
17大数据集
大数据集
大数据集机器学习
- 通过大量数据,能够减少数据方差带来的模型误差。但不能解决模型偏差带来的模型误差。(有待考虑)
随机梯度下降算法
- 数据集很大的时候,普通梯度下降会变得困难。使用随机梯度下降,能够解决数据集过大的现象。
- batch梯度下降。一次对所有的数据进行梯度下降。
- 随机梯度下降;stochastic gradient descent
- random shuffle example
- repeat gradient descent on one example
两种梯度下降算法对比
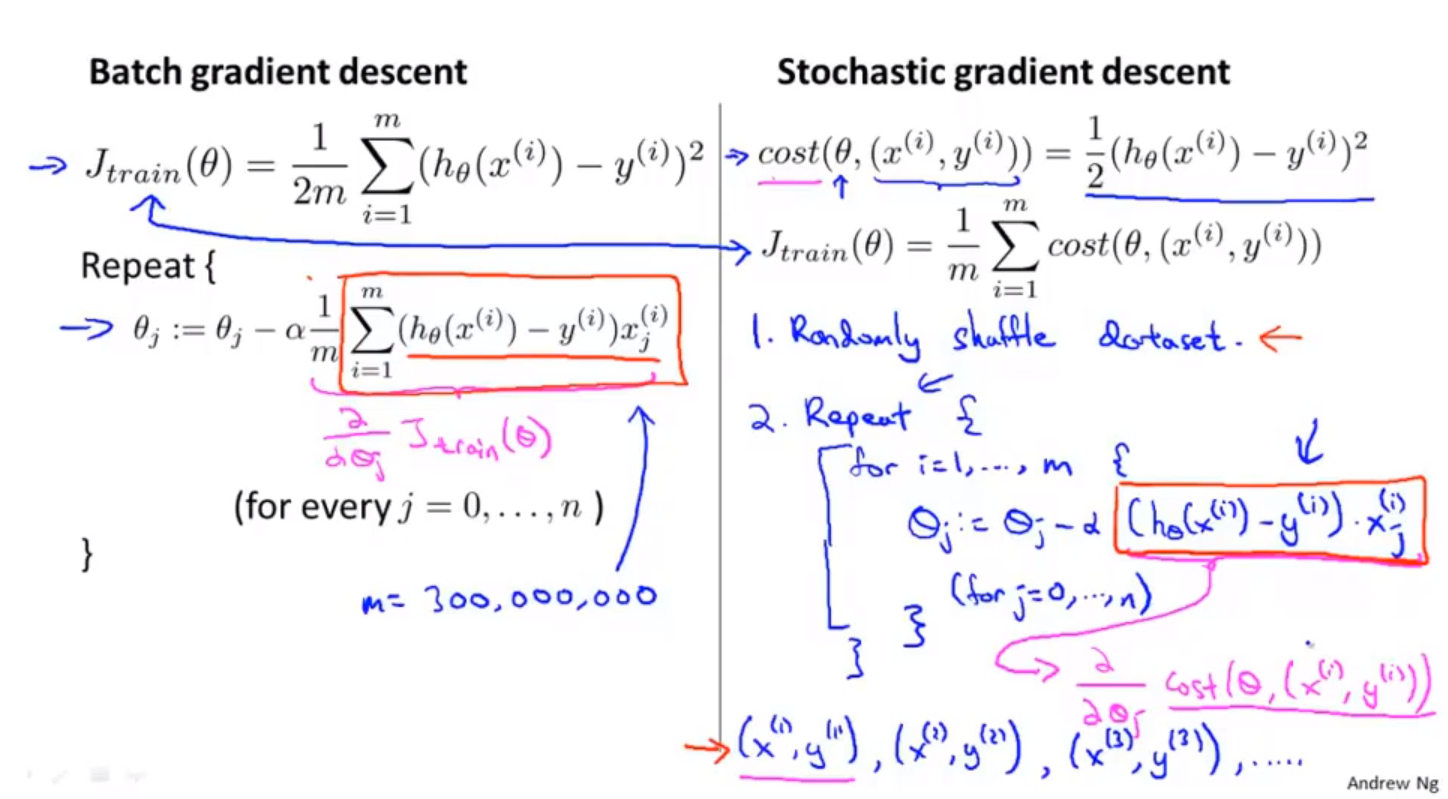
随机梯度下降算法过程
mini-batch 梯度下降算法
- 选取少量样本进行梯度下降。
- 需要有非常高效的向量化方法,对小范围内的数据进行求和运算

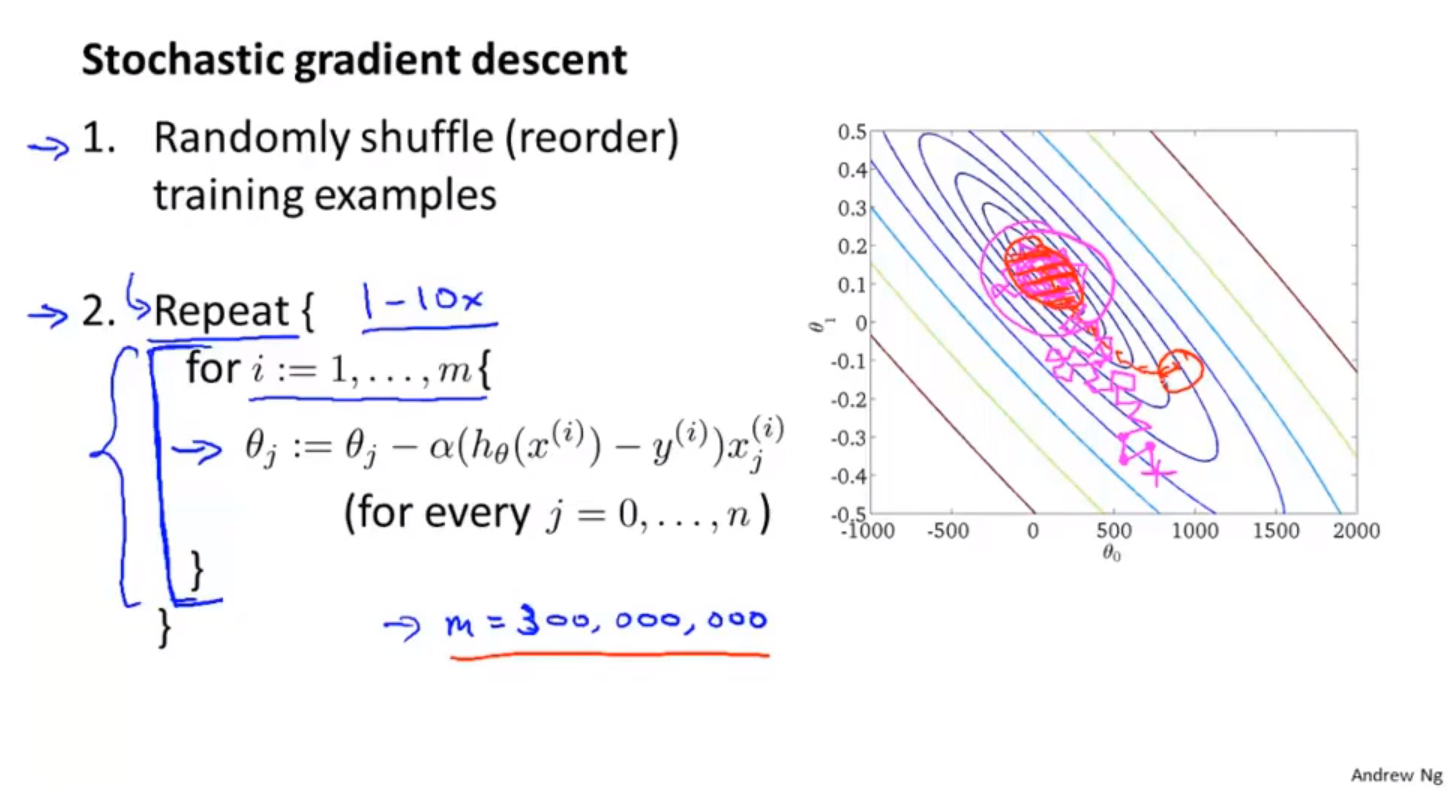
随机梯度下降的收敛问题
- 学习率一般是固定的参数,如果想让代价函数收敛在更小的位置,可以随着训练过程降低学习率。
- 保持固定的学习率能够方便调试。
在线机器学习
