
11机器学习系统设计
垃圾邮件分类系统
误差分析
机器学习实现的步骤
- 用最简单的算法快速实现机器学习过程。然后通过交叉验证数据集对模型进行测试。
- 画出学习曲线,通过检验误差,找出算法存在的高偏差、高方差问题。决定是否使用更多的数据和更多的特征。(不要过早的选择模型进行优化,应该首先对数据的特征进行分析。)
- 误差分析。通过分析错误数据,找到错误的原因,然后对机器学习算法进行改进。
- 数值估计。可以有效的改进机器学习算法。数值评估指标,来改进算法执行的效果。对数据进行特殊处理,例如只取邮件单词向量中单词前五个字母来训练数据。使用交叉验证错误率,来判断是否采取某项特殊处理。尝试各种不同的对算法的改进,然后使用交叉验证的方法,分析错误率的变化。
词干提取算法。
对算法的选择和改进
- 算法评估
- 误差分析
不对称分类的误差评估
偏斜类
- 一个类别中的数据与另外一个类别中的数据量相差很大。
- 使用不同的方法,衡量偏斜类分类问题的准确率。
查准率和召回率
- 查准率:预测真实真值/预测真值。
- 召回率:预测真实真值/真实真值
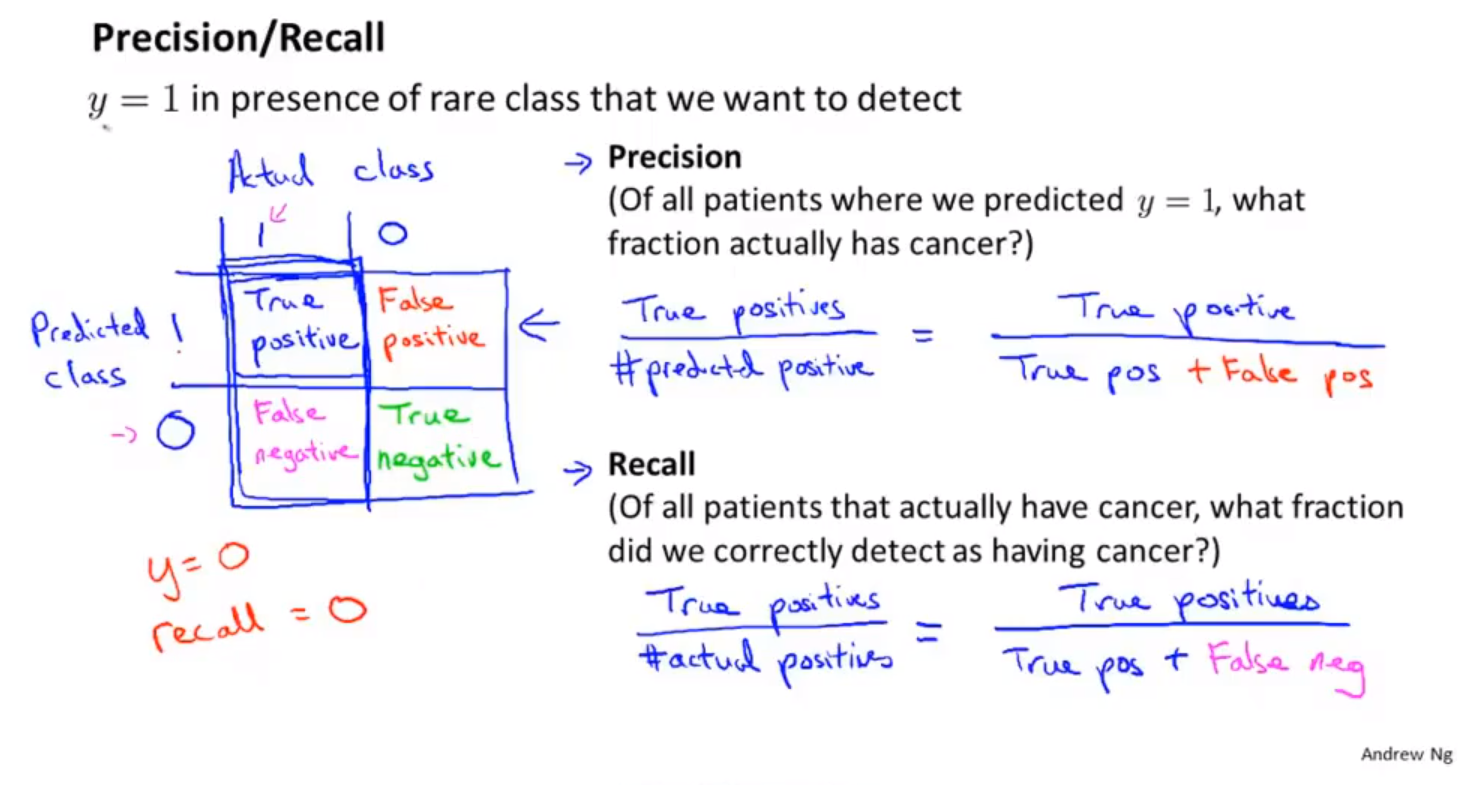
在数理统计中使用第一类错误和第二类错误来描述查准率和召回率。只有增加样本的数量才会同时降低第一类错误和第二类错误犯错的概率。
- 第一类错误,错误的拒绝,对应召回率。真实真值中,被拒绝的真值概率,是犯第一类错误的概率。
- 第二类错误,错误的接受,对应查准率。预测真值中,被接受的假值概率,是犯第二类错误的概率。
很多地方都可以使用数理统计中的相关知识,对模型的好坏进行评估。概率论与数理统计,本质上就是通过样本来评估总体的特征,与机器学习非常像,但是是通过统计学的方法实现了对总体特征的描述。
