
02mini-batch梯度下降
1 | m = X.shape[1] |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2021-09-07
6.3-chinese
6.3 基于锁设计更加复杂的数据结构栈和队列都很简单:接口相对固定,并且它们应用于比较特殊的情况。并不是所有数据结构都像它们一样简单;大多数数据结构支持更加多样化的操作。原则上,这将增大并行的可能性,但是也让对数据保护变得更加困难,因为要考虑对所有能访问到的部分。当为了并发访问对数据结构进行设计时,这一系列原有的操作,就变得越发重要,需要重点处理。 先来看看,在查询表的设计中,所遇到的一些问题。 6.3.1 编写一个使用锁的线程安全查询表查询表或字典是一种类型的值(键值)和另一种类型的值进行关联(映射的方式)。一般情况下,这样的结构允许代码通过键值对相关的数据值进行查询。在C++标准库中,这种相关工具有:std::map<>, std::multimap<>, std::unordered_map<>以及std::unordered_multimap<>。 查询表的使用与栈和队列不同。栈和队列上,几乎每个操作都会对数据结构进行修改,不是添加一个元素,就是删除一个,而对于查询表来说,几乎不需要什么修改。清单3.13中有个例子,是一个简...

2022-12-05
31.TCP 为什么需要三次握手
TCP 为什么需要三次握手?TCP 协议是我们每天都在使用的一个网络通讯协议,因为绝大部分的网络连接都是建立在 TCP 协议上的,比如你此刻正在看的这篇文章是建立在 HTTP(Hypertext Transfer Protocol,超文本传送协议) 应用层协议的基础上的,而 HTTP 协议的“底层”则是建立在 TCP 的传输层协议上的。因此可以理解为,你之所以能看到本篇文章就是得益于 TCP 协议的功劳。 我们本课时的面试题是,说一下 TCP 三次握手的执行流程,以及为什么需要三次握手? 典型回答在回答这个问题之前,首先我们需要搞清楚两个概念,第一,什么是 TCP?第二,什么是 TCP 连接?只有搞明白了这两个问题,我们才能彻底搞懂为什么 TCP 需要三次握手? 什么是 TCP?首先来说 TCP(Transmission Control Protocol,传输控制协议)是一个面向连接的、可靠的、基于字节流的传输层协议。从它的概念中我们可以看出 TCP 的三个特点:面向连接、可靠性和面向字节流。 TCP 的特点面向连接:是指 TCP 是面向客户端和服务器端连接的通讯协议,使用它可...
2020-10-14
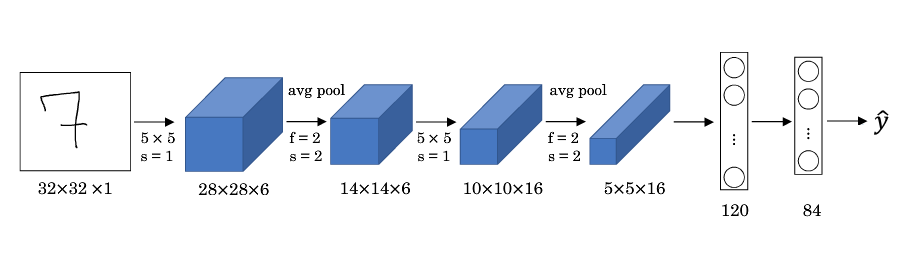
02深度卷积网络:实例探究
卷积神经网络:实例探究1 卷积网络说明 讲到的经典 CNN 模型包括: LeNet-5 AlexNet VGG ResNet(Residual Network,残差网络) Inception Neural Network。 2 经典卷积网络LeNet-5 特点: LeNet-5 针对灰度图像而训练,因此输入图片的通道数为 1。 该模型总共包含了约 6 万个参数,远少于标准神经网络所需。 典型的 LeNet-5 结构包含卷积层(CONV layer),池化层(POOL layer)和全连接层(FC layer),排列顺序一般为 CONV layer->POOL layer->CONV layer->POOL layer->FC layer->FC layer->OUTPUT layer。一个或多个卷积层后面跟着一个池化层的模式至今仍十分常用。 当 LeNet-5模型被提出时,其池化层使用的是平均池化,而且各层激活函数一般选用 Sigmoid 和 tanh。现在,我们可以根据需要,做出改进,使用最大池化并选用 ReLU 作为激活函数。 ...
