
6.1 Huffman算法
Huffman算法
Huffman算法
问题描述
一个字符串文件,我们希望尽可能多地压缩文件,但源文件能够很容易地被重建。
用特定的比特串表示每个字符,称为字符的编码,文件的大小取决于文件中的字符数n。我们可以使用一种定长编码,对每个字符赋予一个长度同为m (m≥log2n)的比特串。
设文件中的字符集是C={c1,c2,…, cn}, 又设f(ci), 1≤i≤n,是文件中字符ci的频度,即文件中ci出现的次数。
由于有些字符的频度可能远大于另外一些字符的频度,所以用变长的编码。
去除编码的二义性:
当编码在长度上变化时,我们规定一个字符的编码不能是另一个字符编码的前缀(即词头),这种码称为前缀码。
例如,如果我们把编码10和101赋予字符“a” 和“b”就会存在二义性,不清楚10究竟是“a” 的编码还是字符“b”的编码的前缀。
一旦满足前缀约束,编码即不具备二义性,可以扫描比特序列直到找到某个字符的编码。
算法原理
- 由Huffman算法构造的编码满足前缀约束,并且最小化压缩文件的大小。算法重复下面的过程直到C仅由一个字符组成:
- 设ci和cj是两个有最小频度的字符,建立一个新节点c,它的频度是ci和cj频度的和,使ci和cj为c的子节点,
- 令C = (C-{ci, cj})∪{c}。
算法过程
第一步:初始化n个单节点的树,为它们标上字母表的字符。把每个字符的概率记在树的根中,用来指出树的权重(更一般地来说,树的权重等于树中所有叶子的概率之和)。
第二步:重复下面的步骤,直到只剩一棵单独的树:
- 找到两棵权重最小的树, 把它们作为新树中的左右子树,并把其权重之和作为新的权重记录在新的根中。
构建树后然后进行编码,从根节点,每个路径上左0右1
算法效率
$O(n/log n)$
算法实现
1 | 算法HUFFMAN |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2021-12-24
userdel
userdel用于删除给定的用户以及与用户相关的文件 补充说明userdel命令 用于删除给定的用户,以及与用户相关的文件。若不加选项,则仅删除用户帐号,而不删除相关文件。 语法1userdel(选项)(参数) 选项12-f:强制删除用户,即使用户当前已登录;-r:删除用户的同时,删除与用户相关的所有文件。 参数用户名:要删除的用户名。 实例userdel命令很简单,比如我们现在有个用户linuxde,其家目录位于/var目录中,现在我们来删除这个用户: 12userdel linuxde # 删除用户linuxde,但不删除其家目录及文件;userdel -r linuxde # 删除用户linuxde,其家目录及文件一并删除; 请不要轻易用-r选项;他会删除用户的同时删除用户所有的文件和目录,切记如果用户目录下有重要的文件,在删除前请备份。 其实也有最简单的办法,但这种办法有点不安全,也就是直接在/etc/passwd中删除您想要删除用户的记录;但最好不要这样做,/etc/passwd是极为重要的文件,可能您一不小心会操作失误。
2020-01-04
3.2 搜索算法-广度优先搜索
广度优先搜索1 概述特点 广度优先搜索(BFS:Breadth-First Search)是一种树和图搜索策略,其将搜索限制到 2 种操作: 访问图中的一个节点; 访问该节点的邻居节点; 过程 广度优先搜索(BFS)由 Edward F. Moore 在 1950 年发表,起初被用于在迷宫中寻找最短路径。在 Prim 最小生成树算法和 Dijkstra 单源最短路径算法中,都采用了与广度优先搜索类似的思想。 对图的广度优先搜索与对树(Tree)的广度优先遍历(Breadth First Traversal)是类似的,区别在于图中可能存在环,所以可能会遍历到已经遍历的节点。BFD 算法首先会发现和源顶点 s 距离边数为 k 的所有顶点,然后才会发现和 s 距离边数为 k+1 的其他顶点。 例子 例如,下面的图中,从顶点 2 开始遍历,当遍历到顶点 0 时,邻接的顶点为 1 和 2,而顶点 2 已经遍历过,如果不做标记,遍历过程将陷入死循环。所以,在 BFS 的算法实现中需要对顶点是否访问过做标记。 上图的 BFS 遍历结果为 [ 2, 0, 3, 1 ]。 实...

2021-12-24
xclip
xclip管理 X 粘贴板 补充说明在 X 系统里面,从一个窗口复制一段文字到另一个窗口,有两套机制,分别是 Selections 和 cut buffers。 常用的 copy & paste 是利用的 cut buffers 机制;另外用鼠标选中一段文字,然后在另一个窗口按鼠标中键实现复制,利用的是 selections 机制。selection 又可以分为 master 和 slave selection。 当用鼠标选中一段文件,这段文字就自动被复制到 master selection。然后在另一个地方按鼠标中键,就自动把 master selection 的内容粘贴出来。 当你想复制少量文字的时候,两种方法都是很方便的。但是当复制大段文字的时候就挺麻烦。另外就是你可能会频繁的执行一些复制粘贴工作,不停的用鼠标选中文字,然后再粘贴。这是对手指的折磨。 我忍受不了这种折磨,所以发现了 xclip, 方便的管理 X selections 里面内容的工具。 比如如下命令就把文件 /etc/passwd 的内容复制到 X master selection...