针对不断增加的连续的数据流。不断增加数据的网站,连续的数据流==> 在线机器学习。一边学习一边使用。
邮寄包裹的例子:用户的统计学特征、发货地、目的地、给出的价格、用户选择还是离开。根据以上特征,训练处,什么时候用户留下,什么时候用户离开,并给出推荐的结果。
一般使用逻辑回归的方式,判定给定价格下用户留下的概率,或者在一定概率下,用户留下的价格。
在线机器学习的优点:能够使用不断变化的用户偏好。
点击率预测学习。用户特征(搜索关键词)—-手机特征,用户是否点击,建立用户特征和手机特征之间的匹配关系。
与随机梯度下降非常相似,不同点在于,随机梯度下降,会使用固定的数据集,在线机器学习,使用不断变化的数据集。
map-reduce算法
- map-reduce思想
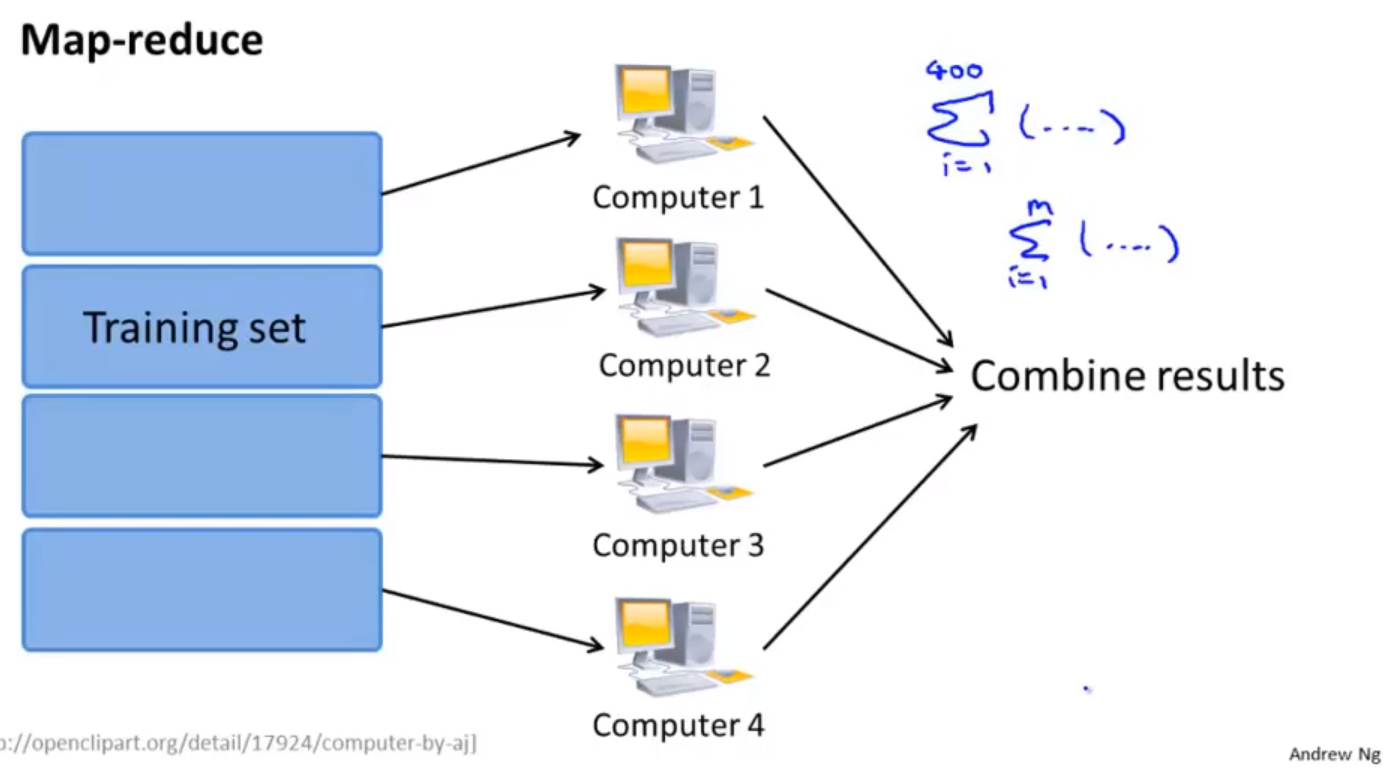
- map-reduce 过程,可以处理$\Sigma$累加的部分,通过reduce过程,对计算结果累计。必要条件:算法能够表示成对训练集的一种求和
- 可以在单个机器的不同核心上执行map-reduce的过程
- 某些现行代数库在进行向量化运算的过程中,会通过多个核心进行优化,不必使用MapReduce
