Scrapy框架学习——琐碎知识整理
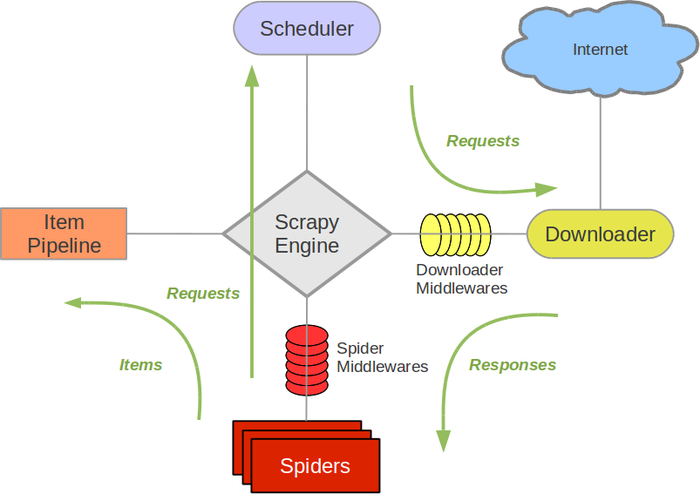
scrapy引擎
调度器
Spiders
下载器
Item Pipeline
itemloader用来装载,item用来容纳,itempipeline用来过滤。也负责了指明了存好数据的item的数据流动的方向。itemloader是活动在原始数据和item之间的桥梁。itempipeline是活动在item和具体存储数据的位置之间的桥梁。比如用来操纵数据库、用来写入文件,用来提供下一次爬虫的相关信息。
下载器中间件
由调度器具体指挥,能够根据引擎发送的request对象,封装真正的request请求,并且设置请求的响应参数。不同的下载器中间件,能够完成不同的任务。
Spider中间件
引擎和Spider之间的钩子。用来处理Spider发送给引擎的request和Item和引擎发送给Spider的response。有点像网络的分层,没一层都向发送数据中添加一点内容,每一层都从接受数据中获得一点内容。有很多中间件,可以在这里过滤掉一些错误。另外,如果错误能够越提前的发现,则越有利于提高效率。
扩展Extension和信号signal
框架提供了一个很好的扩展机制。在配置文件中声明,如果想要在某个地方进行扩展,可以通过这种方式:在要扩展的地方产生一个独特的信号。然后在扩展类中接受这个信号。接下来对接受到的信号和数据进行处理。最后将执行权返回。通过配置文件中的EXTENSION架子啊和激活。
而且信号能够诶眼催处理,停止处理等。有点像事件驱动机制一样。当产生一个事件,监听器就能监听到,然后做出响应的反应。这种方法,的确有利于扩展。
Link Extractors
从response对象中抽取能够最脏你刚是被过量欧文链接的对象。
Feed exports
在存储数据数据之前,对数据进行格式化。数据存储的方式:序列化的方式主要通过一下几个类。JSON,JSON
LINES,CSV , XML ,
PICKLE,MARSHAL。同时也用来定义数据存储的方式可以是本地文件系统,FTP,S3,标准输出等。通过URI类实现具体存储的方式。
异常Exception
内置了异常参看手册。主要的异常类有:DropItem
有itempipeline跑出,用来停止处理item。CloseSpider由Spider的回调函数抛出,用来停止spider。IgnoreRequest
由调度器或者下载中间价抛出,生命忽略该request。NotConfigured
由任何组件抛出,声明其仍然保持关闭。NotSupported声明了一个不支持的特性。