
1.3 图算法-Bellman-Ford算法
图算法-Bellman-Ford算法
目录
- 图算法-Dijkstra算法
- 图算法-Floyd算法
- 图算法-Bellman-Ford算法
- 图算法-Prim算法
- 图算法-Kruskal算法
bellman ford 和 SPFA两个算法等到以后再学吧。我赌十块不需要。等到下次在复习的时候完善这两个算法,已经没时间了
参考文献
这两个博客够了
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2021-12-24
logsave
logsave将命令的输出信息保存到指定的日志文件 补充说明logsave命令 运行给定的命令,并将命令的输出信息保存到指定的日志文件中。 语法1logsave(选项)(参数) 选项1-a:追加信息到指定的日志文件中。 参数 日志文件:指定记录运行信息的日志文件; 指令:需要执行的指令。

2021-09-06
Select socket
过程分析 用户进程创建socket对象,拷贝监听的fd到内核空间,每一个fd会对应一张系统文件表,内核空间的fd响应到数据后,就会发送信号给用户进程数据已到; 用户进程再发送系统调用,比如(accept)将内核空间的数据copy到用户空间,同时作为接受数据端内核空间的数据清除,这样重新监听时fd再有新的数据又可以响应到了(发送端因为基于TCP协议所以需要收到应答后才会清除) 优点 相比其他模型,使用select() 的事件驱动模型只用单线程(进程)执行,占用资源少,不消耗太多 CPU,同时能够为多客户端提供服务。如果试图建立一个简单的事件驱动的服务器程序,这个模型有一定的参考价值。 缺点 首先select()接口并不是实现“事件驱动”的最好选择。因为当需要探测的句柄值较大时,select()接口本身需要消耗大量时间去轮询各个句柄。 很多操作系统提供了更为高效的接口,如linux提供了epoll,BSD提供了kqueue,Solaris提供了/dev/poll,…。 如果需要实现更高效的服务器程序,类似epoll这样的接口更被推荐。遗憾的是不同的操作系统特供...

2021-12-24
nano
nano字符终端文本编辑器 补充说明nano 是一个字符终端的文本编辑器,有点像DOS下的editor程序。它比vi/vim要简单得多,比较适合Linux初学者使用。某些Linux发行版的默认编辑器就是nano。 nano命令可以打开指定文件进行编辑,默认情况下它会自动断行,即在一行中输入过长的内容时自动拆分成几行,但用这种方式来处理某些文件可能会带来问题,比如Linux系统的配置文件,自动断行就会使本来只能写在一行上的内容折断成多行了,有可能造成系统不灵了。因此,如果你想避免这种情况出现,就加上-w选项吧。 语法1nano [选项] [[+行,列] 文件名]... 选项123456789101112131415161718192021222324252627282930313233343536373839404142-h, -? --help 显示此信息+行,列 从所指列数与行数开始-A --smarthome ...

2021-03-09
基础篇——3.数据类型
MySQL数据类型整型TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT 分别使用 8, 16, 24, 32, 64 位存储空间,一般情况下越小的列越好。 INT(11) 中的数字只是规定了交互工具显示字符的个数,对于存储和计算来说是没有意义的。 浮点数FLOAT 和 DOUBLE 为浮点类型,DECIMAL 为高精度小数类型。CPU 原生支持浮点运算,但是不支持 DECIMAl 类型的计算,因此 DECIMAL 的计算比浮点类型需要更高的代价。 FLOAT、DOUBLE 和 DECIMAL 都可以指定列宽,例如 DECIMAL(18, 9) 表示总共 18 位,取 9 位存储小数部分,剩下 9 位存储整数部分。 字符串主要有 CHAR 和 VARCHAR 两种类型,一种是定长的,一种是变长的。 VARCHAR 这种变长类型能够节省空间,因为只需要存储必要的内容。但是在执行 UPDATE 时可能会使行变得比原来长,当超出一个页所能容纳的大小时,就要执行额外的操作。MyISAM 会将行拆成不同的片段存储,而 InnoDB 则需要分裂页来使行放进页内...
2021-03-20
36
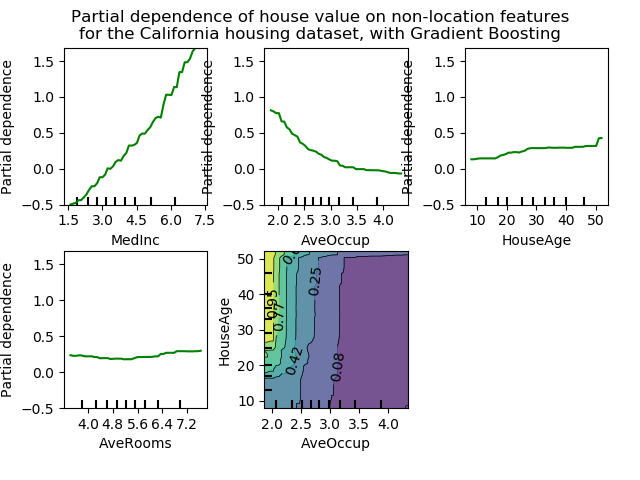
4.1. 部分依赖图校验者: 待核验翻译者: @Loopy 部分依赖图(以下简称PDP)显示了目标响应[1]和一组“目标”特征之间的依赖关系,并边缘化所有其他特征(特征补集,是目标特征集关于全部特征集合的补集)的值。直观地,我们可以将部分依赖关系解释为预期目标响应作为“目标”特征的函数。 由于人类感知的限制,目标特征集的大小必须很小(通常是一个或两个),因此目标特征通常需要从最重要的特征中选择。 下图展示了使用GradientBoostingRegressor实现的,加利福尼亚州住房数据集的四个单向和一个双向PDP: 单向PDP告诉我们目标响应和目标特征(如线性、非线性)之间的相互作用。上图左上方的图表显示了一个地区的收入中位数对房价中位数的影响;我们可以清楚地看到它们之间的线性关系。注意,PDP假设目标特征独立于补体特征,而这一假设在实践中经常被推翻。 具有两个目标特征的PDP显示了这两个特征之间的相互作用。例如,上图中的双变量PDP显示了房价中值与房屋年龄和每户平均居住者的联合值之间的关系。我们可以清楚地看到这两个特征之间的相互作用:对于平均入住...
2021-03-20
3 使用距离向量构建模型
第三章 使用距离向量构建模型 作者:Trent Hauck 译者:飞龙 协议:CC BY-NC-SA 4.0 这一章中,我们会涉及到聚类。聚类通常和非监督技巧组合到一起。这些技巧假设我们不知道结果变量。这会使结果模糊,以及实践客观。但是,聚类十分有用。我们会看到,我们可以使用聚类,将我们的估计在监督设置中“本地化”。这可能就是聚类非常高效的原因。它可以处理很大范围的情况,通常,结果也不怎么正常。 这一章中我们会浏览大量应用,从图像处理到回归以及离群点检测。通过这些应用,我们会看到聚类通常可以通过概率或者优化结构来观察。不同的解释会导致不同的权衡。我们会看到,如何训练模型,以便让工具尝试不同模型,在面对聚类问题的时候。 3.1 使用 KMeans 对数据聚类聚类是个非常实用的技巧。通常,我们在采取行动时需要分治。考虑公司的潜在客户列表。公司可能需要将客户按类型分组,之后为这些分组划分职责。聚类可以使这个过程变得容易。 KMeans 可能是最知名的聚类算法之一,并且也是最知名的无监督学习技巧之一。 准备首先,让我们看一个非常简单的聚类,之后我们再讨论 KMeans 如何工作...




