
07拟合与正则化
过拟合
偏差
- bias
- 是系统性误差,由于模型本身引起的。
方差
- var
- 是样本数据误差,由于样本数据的随机性引起的。
欠拟合与过拟合
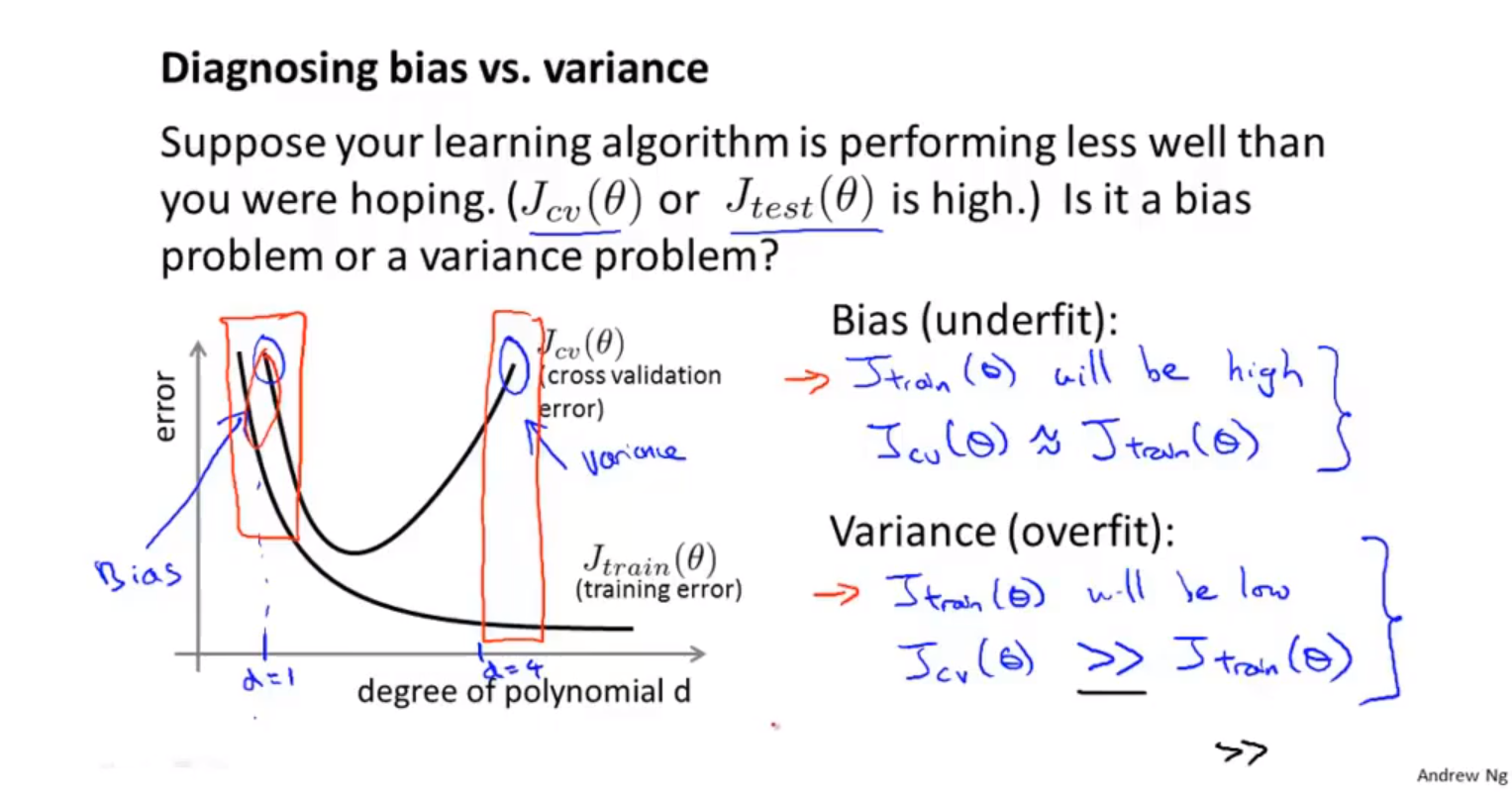
jtrain训练集的代价函数。jcv交叉验证集的代价函数。jtrain能够通过训练过程,将样本随机性引起的误差降到最低。jcv没有经过训练过程,会最大化样本的随机性方差和模型本身的偏差。
- 高偏差:Jtrain和Jcv都很大,并且Jtrain≈Jcv。对应欠拟合。欠拟合的时候,由模型本身和样本的随机性引起的误差都很大。
- 高方差:Jtrain较小,Jcv远大于Jtrain。对应过拟合。过拟合后由样本随机性引起的误差会非常大。
- 低方差,高偏差。变量过多的时候出现的,训练得到的假设函数能够很好的拟合训练集,代价函数非常小。但是无法泛化到新的样本当中。
解决办法
- 减少特征的数量
- 对特征进行正则化。
正则化
代价函数加入正则化的数据项,用来缩小每一个参数。
现行回归的正则化代价函数
$$
J(\theta) = \frac{1}{2m}[\sum_1^m(h_\theta(x^{(i)})-y^{(i)})^2+\lambda\sum_1^n\theta^2_j]
$$逻辑回归的正则化,二者一致。
$$
J(\theta)=-\frac{1}{m}[\sum_i^my^{(i)}\log h_\theta(x^{(i)})+(1-y^{(i)})\log (1-h_\theta (x^{(i)}))]+\frac{\lambda}{2m}\sum_1^n\theta_j^2
$$
编程任务
线性回归
- 添加,高阶的编程项.
