
13聚类算法kmeans
无监督学习
- 数据集只给出了特征没有给出标签
- 找到隐含在数据中的结构
聚类算法的用途
- 市场分割
- 社交网络分析
- 组织计算簇
- 了解银河系的构成
kmeans聚簇
- 簇分配
- 移动聚类中心,到簇均值处(此时簇代价函数最小)
kmeans算法的步骤

优化目标
- kmeans的代价函数

$c^{(i)}$,第i个样本所属的簇
$u_k$,第k簇的簇均值
$u_{c^{(i)}}$,第i个样本所属的簇的簇均值
代价函数:所有样本到簇中心的距离均值。
$$
J = \frac{1}{m}\sum_i^m||x^{(i)}-\mu_{c^{(i)}}||^2\
min J
$$
随机初始化
学习课程的算法演示,全部可以是自己构造的合适的数据,进行算法流程的模拟训练。具体的机器学习算法实践,专门开一个部分吧。
- 多次随机初始化,多次运行kmeans算法
- 对多次运行结果的聚类中心和代价函数进行保留,对比选取最小的结果。
聚类的数量
- 一般画出聚类样本的散点分布图,然后通过观察,手动决定聚类的数量。
- 肘部法则:尝试不同的K值,代价函数的变化,选取代价函数趋于平缓前的K值。
- 哪个聚类的数量能够更好的应用于后续目的。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐
2020-10-14
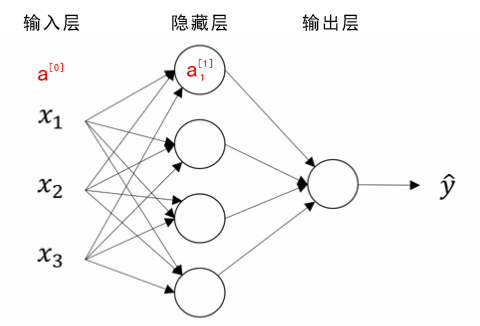
02浅层神经网络
浅层神经网络 ReLU,recfied linear unit修正线性单元 神经网络表示 竖向堆叠起来的输入特征被称作神经网络的输入层(the input layer)。 神经网络的 隐藏层(a hidden layer) 。“隐藏”的含义是 在训练集中 ,这些中间节点的真正数值是无法看到的。 输出层(the output layer) 负责输出预测值。 下图被称为双层神经网络。包括隐藏层和输出层,一般不考虑输入层。 如图是一个双层神经网络,也称作单隐层神经网络(a single hidden layer neural network)。当我们计算网络的层数时,通常不考虑输入层,因此图中隐藏层是第一层,输出层是第二层。 约定俗成的符号表示: $x$表示其中一个样本。$a^{0}$第一个样本输入层的激活值。$a^{1}$第一个样本隐藏层产生激活值。 $n^{[i]}$表示第i层的单元数量。 $z=W^T * a+b$,$x$表示单个样本,$z$表示求和值,$W$权重,$a$上一层产生的激活值,$b$偏置单元。 $Z=W^T * A+b$,样本向...

2021-06-16
5 多人协作
5 多人协作通过远程库的push和pull操作实现夺人合作 推送分支或分支内容 当从远程库进行克隆的时候,实际上已经将本地master分支和远程的master分支进行乐关联。 1git remote [-v] 可以显示与远程库关联的信息 1git push origin master 推送分支,吧分支上的所有本地内容提交到远程库中的相同分支当中。 哪些分支需要推送 mater分支是主分支,需要实时推送 dev是开发分支,所有成员都要在上面工作。也需要与远程同步。 bug分支只需要在本地修复bug,没有必要推送到远程。 feature分支,可以不用推送到远程。单人开发不用,夺人开发要推送到远程。 抓取分支或者分支的内容1git checkout -b dev origin/dev 可以用来抓取远程分支dev,这样会建立一个本地的本地的dev分支与远程的dev分支进行关联,可以直接实现dev分支的控制(push) 1git pull \<remote\> \<branch\> 如果Git push失败,说明,当前的版本不是最新的版本。git pull可...

