
01神经网络基础
神经网络基础
介绍神经网络的编程基础。看完视频,在总结这一部分。每一个视频,完成开始做笔记。
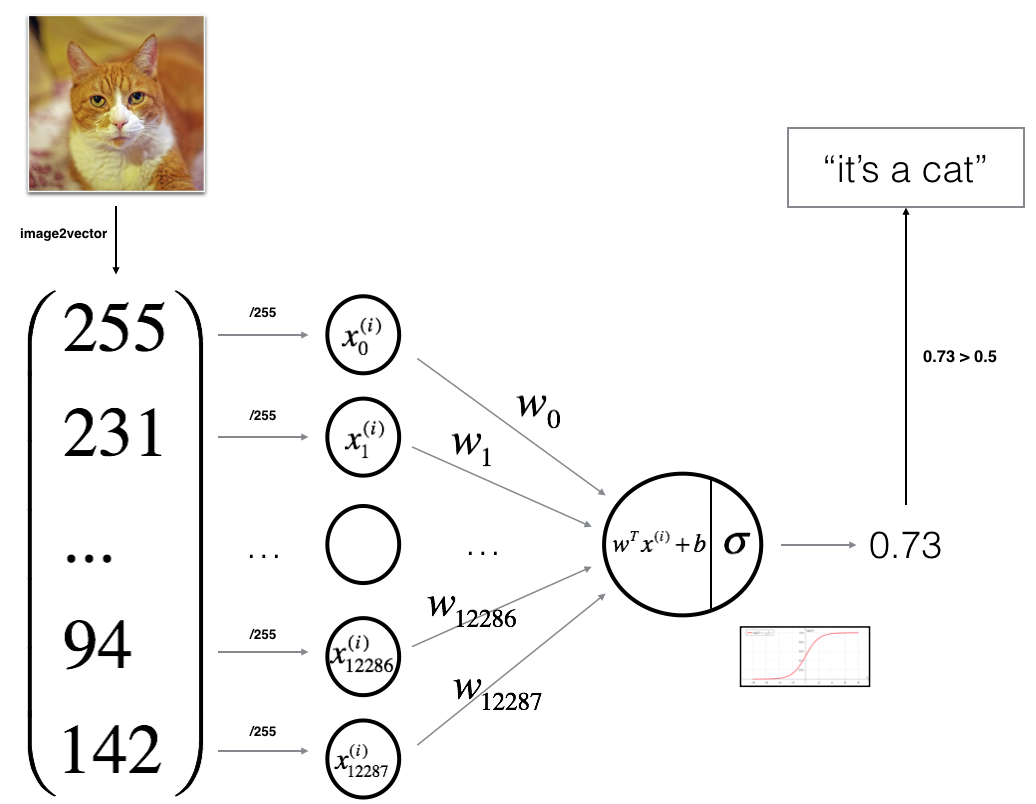
1 识别图片上的猫
问题定义
- 场景定义:监督学习。图像识别领域。非结构化数据输入。
- 问题定义:分类问题。
- 算法定义:logistics回归。
问题描述
- 输入的特征向量:$x \in R^{n_x}$,其中 ${n_x}$是特征数量;
- 输出的标签,用于训练的标签:$y \in 0,1$
- 训练集:${(x^{(1)},y^{(1)}),\dots,(x^{(m)},y^{(m)})}$紧凑矩阵表示训练集。约定使用列向量。
2 Logistic回归模型
Logistic 回归是一个用于二分分类的算法。
模型定义-假设函数
- 权重:$w \in R^{n_x}$
- 偏置: $b \in R$
- 输出:$\hat{y} = \sigma(w^Tx+b)$
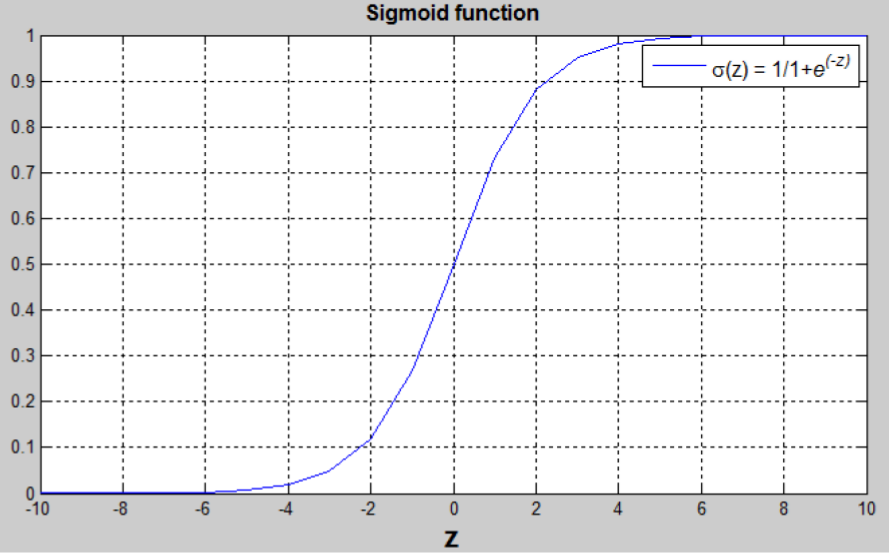
- Sigmoid 函数:
$$s = \sigma(w^Tx+b) = \sigma(z) = \frac{1}{1+e^{-z}}$$
将 $w^Tx+b$ 约束在 [0, 1] 间,引入 Sigmoid 函数。从下图可看出,Sigmoid 函数的值域为 [0, 1]。
Logistic => 神经网络
3 损失函数和代价函数
损失函数(loss function)和代价函数(cost function)
- 用于衡量预测结果与真实值之间的误差。最简单的损失函数定义方式为平方差损失:
$$L(\hat{y},y) = \frac{1}{2}(\hat{y}-y)^2$$
- 但 Logistic 回归中我们并不倾向于使用这样的损失函数,因为之后讨论的优化问题会变成非凸的,最后会得到很多个局部最优解,梯度下降法可能找不到全局最优值。一般使用
