
14主成分分析
降维-数据压缩
- 将两个具有强相关的维度,压缩到一个维度
- 方便计算
- 节约空间
- 学习算法运行更快
降维-数据可视化
- 选取具有代表性的两个维度来表示数据。
- 因为数据之间存在内在关联性。GDP的例子中,国家GDP低,人均GDP低的地方,医疗健康水平等其他指数也会很低。
主成分分析问题规划-目标
- 本质:找到一个低维度的面,然后将数据投影到上面,使得投影误差最小(在其他方向损失的数据信息最少。)
- 均值归一化
- 特征规范化
对数据进行缩放,避免因为数据本身的尺度不同造成对结果的影响不同。
主成分分析问题规划2
- 从线性空间的角度进行理解。当有n个特征的时候,可以用n个线性无关向量作为基,表示线性空间。如果这n个特征之间存在关系(线性相关性)那么可以用其他的特征来表示这个特征,那么就可以用n-1个向量作为基表示现行空间。
- 从向量空间的角度进行理解,主成分分析,即将n为空间内的点,投影到k维子空间当中,实现降维。
- 主成分分析即将n个特征之间的线性相关性进行判定。转换为互相独立的基,消除特征之间的线性相关性。如果n个特征之间存在线性相关,那么主成分分析的特征向量是n-1个,特征值也是n-1个,其他的特征值为0。
- 在编程语言中的实现过程如下
- 对样本进行奇异值分析。得到k个特征向量构成的特征矩阵。
- 使用特征矩阵对每一个样本进行线性变换。(投影、降维、主成分)
- 使用降维后的数据代入样本进行计算。
$$
SIGMA = \frac{1}{M}\sum_1^m x^{(i)}x^{(i)T} ; n\times n \
[U,S,V]=svd(SIGMA)\
k_{feature} = U(:,1:k)\
k_{main} = k_{feature}^T*x
$$
协方差表示两个随机变量进行线性运算时的相关性大小。
选取主成分的个数
- 通过特征值累计,占比例
$$
main = \frac{\sum_{i=1}^k s_{ii}}{\sum_{i=1}^n s_{ii}}
$$
压缩重现
- 从低维度的向量通过特征向量矩阵,还原回原来的向量。进行反向的现行变换。
PCA算法的应用
- 首先通过主成分分析,对数据降维。
- 然后通过特征向量矩阵对数据进行映射,形成新的数据。
- 最后运行机器学习算法,提高算法的效率。
主要应用
- 数据压缩
- 数据可视化,可以将数据压缩到两维或者3维,对数据进行可视化,然后分析数据的特征。
- 通过PCA降低特征数,防止过拟合的方式很愚蠢。PCA降低特征数的原理本质上是减少特征之前的现行相关性,添加新的多项式特征的原理,本质上是增加特征之间的现行相关性。这样相互冲突的操作是多余的。
编程任务
- 使用python完成主成分分析过程,观察分析的结果。对主城分析的结果进行分析。结合概率论和数理统计的内容,判断前k个特征向量,占主成分的多少。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2021-12-24
man
man查看Linux中的指令帮助 补充说明man命令 是Linux下的帮助指令,通过man指令可以查看Linux中的指令帮助、配置文件帮助和编程帮助等信息。 语法1man(选项)(参数) 选项1234-a:在所有的man帮助手册中搜索;-f:等价于whatis指令,显示给定关键字的简短描述信息;-P:指定内容时使用分页程序;-M:指定man手册搜索的路径。 参数 数字:指定从哪本man手册中搜索帮助; 关键字:指定要搜索帮助的关键字。 数字代表内容1234567891:用户在shell环境可操作的命令或执行文件;2:系统内核可调用的函数与工具等3:一些常用的函数(function)与函数库(library),大部分为C的函数库(libc)4:设备文件说明,通常在/dev下的文件5:配置文件或某些文件格式6:游戏(games)7:惯例与协议等,如Linux文件系统,网络协议,ASCII code等说明8:系统管理员可用的管理命令9:跟kernel有关的文件 实例我们输入man ls,它会在最左上角显示“LS(1)”,在这里,“LS”表示手册名称,而“(1)”表示该手册位于第...
2021-03-09
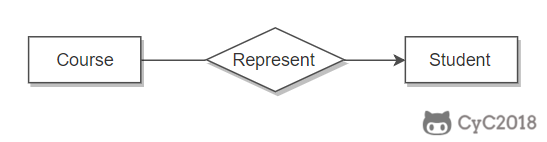
设计篇——2.设计步骤
设计篇——设计步骤1 ER 图定义Entity-Relationship,有三个组成部分:实体、属性、联系。 用来进行关系型数据库系统的概念设计。 实体的三种联系包含一对一,一对多,多对多三种。 如果 A 到 B 是一对多关系,那么画个带箭头的线段指向 B; 如果是一对一,画两个带箭头的线段; 如果是多对多,画两个不带箭头的线段。 下图的 Course 和 Student 是一对多的关系。 表示出现多次的关系一个实体在联系出现几次,就要用几条线连接。 下图表示一个课程的先修关系,先修关系出现两个 Course 实体,第一个是先修课程,后一个是后修课程,因此需要用两条线来表示这种关系。 联系的多向性虽然老师可以开设多门课,并且可以教授多名学生,但是对于特定的学生和课程,只有一个老师教授,这就构成了一个三元联系。 表示子类用一个三角形和两条线来连接类和子类,与子类有关的属性和联系都连到子类上,而与父类和子类都有关的连到父类上。