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐
2021-03-20
7
七、集成学习和随机森林 译者:@friedhelm739 校对者:@飞龙、@PeterHo、@yanmengk、@XinQiu、@YuWang 假设你去随机问很多人一个很复杂的问题,然后把它们的答案合并起来。通常情况下你会发现这个合并的答案比一个专家的答案要好。这就叫做群体智慧。同样的,如果你合并了一组分类器的预测(像分类或者回归),你也会得到一个比单一分类器更好的预测结果。这一组分类器就叫做集成;因此,这个技术就叫做集成学习,一个集成学习算法就叫做集成方法。 例如,你可以训练一组决策树分类器,每一个都在一个随机的训练集上。为了去做预测,你必须得到所有单一树的预测值,然后通过投票(例如第六章的练习)来预测类别。例如一种决策树的集成就叫做随机森林,它除了简单之外也是现今存在的最强大的机器学习算法之一。 向我们在第二章讨论的一样,我们会在一个项目快结束的时候使用集成算法,一旦你建立了一些好的分类器,就把他们合并为一个更好的分类器。事实上,在机器学习竞赛中获得胜利的算法经常会包含一些集成方法。 在本章中我们会讨论一下特别著名的集成方法,包括 bagging, boosting, s...

2021-12-24
blkid
blkid查看块设备的文件系统类型、LABEL、UUID等信息 补充说明在Linux下可以使用 blkid命令 对查询设备上所采用文件系统类型进行查询。blkid主要用来对系统的块设备(包括交换分区)所使用的文件系统类型、LABEL、UUID等信息进行查询。要使用这个命令必须安装e2fsprogs软件包。 语法1234blkid -L | -Ublkid [-c ] [-ghlLv] [-o] [-s ][-t ] -[w ] [ ...]blkid -p [-s ] [-O ] [-S ][-o] ...blkid -i [-s ] [-o] ... 选项123456789101112131415161718192021-c <file> # 指定cache文件(default: /etc/blkid.tab, /dev/null = none)-d # don't encode non-printing characters-h # 显示帮助信息-g # garbage collect the ...
