返回值返回0表示成功,返回非0值表示失败。 例子12[root@localhost ~]# iduid=0(root) gid=0...
2021-03-09
网络层概念学习之一(基本概念、路由器、选路算法)
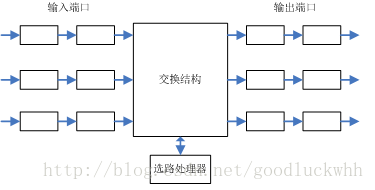
网络层建立在链路层之上,它的最主要的功能是使得网络中的各个主机之间可以互相通信。在因特网中,IP层是TCP/IP协议族中最为核心的协议,也是最复杂的层次之一。 一、概述 1.转发和选路 网络层的功能是要将分组从一个主机移动到另一个主机从而使得主机之间可以互相通信。为此需要网络层提供两种功能: 存储转发:路由器(三层交换机)将进入其某个输入链路的分组转发到其某个输出链路。它是将分组从一个输入链路移动到一个输出链路,是一个路由器的本地动作。 路由选择:在分组从一个主机流向另一个主机的过程中,网络层必须决定分组所走过的路径。计算这个路径信息的算法就是路由算法。它是一个网络范围的动作,决定分组从其源到目的应该走的路径 路由器在网络层是一个极其重要的设备,每台路由器都由一张转发表。路由器检查到达分组首部中的一个字段的值,然后利用该值在路由器的转发表中进行查询,以决定该如何转发该分组。查询的结果是分组将被转发的路由器的链路接口。 选路算法决定了转发表中的值。选路算法可能是集中式(由某个中心点执行)的也可能是分布式的(运行在各台路由器上),无论采用何种方法,路由器都要接受选路协议报文...
2021-03-09
传输层学习之三(TCP数据传输)
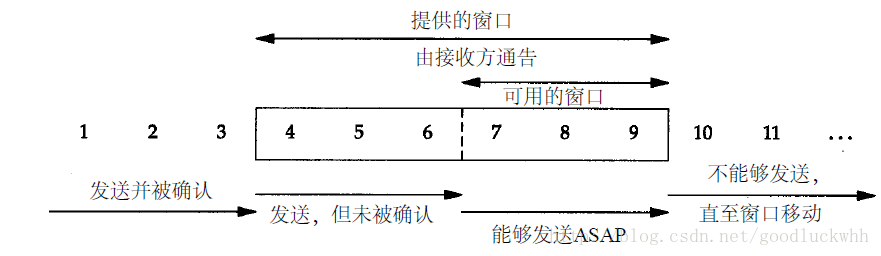
TCP提供了可靠的传输服务,这是通过下列方式提供的: 应用数据被分割成TCP认为最适合发送的数据块。由TCP传递给IP的信息单位称为报文段或段(segment) 当TCP发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。 当TCP收到发自TCP连接另一端的数据,它将发送一个确认。这个确认不是立即发送,通常将推迟几分之一秒 TCP将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP将丢弃这个报文段和不确认收到此报文段(希望发端超时并重发)。 由于IP数据报的到达可能会失序,因此TCP报文段的到达也可能会失序。如果必要,TCP将对收到的数据进行重新排序,将收到的数据以正确的顺序交给应用层。 IP数据报会发生重复,TCP的接收端必须丢弃重复的数据。 TCP还能提供流量控制。TCP连接的每一方都有固定大小的缓冲空间。TCP的接收端只允许另一端发送接收端缓冲区所能接纳的数据。这将防止较快主机致使较慢主机的缓冲区溢出。 一、可靠传输的原理 由于网络环...
2021-03-20
8
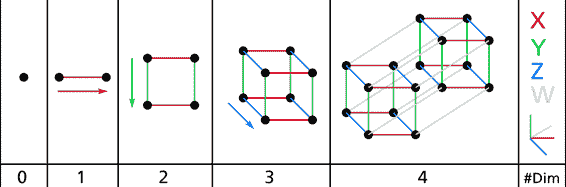
八、降维 译者:@loveSnowBest 校对者:@飞龙、@PeterHo、@yanmengk、@XinQiu、@Lisanaaa 很多机器学习的问题都会涉及到有着几千甚至数百万维的特征的训练实例。这不仅让训练过程变得非常缓慢,同时还很难找到一个很好的解,我们接下来就会遇到这种情况。这种问题通常被称为维数灾难(curse of dimentionality)。 幸运的是,在现实生活中我们经常可以极大的降低特征维度,将一个十分棘手的问题转变成一个可以较为容易解决的问题。例如,对于 MNIST 图片集(第 3 章中提到):图片四周边缘部分的像素几乎总是白的,因此你完全可以将这些像素从你的训练集中扔掉而不会丢失太多信息。图 7-6 向我们证实了这些像素的确对我们的分类任务是完全不重要的。同时,两个相邻的像素往往是高度相关的:如果你想要将他们合并成一个像素(比如取这两个像素点的平均值)你并不会丢失很多信息。 警告:降维肯定会丢失一些信息(这就好比将一个图片压缩成 JPEG 的格式会降低图像的质量),因此即使这种方法可以加快训练的速度,同时也会让你的系统表现的稍微差一点。降维...