$$L(\hat{y},y) = -(y\log\hat{y})-(1-y)\log(1-\hat{y})$$
- 损失函数是在单个训练样本中定义的,它衡量了在单个训练样本上的表现。而代价函数(cost function,或者称作成本函数)衡量的是在全体训练样本上的表现,即衡量参数 w 和 b 的效果。
$$J(w,b) = \frac{1}{m}\sum_{i=1}^mL(\hat{y}^{(i)},y^{(i)})$$
4 梯度下降法(Gradient Descent)
梯度定义
函数的 梯度(gradient) 指出了函数的最陡增长方向。即是说,按梯度的方向走,函数增长得就越快。那么按梯度的负方向走,函数值自然就降低得最快了。
模型的训练目标即是寻找合适的 w 与 b 以最小化代价函数值。简单起见我们先假设 w 与 b 都是一维实数,那么可以得到如下的 J 关于 w 与 b 的图:
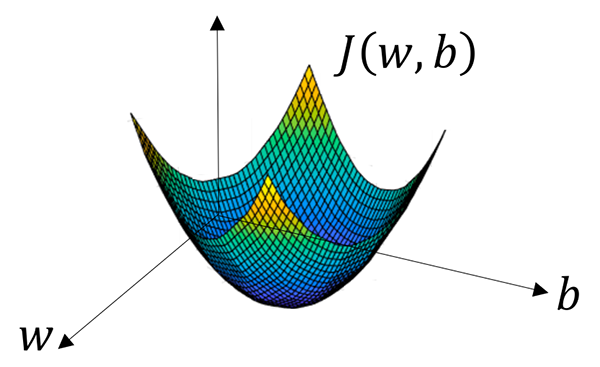
- 可以看到,成本函数 J 是一个凸函数,与非凸函数的区别在于其不含有多个局部最低点;选择这样的代价函数就保证了无论我们初始化模型参数如何,都能够寻找到合适的最优解。
计算过程
- 参数 w 的更新公式为:
$$w := w - \alpha\frac{dJ(w, b)}{dw}$$
其中 α 表示学习速率,即每次更新的 w 的步伐长度。当 w 大于最优解 w′ 时,导数大于 0,那么 w 就会向更小的方向更新。反之当 w 小于最优解 w′ 时,导数小于 0,那么 w 就会向更大的方向更新。迭代直到收敛。
在成本函数 J(w, b) 中还存在参数 b,因此也有:
$$b := b - \alpha\frac{dJ(w, b)}{db}$$
5 计算图(Computation Graph)
神经网络与计算图
- 由各个算子表示的节点构成的计算过程图形。
- 一个神经网络可以表示成一个计算图
前向计算
- 前向传播:通过自左向右的执行计算图,能够计算一个函数的值。