2021-09-02
06-统一定义 API 错误码
改之前在使用 gin 开发接口的时候,返回接口数据是这样写的。 123456789101112type response struct { Code int `json:"code"` Msg string `json:"msg"` Data interface{} `json:"data"`}// always return http.StatusOKc.JSON(http.StatusOK, response{ Code: 20101, Msg: "用户手机号不合法", Data: nil,}) 这种写法 code、msg 都是在哪需要返回在哪定义,没有进行统一管理。 改之后12345// 比如,返回“用户手机号不合法”错误c.JSON(http.StatusOK, errno.ErrUserPhone.WithID(c.GetString("trace-id")))// 正确返回c.J...

2019-09-28
第4节 抽样分布
抽样分布 目的是为了求统计量的分布。(概率分布,分布律,概率密度) 定义:抽样分布统计量的分布为抽样分布。及对样本的统计量的分布进行研究,然后反应总体的概率分布。 1 特征函数 样本的统计量的本质理解,这里都是将多个随机变量,按照某种方式,进行运算,得到一个唯一的统计量。 这个运算过程中可能伴随着其他参数,形成统计函数簇。这里的特征函数$\Gamma$函数都是添加一个特征参数,形成统计函数簇,描述原来样本某个方面的特点。 这里不能用总体分布簇来理解。 定义1:特征函数X是随机变量$e^{-itX}$数学期望为X的分布的特征函数。$$\varphi_X(t)=E(e^{itX})=Ecos(tX)+iEsin(tX)\连续型:\varphi_X(t) =E(e^{itX})= \int_{-\infin}^{+\infin}f(x)e^{itx}dx \离散型:\varphi_X(t) =E(e^{itX})= \sum_kp_ke^{(itx_k)}$$ 公式:常见分布的特征函数 二项分布$B(n,p)$的特...
2022-10-08
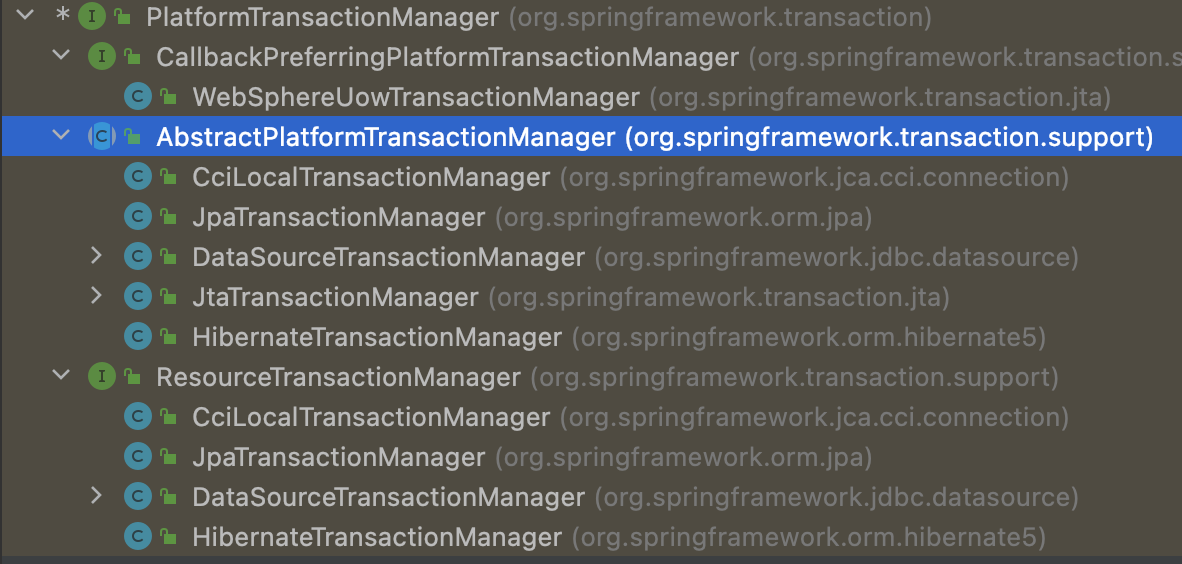
04 事务