2020-10-14
序列模型和注意力机制
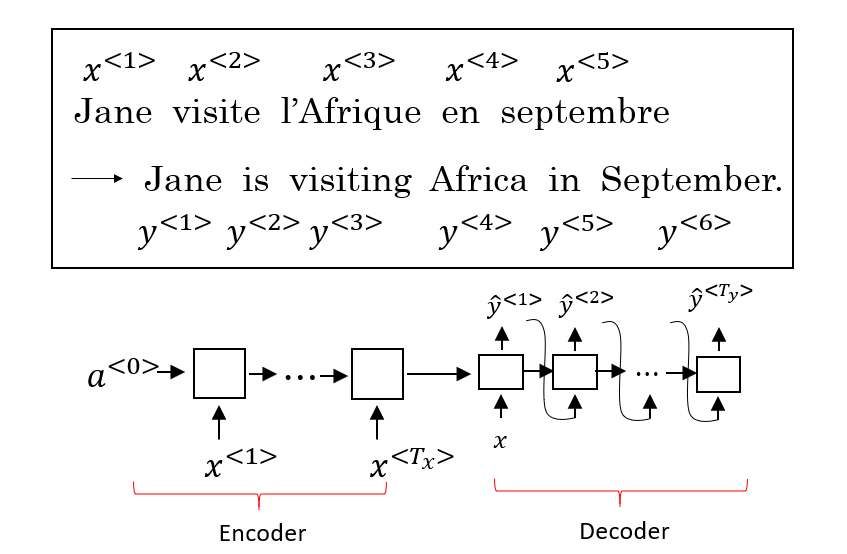
序列模型和注意力机制Seq2Seq 模型 Seq2Seq(Sequence-to-Sequence) 模型能够应用于机器翻译、语音识别等各种序列到序列的转换问题。一个 Seq2Seq 模型包含 编码器(Encoder) 和 解码器(Decoder) 两部分,它们通常是两个不同的 RNN。如下图所示,将编码器的输出作为解码器的输入,由解码器负责输出正确的翻译结果。 提出 Seq2Seq 模型的相关论文: Sutskever et al., 2014. Sequence to sequence learning with neural networks Cho et al., 2014. Learning phrase representaions using RNN encoder-decoder for statistical machine translation 这种编码器-解码器的结构也可以用于图像描述(Image captioning)。将 AlexNet 作为编码器,最后一层的 Softmax 换成一个 RNN 作为解码器,网络的输出序列就是对图像的一个描...
2021-03-20
3 使用距离向量构建模型
第三章 使用距离向量构建模型 作者:Trent Hauck 译者:飞龙 协议:CC BY-NC-SA 4.0 这一章中,我们会涉及到聚类。聚类通常和非监督技巧组合到一起。这些技巧假设我们不知道结果变量。这会使结果模糊,以及实践客观。但是,聚类十分有用。我们会看到,我们可以使用聚类,将我们的估计在监督设置中“本地化”。这可能就是聚类非常高效的原因。它可以处理很大范围的情况,通常,结果也不怎么正常。 这一章中我们会浏览大量应用,从图像处理到回归以及离群点检测。通过这些应用,我们会看到聚类通常可以通过概率或者优化结构来观察。不同的解释会导致不同的权衡。我们会看到,如何训练模型,以便让工具尝试不同模型,在面对聚类问题的时候。 3.1 使用 KMeans 对数据聚类聚类是个非常实用的技巧。通常,我们在采取行动时需要分治。考虑公司的潜在客户列表。公司可能需要将客户按类型分组,之后为这些分组划分职责。聚类可以使这个过程变得容易。 KMeans 可能是最知名的聚类算法之一,并且也是最知名的无监督学习技巧之一。 准备首先,让我们看一个非常简单的聚类,之后我们再讨论 KMeans 如何工作...