查准率和召回率的权衡
F值来决定选择哪一个模型
$$
F = 2\frac{PR}{P+R}
$$
训练数据
- 大量数据能够有效的改善模型的准确度。
- 设计有大量隐藏层单元的神经网络(能够拟合十分复杂的模型,模型本身的偏差较小),然后用大量数据进行训练拟合。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐
2023-08-16
03 Kubebuilder
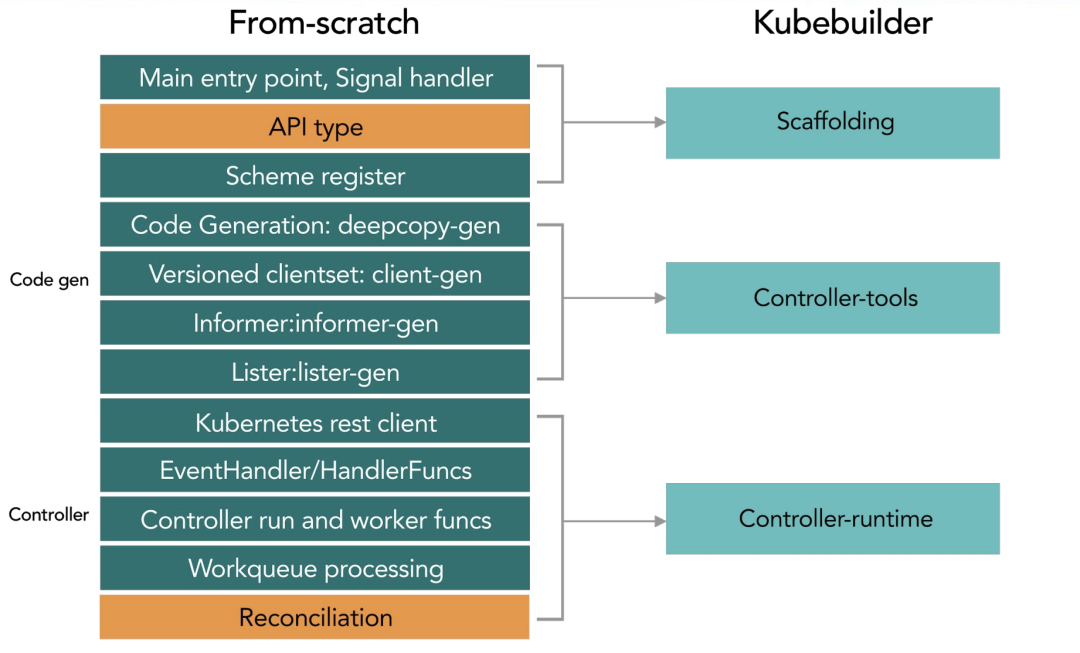
1 概述构建阶段 工作流程 2 使用流程安装kubebuilder12brew install kubebuilderkubebuilder version 创建工程 初始化一个项目目录 123mkdir -p $GOPATH/src/ykl.com/customer-controller/go mod init contollers.happyhacker.io 定义crd所属的domain,生成一个工程.定义 crd 所属的 domain,这个指令会帮助你生成一个工程。 1kubebuilder init --domain estom.com --license apache2 --owner "Estom" 创建后的目录结构如下: cmd目录下是启动脚本,编译后会在bin目录下生成manage可执行文件 config目录下是基础工程配置。 1234567891011121314151617181920212223242526272829303132.├── Dockerfile├── Makefile├── PROJECT├── READ...