2021-12-24
ls
ls显示目录内容列表 补充说明ls命令 就是list的缩写,用来显示目标列表,在Linux中是使用率较高的命令。ls命令的输出信息可以进行彩色加亮显示,以分区不同类型的文件。 语法12345ls [选项] [文件名...] [-1abcdfgiklmnopqrstuxABCDFGLNQRSUX] [-w cols] [-T cols] [-I pattern] [--full-time] [--format={long,verbose,commas,across,vertical,single-col‐umn}] [--sort={none,time,size,extension}] [--time={atime,access,use,ctime,status}] [--color[={none,auto,always}]] [--help] [--version] [--] 选项1234567891011121314151617181920212223242526272829...
2023-09-09
07 有无状态服务
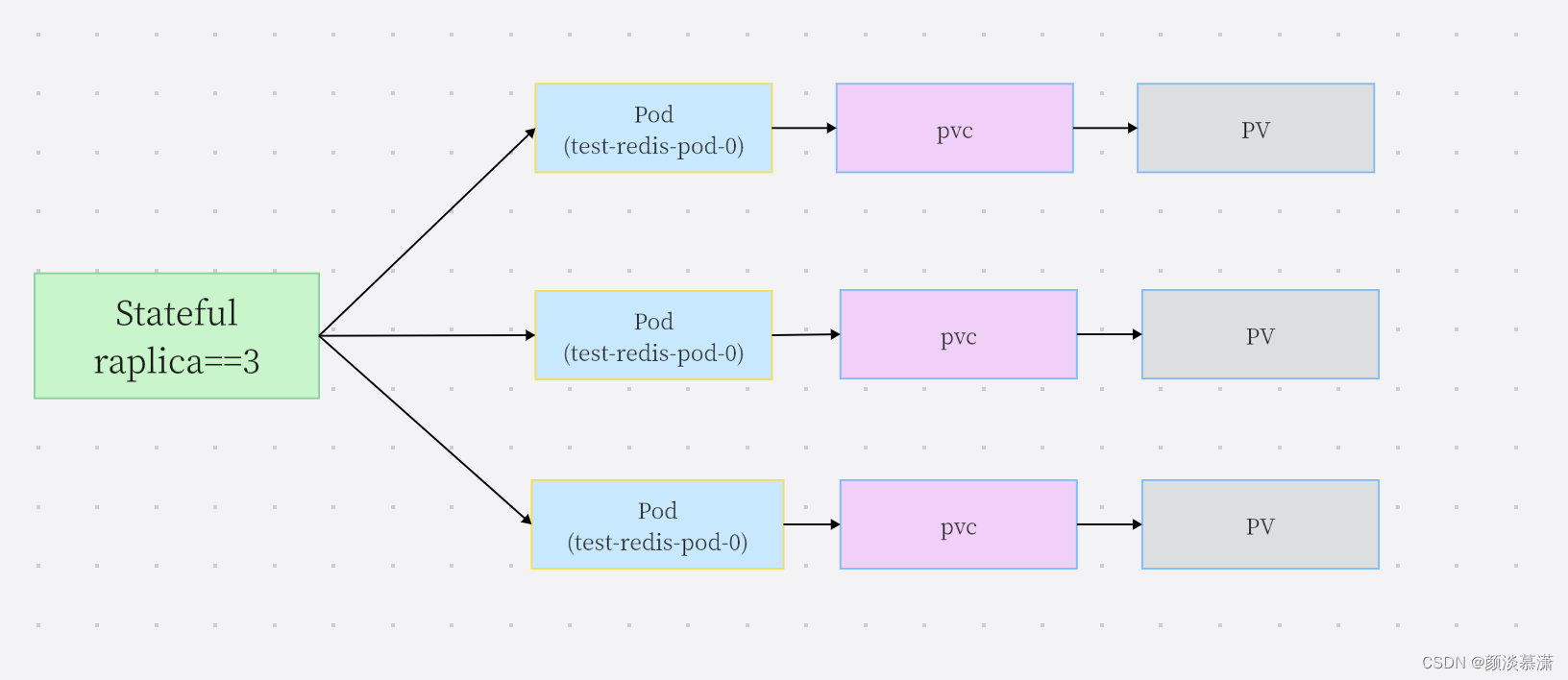
1 有无状态服务对比无状态服务 数据方面:无状态服务不会在本地存储持久化数据.多个实例可以共享相同的持久化数据 结果方面:多个服务实例对于同一个用户请求的响应结果是完全一致的 关系方面:这种多服务实例之间是没有依赖关系 影响方面:在k8s控制器 中动态启停无状态服务的pod并不会对其它的pod产生影响 示例方面:nginx实例,tomcat实例,web应用 资源方面:相关的k8s资源有:ReplicaSet、ReplicationController、Deployment 创建方式:Deployment被设计用来管理无状态服务的pod。每个pod完全一致,原因如下: 无状态服务内的多个Pod创建的顺序是没有顺序的 无状态服务内的多个Pod的名称是随机的.pod被重新启动调度后,它的名称与IP都会发生变化 无状态服务内的多个Pod背后是共享存储的 缩容方式:随机缩容。由于是无状态服务,所以这些控制器创建的pod序号都是随机值。并且在缩容也是随机,并不会明确缩容某一个pod。因为所有实例得到的返回值都是一样,所以缩容任何一个pod都可以 有状态服务 数据方面:有状态服务需要在本...

2021-12-24
systemctl
systemctl系统服务管理器指令 补充说明systemctl命令 是系统服务管理器指令,它实际上将 service 和 chkconfig 这两个命令组合到一起。 任务 旧指令 新指令 使某服务自动启动 chkconfig –level 3 httpd on systemctl enable httpd.service 使某服务不自动启动 chkconfig –level 3 httpd off systemctl disable httpd.service 检查服务状态 service httpd status systemctl status httpd.service (服务详细信息) systemctl is-active httpd.service (仅显示是否 Active) 显示所有已启动的服务 chkconfig –list systemctl list-units –type=service 启动服务 service httpd start systemctl start httpd.service 停止服务 ser...