2021-03-09
Django——关于URL分组匹配问题
**基本原则说明:** - Django会一次匹配列表中的每个URL模式,在遇到第一个请求的URL相匹配的模式时停下来 - 分组传参包括以下内容: - 一个HttpRequest实例。 - 如果正则表达式是无名组,那么正则表达式所匹配的内容将作为位置参数提供给视图。 - 如果正则表达式是命名组,那么正则表达式所匹配的内容将作为关键参数提供给视图。 - 对于GET、POST请求本身的参数不进行匹配。作为扩展参数kwargs提供给视图。 - 如果请求的URL没有匹配到任何一个正则表达式,或者匹配过程中抛出异常,会进行相应的错误处理。 分组参数 关键参数 **匹配分组算法说明:** \> 分组对应参数,是如何传递参数的过程;匹配分组算法,是如何匹配字符串的过程。 - 如果有命名参数,则使用命名参数,忽略非命名参数。 - 否则,将以位置参数传递所有的非命名参数。 - 所有的匹配结果都是字符串 能够通过url函数额外传递多个参数。 终于他妈的明白这种关键参数和位置参数的意思了: 关键...
2021-06-15
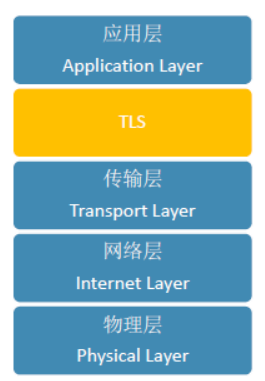
2 TLS加密协议
1 基本概念协议简介SSL/TLS是一种密码通信框架,他是世界上使用最广泛的密码通信方法。SSL/TLS综合运用了密码学中的对称密码,消息认证码,公钥密码,数字签名,伪随机数生成器等,可以说是密码学中的集大成者。 SSL(Secure Socket Layer)安全套接层,是1994年由Netscape公司设计的一套协议,并与1995年发布了3.0版本。 TLS(Transport Layer Security)传输层安全是IETF在SSL3.0基础上设计的协议,实际上相当于SSL的后续版本。 加密算法包括秘钥生成、加密、解密三个主要过程。 非对称加密算法:RSA,DSA/DSS,Diffie–Hellman。协商对称加密的共享密钥。(也称为主密钥或者会话密钥) 对称加密算法:AES,RC4,3DES。用来加密数据 秘钥生成算法:premaster secret、master secret 消息摘要算法消息摘要算法即HASH算法,消息摘要(Message Digest)简要地描述了一分较长的信息或文件,它可以被看做一分长文件的数字指纹。主要分...

2020-10-09
08神经网络原理
非线性假设 当特征很多时,如果包含各种高阶项,特征空间会爆炸。 在非线性空间中,使用逻辑回归进行分类,会导致特征空间过多。 神经网络相关术语 input layer输入层 output layer输出层 bias unit 偏置单元 sigmod、logistic activation function激活函数 $\theta$模型参数=模型权重 模型展示 神经网络本身是机器学习的一个假设函数。 使用数学计算能够表示神经网络的计算过程。即计算给定输入后,计算神经网络的输出值。 使用向量化的计算方法,计算神经网络的前向传播过程。 实例 使用神经网络表示逻辑运算。 sigmod算子。+-10,+-20 计算向量化 普通计算向量化 多组数据矩阵化 使用向量,来表示计算过程。使用矩阵来表示多组数据的计算过程。 在线性回归和逻辑回归当中,多组输入向量,乘,固定的参数向量,等于,输出向量。 在神经网络中,一组输入向量,乘,多组参数向量,等于,输出向量。 下标用来表示矩阵和向量中的元素位置。上标表示迭代的代数。 编程任务:使用神经网络进行多元分类 寻找图片的数据集...

2022-10-09
01 1IOC容器原理
1 IOC容器原理IOC概念 控制反转。把对象创建和对象调用的过程,交给Spring进行管理。 使用IOC的目的:降低代码耦合度。 底层原理 xml解析 工厂模式 反射 java对象调用的过程 1234567891011class UserDao{ add(){ }}public class UserService{ public void execute(){ UserDao dao = new UserDao(); dao.add(); }} 使用工厂模式 1234567891011121314151617class UserDao{ add(){ }}class UserFactory{ public static UserDao getDao(){ return new UserDao(); }}class Us...