2021-03-22
41 单机模型并行
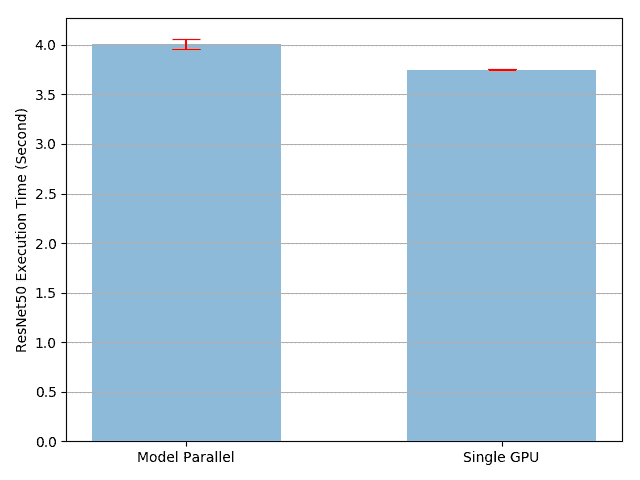
单机模型并行最佳实践 原文:https://pytorch.org/tutorials/intermediate/model_parallel_tutorial.html 作者:Shen Li 模型并行在分布式训练技术中被广泛使用。 先前的帖子已经解释了如何使用DataParallel在多个 GPU 上训练神经网络; 此功能将相同的模型复制到所有 GPU,其中每个 GPU 消耗输入数据的不同分区。 尽管它可以极大地加快训练过程,但不适用于模型太大而无法容纳单个 GPU 的某些用例。 这篇文章展示了如何通过使用模型并行解决该问题,与DataParallel相比,该模型将单个模型拆分到不同的 GPU 上,而不是在每个 GPU 上复制整个模型(具体来说, 假设模型m包含 10 层:使用DataParallel时,每个 GPU 都具有这 10 层中的每一个的副本,而当在两个 GPU 上并行使用模型时,每个 GPU 可以承载 5 层。 模型并行化的高级思想是将模型的不同子网放置在不同的设备上,并相应地实现forward方法以在设备之间移动中间输出。 由于模型的一部分仅在任何单个设备上运行...

2020-09-26
lasso_demo
套索演示演示如何使用套索选择一组点并获取所选点的索引。回调用于更改所选点的颜色。 这是一个概念验证实现(尽管它可以按原样使用)。将对API进行一些改进。 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677from matplotlib import colors as mcolors, pathfrom matplotlib.collections import RegularPolyCollectionimport matplotlib.pyplot as pltfrom matplotlib.widgets import Lassoimport numpy as npclass Datum(object): colorin = mcolors.to_rgba("red") colorout = mcolor...