2020-07-21
10 chrome控制台
Elements渲染完成的页面布局。包括HTML元素和布局分析。 Consolejavascript控制台。可以对网页进行操作。可以模拟客户端对服务器发送请求。 通过js向服务器发送请求,可以跳过前端js对请求数据的验证。 Source从服务器端下载的所有文件。包括JS、CSS、HTML以及各种依赖。 Network记录了请求的过程。包括所有类型的Request和Response以及其相关分析。 Application主要是应用数据分析。包括储存在本地Chrome自带数据库中的各种数据。本地缓存、cookies、session
2021-03-13
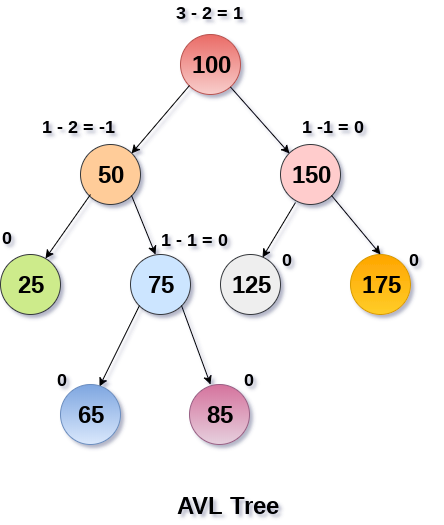
6.3 平衡二叉树
平衡二叉树 树>二叉树>二叉搜索树>二叉平衡树 参考文献 AVL 1 简介概念 满足二叉搜索树的定义 所有结点的平衡因子的绝对值都不超过1,即平衡因子只能是1,0,-1三个值。 如果任何节点的平衡因子为1,则意味着左子树比右子树高一级。 如果任何节点的平衡因子为0,则意味着左子树和右子树包含相等的高度。 如果任何节点的平衡因子是-1,则意味着左子树比右子树低一级。 1平衡系数=左子树的高度 - 右子树的高度 复杂性 算法 平均情况 最坏情况 空间 o(n) o(n) 搜索 o(log n) o(log n) 插入 o(log n) o(log n) 删除 o(log n) o(log n) 优势 AVL树能防止二叉树偏斜,控制二叉搜索树的高度。高度为h的二叉搜索树中的所有操作所花费的时间是O(h)。 如果普通二叉搜索树变得偏斜(即最坏的情况),它可以扩展到O(n)。 通过将该高度限制为log n,AVL树将每个操作的上限强加为O(log n),其中n是节点的数量 2 操作基本操作 创建 遍历(同上) 插入 删除 ...

2021-03-20
SUMMARY
Sklearn 与 TensorFlow 机器学习实用指南第二版 零、前言 一、机器学习概览 二、端到端的机器学习项目 三、分类 四、训练模型 五、支持向量机 六、决策树 七、集成学习和随机森林 八、降维 十、使用 Keras 搭建人工神经网络 十一、训练深度神经网络 十二、使用 TensorFlow 自定义模型并训练 十三、使用 TensorFlow 加载和预处理数据 十四、使用卷积神经网络实现深度计算机视觉 十五、使用 RNN 和 CNN 处理序列 十六、使用 RNN 和注意力机制进行自然语言处理 十七、使用自编码器和 GAN 做表征学习和生成式学习 十八、强化学习 十九、规模化训练和部署 TensorFlow 模型

2020-09-29
083D与动画
3D与动画基本方法本章知识点归纳如下: 创建3D图:ax = Axes3D(fig) 画出3D图:ax.plot_surface() 投影:ax.contourf() 动画:animation.FuncAnimation() 3D作图首先在进行 3D Plot 时除了导入 matplotlib ,还要额外添加一个模块,即 Axes 3D 3D 坐标轴显示,并且之后要先定义一个图像窗口,在窗口上添加3D坐标轴,显示成下图: 123456import numpy as npimport matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3Dfig = plt.figure()ax = Axes3D(fig) 接下来给进 X 和 Y 值,并将 X 和 Y 编织成栅格。每一个(X, Y)点对应的高度值我们用下面这个函数来计算: 1234567# X, Y valueX = np.arange(-4, 4, 0.25)Y = np.arange(-4, 4, 0.25)X, Y = np.mesh...