后向计算
- 后向传播:通过自右向左的执行计算图,计算导数,遵循链式法则。

Logistic 回归中的梯度下降法
神经元正向传播与反向传播的理解
神经网络总结。在正向传播过程中,神经元输入包括激活值、权重和偏置,输出是神经元的输出。在反向传播过程中,神经元的输入是链式偏导的过程,输出是链式偏导的结果。神经元的后向传播值表示的是,在后边的神经元修改一个值,这个神经元的输出,会变动多大的值。是输出的变动值。如果要求输入的或者参数的变动值,还需要对相应的输入和参数进行求导。
- 与一个神经元相关的值,包括激活值、权重、偏置、输出、偏导。
- 向上一个神经元传递的偏导,等于这个神经元的偏导对对应激活值的偏导数。然后把正向传播过程中的各个计算值代入到公式当中。
- 求权重的偏导,等于这个神经元的偏导,对对应的权重的偏导数。然后把正向传播过程中的各个计算值代入到公式中。
计算图反向传播过程
- 给出计算图:假设输入的特征向量维度为 2,即输入参数共有 x1, w1, x2, w2, b 这五个。可以推导出如下的计算图:
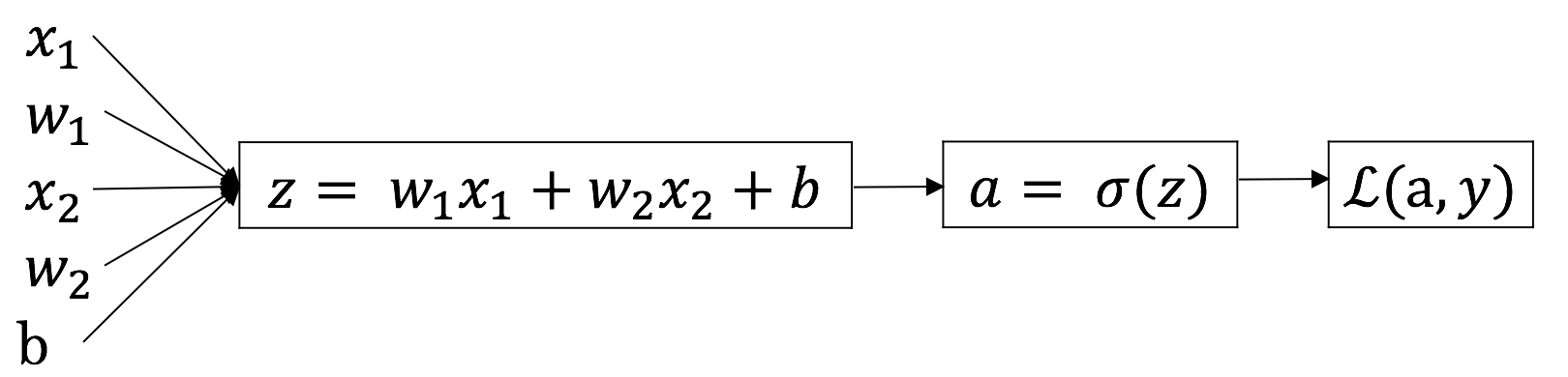
- 首先反向求出 L 对于 a 的导数:
$$da=\frac{dL(a,y)}{da}=−\frac{y}{a}+\frac{1−y}{1−a}$$
- 然后继续反向求出 L 对于 z 的导数:
$$dz=\frac{dL}{dz}=\frac{dL(a,y)}{dz}=\frac{dL}{da}\frac{da}{dz}=a−y$$
- 依此类推求出最终的损失函数相较于原始参数的导数之后,根据如下公式进行参数更新:
$$w _1:=w _1−\alpha dw _1$$
$$w _2:=w _2−\alpha dw _2$$
$$b:=b−\alpha db$$
- 接下来我们需要将对于单个用例的损失函数扩展到整个训练集的代价函数:
$$J(w,b)=\frac{1}{m}\sum^m_{i=1}L(a^{(i)},y^{(i)})$$