- 对参数进行正则化,并对比正则化前后假设函数的不同。
- 需要绘制,拟合过程参数变化率(梯度下降速度。
- 需要绘制,拟合完成后假设函数(假设函数的最终形状。判断是否过拟合。
逻辑回归
- 添加,高阶的编程项.
- 对参数进行正则化,并对比正则化前后假设函数的不同。
- 需要绘制,拟合过程参数变化率(梯度下降速度。
- 需要绘制,拟合完成后假设函数(假设函数的最终形状。判断是否过拟合。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2021-03-20
28
2.9. 神经网络模型(无监督)校验者: @不将就 @Loopy @barrycg @N!no翻译者: @夜神月 2.9.1. 限制波尔兹曼机限制玻尔兹曼机(Restricted Boltzmann machines,简称 RBM)是基于概率模型的无监督非线性特征学习器。当用 RBM 或多层次结构的RBMs 提取的特征在馈入线性分类器(如线性支持向量机或感知机)时通常会获得良好的结果。 该模型对输入的分布作出假设。目前,scikit-learn 只提供了 BernoulliRBM,它假定输入是二值(binary values)的,或者是 0 到 1 之间的值,每个值都编码特定特征被激活的概率。 RBM 尝试使用特定图形模型最大化数据的似然。它所使用的参数学习算法(随机最大似然)可以防止特征表示偏离输入数据。这使得它能捕获到有趣的特征,但使得该模型对于小数据集和密度估计不太有效。 该方法在初始化具有独立 RBM 权值的深度神经网络时得到了广泛的应用。这种方法是无监督的预训练。 示例: Restricted ...
2020-10-11
10算法改进
算法改进提高算法的性能 使用测试集后,模型训练的效果比较差。 解决办法: 使用更多的数据集进行训练。大部分情况下没有用。 尝试选用更少的特征。 添加更多的数据特征。 添加多项式数据特征(交叉数据特征) 修改正则化参数lambda的值。 评估假设 数据集分为训练集和测试集。7:3。 需要提前对数据进行随机化排列,然后进行训练集和测试集的划分。 然后计算测试集的均方误差。 对于分类问题可以,直接定义测试误差。 模型选择 数据集分为训练集、交叉验证集、测试集。6:2:2 假定多个不同的假设函数,使用交叉验证集,评估每一个假设函数训练出 的模型。选择效果最好的假设函数。 然后使用测试集对机器学习算法进行评估。 能够达到泛化误差的效果。 诊断偏差与方差 偏差较大,欠拟合。方差过大,过拟合。 当训练集与交叉验证集的误差都很高时,误差主要由偏差引起。 当训练集与交叉验证集的误差相差很大时,误差主要由方差引起,出现过拟合现象。 正则化与偏差和方差的关系 当正则化参数$\lambda$非常大时,会出现欠拟合的现象,此时代价函数的主要由参数引起,导致拟合过程中,训练参数无限制变小。 当...