2021-09-02
14 Redis使用场景
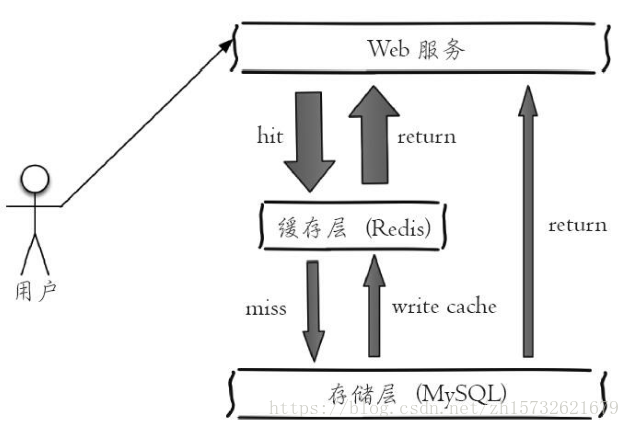
https://blog.csdn.net/zh15732621679/article/details/80614091 1 Redis使用场景计数器可以对 String 进行自增自减运算,从而实现计数器功能。 Redis 这种内存型数据库的读写性能非常高,很适合存储频繁读写的计数量。 缓存将热点数据放到内存中,设置内存的最大使用量以及淘汰策略来保证缓存的命中率。 查找表例如 DNS 记录就很适合使用 Redis 进行存储。 查找表和缓存类似,也是利用了 Redis 快速的查找特性。但是查找表的内容不能失效,而缓存的内容可以失效,因为缓存不作为可靠的数据来源。 消息队列List 是一个双向链表,可以通过 lpush 和 rpop 写入和读取消息 不过最好使用 Kafka、RabbitMQ等消息中间件。 会话缓存可以使用 Redis 来统一存储多台应用服务器的会话信息。 当应用服务器不再存储用户的会话信息,也就不再具有状态,一个用户可以请求任意一个应用服务器,从而更容易实现高可用性以及可伸缩性。 分布式锁实现在分布式场景下,无法使用单机环境下的锁来对多个节点上的进程进行同步。 ...
2022-10-08
02 AOP
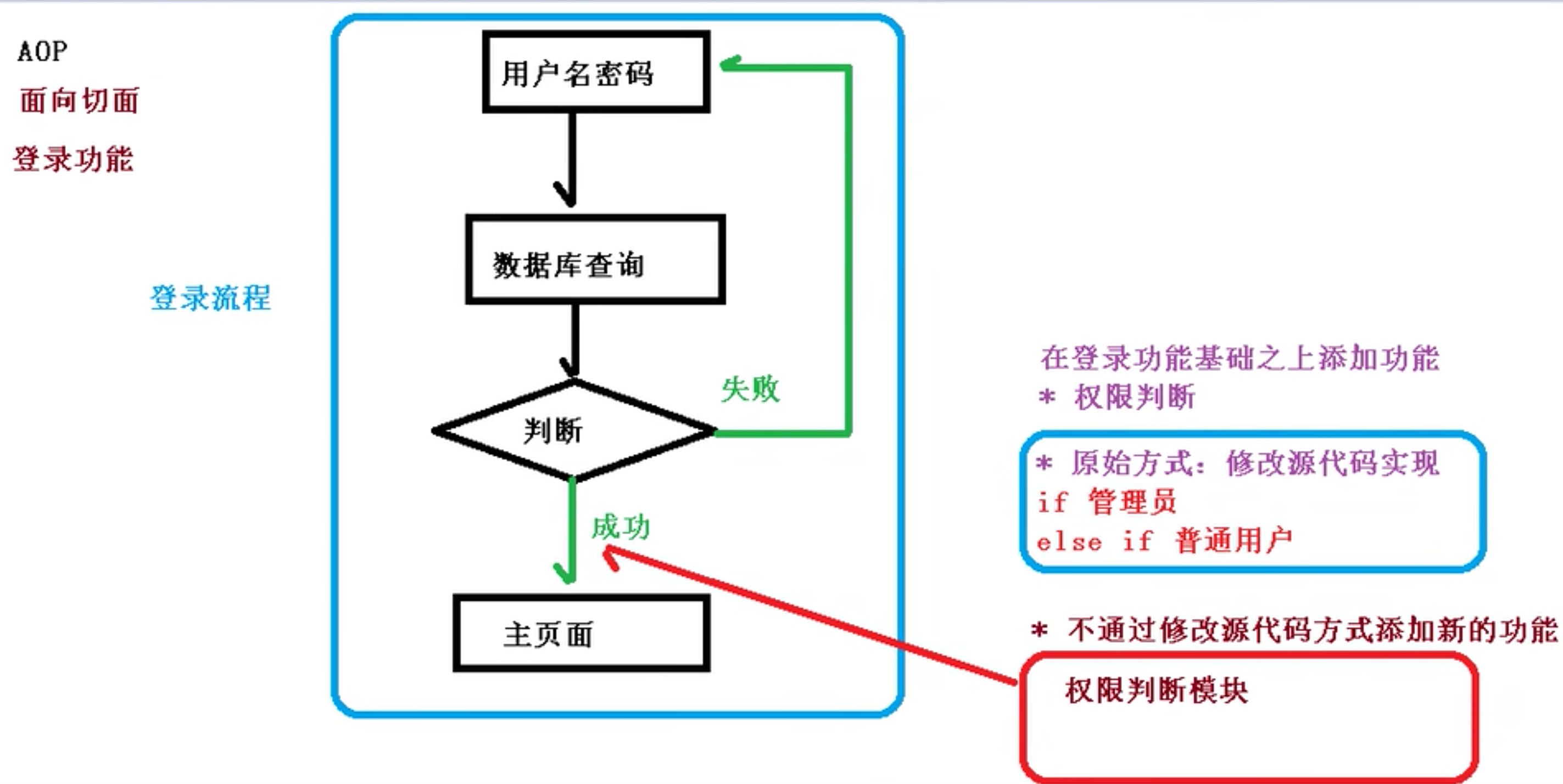
1 AOP基本概念概念面向切面编程Aspect Oriented Programming 通过 预编译方式 和 运行期间动态代理 实现程序功能的统一维护的一种技术。 AOP是OOP(面相对象编程)的延续。是函数式编程的一种衍生泛型。 利用AOP可以对业务逻辑的各个部分进行隔离。降低耦合度、提高可用性、提高开发效率 主要功能将日志记录、性能统计、安全控制、事务处理、异常处理等代码从业务逻辑代码中划分出来。 