$$a^{(i)}=\hat{y}^{(i)}=\sigma(z^{(i)})=\sigma(w^Tx^{(i)}+b)$$
- 我们可以对于某个权重参数 w1,其导数计算为:
$$\frac{\partial J(w,b)}{\partial{w_1}}=\frac{1}{m}\sum^m_{i=1}\frac{\partial L(a^{(i)},y^{(i)})}{\partial{w_1}}$$
m个样本的训练过程
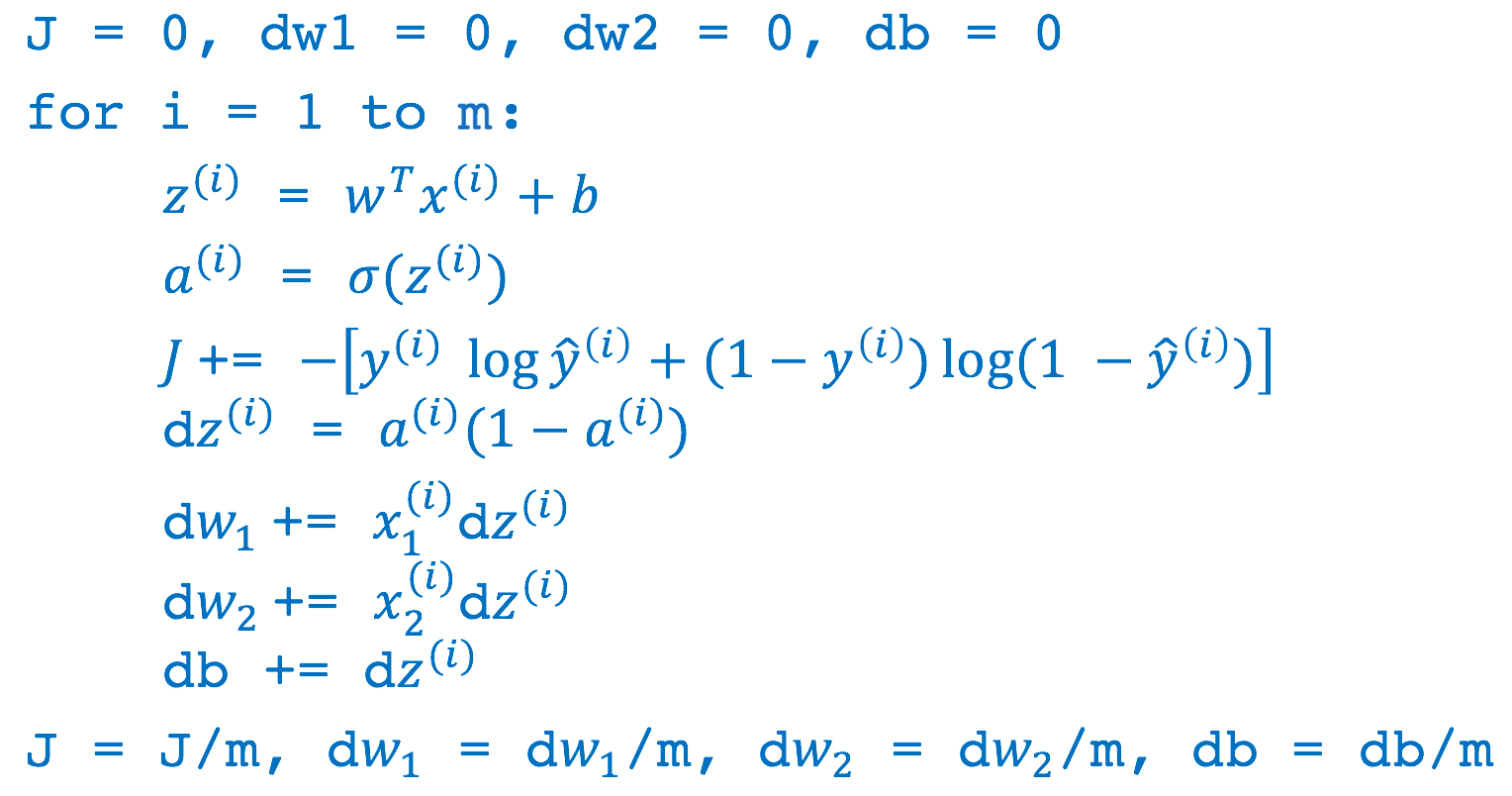
完整的 Logistic 回归中某次训练的流程如下,这里仅假设特征向量的维度为 2。然后对 w1、w2、b 进行迭代。
上述过程在计算时有一个缺点:你需要编写两个 for 循环。第一个 for 循环遍历 m 个样本,而第二个 for 循环遍历所有特征。如果有大量特征,在代码中显式使用 for 循环会使算法很低效。向量化可以用于解决显式使用 for 循环的问题。
6 向量化(Vectorization)
向量化计算
- 在 Logistic 回归中,需要计算 $z=w^Tx+b$ 如果是非向量化的循环方式操作,代码可能如下:
1 | z = 0; |
- 而如果是向量化的操作,代码则会简洁很多,并带来近百倍的性能提升(并行指令):
1 | z = np.dot(w, x) + b |
向量化逻辑回归
- 不用显式 for 循环,实现 Logistic 回归的梯度下降一次迭代(对应之前蓝色代码的 for 循环部分。这里公式和 NumPy 的代码混杂,注意分辨):
$$Z=w^TX+b=np.dot(w.T, x) + b$$
$$A=\sigma(Z)$$
$$dZ=A-Y$$
$$dw=\frac{1}{m}XdZ^T$$
$$db=\frac{1}{m}np.sum(dZ)$$
$$w:=w-\sigma dw$$
$$b:=b-\sigma db$$
- 正向和反向传播尽管如此,多次迭代的梯度下降依然需要 for 循环。