2021-03-22
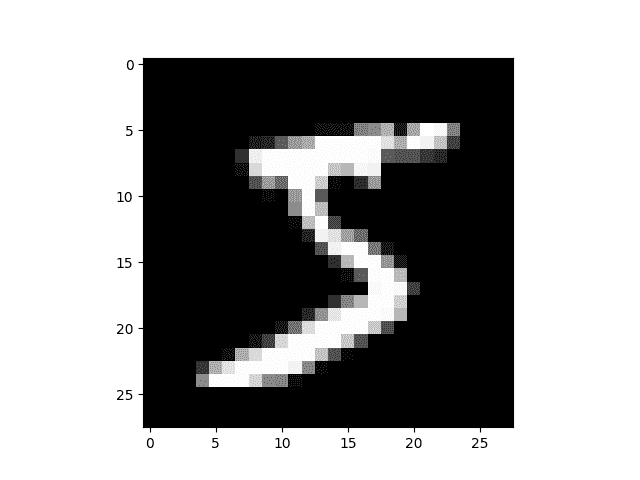
04 Pytorch nn本质
torch.nn到底是什么? 0 MNIST 数据集 1 从零开始的神经网络(没有torch.nn) 2 使用torch.nn.functional 3 使用nn.Module重构 4 使用nn.Linear重构 5 使用optim重构 6 使用Dataset重构 7 使用DataLoader重构 8 添加验证 8 创建fit()和get_data() 9 切换到 CNN nn.Sequential 9 包装DataLoader 10 使用您的 GPU 总结 torch.nn到底是什么?PyTorch 提供设计精美的模块和类torch.nn,torch.optim,Dataset和DataLoader神经网络。 为了充分利用它们的功能并针对您的问题对其进行自定义,您需要真正了解它们在做什么。 为了建立这种理解,我们将首先在 MNIST 数据集上训练基本神经网络,而无需使用这些模型的任何功能。 我们最初将仅使用最基本的 PyTorch 张量函数。 然后,我们将一次从torch.nn,torch.optim,Dataset或DataLoader中逐个添加一个函数,以准确显示每...

2021-09-07
8.5-chinese
8.5 在实践中设计并发代码当为一个特殊的任务设计并发代码时,需要根据任务本身来考虑之前所提到的问题。为了展示以上的注意事项是如何应用的,我们将看一下在C++标准库中三个标准函数的并行实现。当你遇到问题时,这里的例子可以作为很好的参照。在有较大的并发任务进行辅助下,我们也将实现一些函数。 我主要演示这些实现使用的技术,不过可能这些技术并不是最先进的;更多优秀的实现可以更好的利用硬件并发,不过这些实现可能需要到与并行算法相关的学术文献,或者是多线程的专家库中(比如:Inter的TBB[4])才能看到。 并行版的std::for_each可以看作为能最直观体现并行概念,就让我们从并行版的std::for_each开始吧! 8.5.1 并行实现:std::for_eachstd::for_each的原理很简单:其对某个范围中的元素,依次调用用户提供的函数。并行和串行调用的最大区别就是函数的调用顺序。std::for_each是对范围中的第一个元素调用用户函数,接着是第二个,以此类推,而在并行实现中对于每个元素的处理顺序就不能保证了,并且它们可能(我们希望如此)被并发的处理。 为了实现这...
2020-10-14
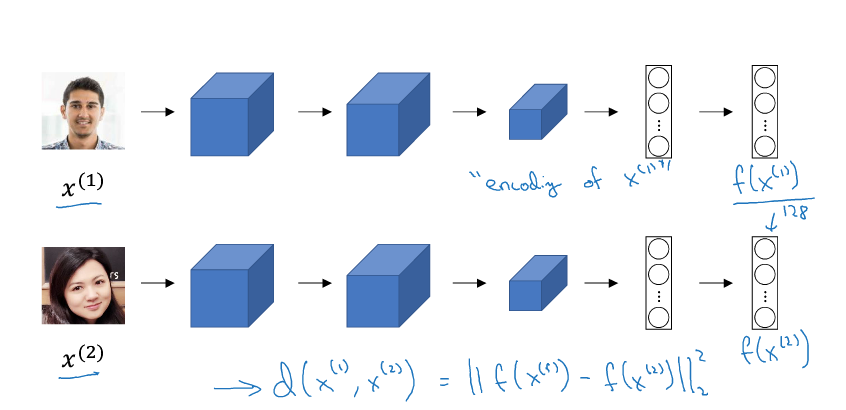
04特殊应用:人脸识别和神经风格迁移
特殊应用:人脸识别和神经风格转换 1 人脸识别定义 人脸验证(Face Verification) 和 人脸识别(Face Recognition) 的区别: 人脸验证:一般指一个一对一问题,只需要验证输入的人脸图像是否与某个已知的身份信息对应; 人脸识别:一个更为复杂的一对多问题,需要验证输入的人脸图像是否与多个已知身份信息中的某一个匹配。 一般来说,由于需要匹配的身份信息更多导致错误率增加,人脸识别比人脸验证更难一些。 2 One-Shot 学习 人脸识别所面临的一个挑战是要求系统只采集某人的一个面部样本,就能快速准确地识别出这个人,即只用一个训练样本来获得准确的预测结果。这被称为One-Shot 学习。 有一种方法是假设数据库中存有 N 个人的身份信息,对于每张输入图像,用 Softmax 输出 N+1 种标签,分别对应每个人以及都不是。然而这种方法的实际效果很差,因为过小的训练集不足以训练出一个稳健的神经网络;并且如果有新的身份信息入库,需要重新训练神经网络,不够灵活。 因此,我们通过学习一个 Similarity 函数来实现 One-Shot 学习过程。S...