通俗描述:不通过修改源代码的方法,在主干功能里添加新功能 2 AOP底层原理动态代理的原理AOP使用动态代理实现面向切面编程 有接口情况,使用JDK动态代理 设计模式:代理模式。创建接口实现类代理对象,增强类的方法。 没有接口情况,使用CGLIB实现动态代理 创建子类继承原来的类。 创建当前类子类的代理对象,增强类中的方法。 动态代理的实现 JDK 动态代理的实现。使用java.lang.reflect.Proxy,通过反射原理实现动态代理。 第一个参数:类加载器 第二个参数:被代理的接口 第三个参数:增强方法的逻辑,实现接口 12static O...

2021-09-02
03-日志记录
概述上篇文章分享了 Gin 框架的路由配置,这篇文章分享日志记录。 查了很多资料,Go 的日志记录用的最多的还是 github.com/sirupsen/logrus。 Logrus is a structured logger for Go (golang), completely API compatible with the standard library logger. Gin 框架的日志默认只会在控制台输出,咱们利用 Logrus 封装一个中间件,将日志记录到文件中。 这篇文章就是学习和使用 Logrus 。 日志格式比如,我们约定日志格式为 Text,包含字段如下: 请求时间、日志级别、状态码、执行时间、请求IP、请求方式、请求路由。 接下来,咱们利用 Logrus 实现它。 Logrus 使用用 dep 方式进行安装。 在 Gopkg.toml 文件新增: 123[[constraint]] name = "github.com/sirupsen/logrus" version = "1.4.2" 在项目中导入: ...