7 广播(broadcasting)
Numpy 的 Universal functions 中要求输入的数组 shape 是一致的。当数组的 shape 不相等的时候,则会使用广播机制,调整数组使得 shape 一样,满足规则,则可以运算,否则就出错。
四条规则:
- 让所有输入数组都向其中 shape 最长的数组看齐,shape 中不足的部分都通过在前面加 1 补齐;
- 输出数组的 shape 是输入数组 shape 的各个轴上的最大值;
- 如果输入数组的某个轴和输出数组的对应轴的长度相同或者其长度为 1 时,这个数组能够用来计算,否则出错;
- 当输入数组的某个轴的长度为 1 时,沿着此轴运算时都用此轴上的第一组值。
8 NumPy 使用技巧
- 转置必须作用在矩阵上,向量和数组不能转置。所以转置的numpy数组至少有两个维度。转置对秩为 1 的数组无效。因此,应该避免使用秩为 1 的数组,用 n * 1 的矩阵代替。例如,用
np.random.randn(5,1)代替np.random.randn(5)。如果得到了一个秩为 1 的数组,可以使用reshape进行转换。
1 | [1,2,3].shape=(3,) |
- 向量的外积可以获得一个矩阵。向量的內积是一个标量。.dot()行列是內积,列行是外积。
- 在使用numpy编程过程中,最好把numpy定义二维矩阵。这样在转置过程中也不会出错。而且最好是列向量。我们以列向量,方便理解。
- 使用assert语句进行快速测试。

9 logistics回归损失函数的理解
$$
if(y = 1),p(y|x)=\hat{y}\
if(y = 0),p(y|x)=1=\hat{y}\
p(y|x) = \hat{y}^y*(1-\hat{y})^{(1-y)}\
cost = \log p(y|x)
loss = \log \prod p(y|x)\
= \sum \log p(y|xf)
$$