事务1 简介事务概念事务是数据库操作最近本的单元,逻辑上一组操作,要么都成功,如果有一个失败,所有的都失败。 事务有四大特性ACID 原子性,不可分割 一致性,多个事务看到的数据是一致的 隔离性,多个事务不会产生影响 持久性,可以持久化 准备环境 创建service和dao层的bean(设计代码架构) 实现转账的业务逻辑(开发业务逻辑) 撰写测试用例进行测试(测试代码) 2 事务步骤操作步骤 开启事务操作 进行业务操作,并添加异常处理 没有发生异常,提交事务。 第四部 出现异常事务回滚 Spring事务管理介绍 事务添加到三层结构的service层 在spring进行事务管理操作 声明式事务管理。通过配置实现。 编程式事务管理。需要写代码 生命式事务管理 注解方式 xml配置文件方式 在Spring进行声明式事务管理,底层使用AOP 提供一个接口,代表事务管理。针对不同的框架提供了不同的实现类。 事务管理器 3 基于注解的声明式事务管理步骤 配置事务管理器 12345678910111213141516```2. 在Spring配置文件中开启事...
2021-03-09
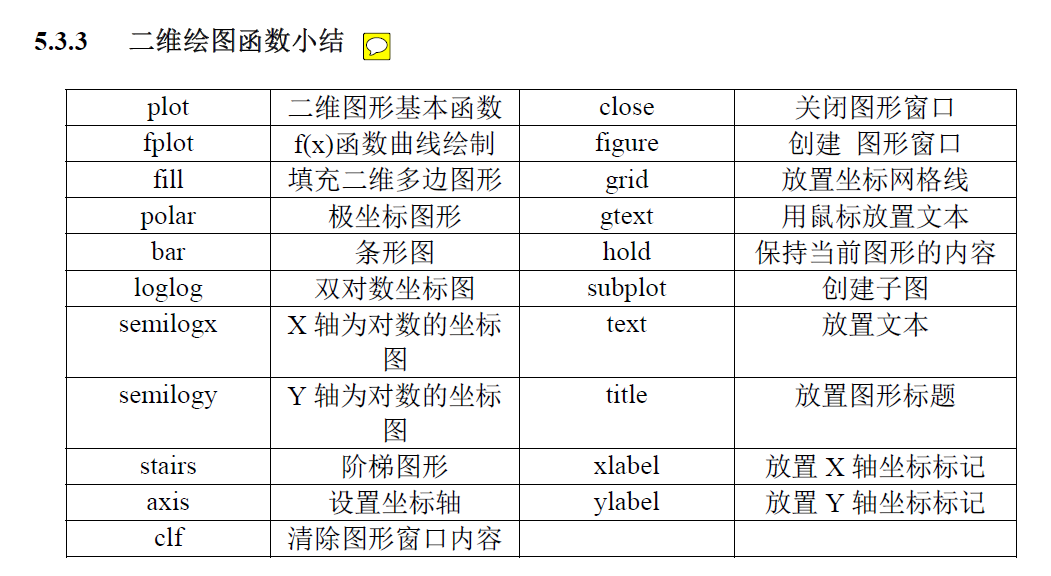
绘图功能
MATLAB中的绘图功能 >二维高层绘图的基本函数 plot函数 plot(x,y); x和y为相同长度的向量 如果plot为单个参数,绘制折现图,横坐标为自然数。如果参数为复数,则实轴和虚轴进行绘制。(可以绘制圆) 如果绘制过程中,自变量为向量,因变量为矩阵,则对矩阵的每一个列向量,绘制一个关于自变量的图像。也就是说,如果想要在同一图中绘制函数,不需要写多个plot,只需要将因变量转换为矩阵就好。 如果绘制过程中,自变量和因变量同为高阶矩阵,则会为x的每一列为自变量,y的每一列为因变量,绘图。 注意行向量的能够组合成行向量矩阵,列项量能组合成列项量矩阵。 linespace()和冒号表达式均可以产生行向量 >二维高层绘图辅助操作 涉及到的函数、控制或者命令 这里有一张图片 标注 坐标轴控制 这里有一张图片 图形名称 曲线名称 图例 图形保持 窗口分割 这里有一张图片 可以使用latex字符进行控制 xlim([xmin,xmax]) ylim([ymin,ymax]) axis([xmin,xma...