2021-03-09
绘图功能
MATLAB中的绘图功能 >二维高层绘图的基本函数 plot函数 plot(x,y); x和y为相同长度的向量 如果plot为单个参数,绘制折现图,横坐标为自然数。如果参数为复数,则实轴和虚轴进行绘制。(可以绘制圆) 如果绘制过程中,自变量为向量,因变量为矩阵,则对矩阵的每一个列向量,绘制一个关于自变量的图像。也就是说,如果想要在同一图中绘制函数,不需要写多个plot,只需要将因变量转换为矩阵就好。 如果绘制过程中,自变量和因变量同为高阶矩阵,则会为x的每一列为自变量,y的每一列为因变量,绘图。 注意行向量的能够组合成行向量矩阵,列项量能组合成列项量矩阵。 linespace()和冒号表达式均可以产生行向量 >二维高层绘图辅助操作 涉及到的函数、控制或者命令 这里有一张图片 标注 坐标轴控制 这里有一张图片 图形名称 曲线名称 图例 图形保持 窗口分割 这里有一张图片 可以使用latex字符进行控制 xlim([xmin,xmax]) ylim([ymin,ymax]) axis([xmin,xma...

2019-10-24
第11节 假设检验
假设检验相关定义 第一章阐述样本统计量与总体属性的关系。第二章参数估计,通过样本的统计量对总体的参数进行估计。并对估计的优劣进行判断,求最优的统计量。区间估计主要是通过置信水平,求置信区间。第三章假设检验。总体分布已知,参数已知。通过样本的统计量,对参数的正确性进行验证。 本节的逻辑 对参数做出假设,$\Theta_0,\Theta_1$。 计算检验统计量的接受拒绝区间$W^c,W$。 检验统计量的拒绝接受区间对应的概率。称为势和势函数。 定义1:原假设与备择假设 所要检验的假设称为原假设或零假设,记为$H_0$。 与$H_0$不相容的假设称为备择假设或对立假设,记为$H_1$。 对参数分布族${p(x;\theta):\theta\in\Theta}$,原假设和备择假设这对矛盾统一体,称为假设检验:$$H_0:\theta\in\Theta_0,H_1:\theta\in\Theta_1$$ 定义2:拒绝域、接受域、检验统计量、检验函数 这里最奇怪的地方是反向表示,拒绝、失信为首选方,使用简单的方式表示。$\alpha,W,\varphi(x)=1$ ...

2021-04-06
MATLAB7
MATLAB中的绘图功能>二维高层绘图的基本函数 plot函数 plot(x,y); x和y为相同长度的向量 如果plot为单个参数,绘制折现图,横坐标为自然数。如果参数为复数,则实轴和虚轴进行绘制。(可以绘制圆) 如果绘制过程中,自变量为向量,因变量为矩阵,则对矩阵的每一个列向量,绘制一个关于自变量的图像。也就是说,如果想要在同一图中绘制函数,不需要写多个plot,只需要将因变量转换为矩阵就好。 如果绘制过程中,自变量和因变量同为高阶矩阵,则会为x的每一列为自变量,y的每一列为因变量,绘图。 注意行向量的能够组合成行向量矩阵,列项量能组合成列项量矩阵。 linespace()和冒号表达式均可以产生行向量 >二维高层绘图辅助操作 涉及到的函数、控制或者命令这里有一张图片 标注 坐标轴控制 这里有一张图片 图形名称 曲线名称 图例 图形保持 窗口分割 这里有一张图片 可以使用latex字符进行控制 xlim([xmin,xmax]) ylim([ymin,ymax]) axis([xmin,xmax,ymin,ymax])

2020-09-29
083D与动画
3D与动画基本方法本章知识点归纳如下: 创建3D图:ax = Axes3D(fig) 画出3D图:ax.plot_surface() 投影:ax.contourf() 动画:animation.FuncAnimation() 3D作图首先在进行 3D Plot 时除了导入 matplotlib ,还要额外添加一个模块,即 Axes 3D 3D 坐标轴显示,并且之后要先定义一个图像窗口,在窗口上添加3D坐标轴,显示成下图: 123456import numpy as npimport matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3Dfig = plt.figure()ax = Axes3D(fig) 接下来给进 X 和 Y 值,并将 X 和 Y 编织成栅格。每一个(X, Y)点对应的高度值我们用下面这个函数来计算: 1234567# X, Y valueX = np.arange(-4, 4, 0.25)Y = np.arange(-4, 4, 0.25)X, Y = np.mesh...




