
Scrapy框架学习——ItemLoaders
ItemLoader是为了将获取文本进行分解,装载到相应的ItemLoader当中。
具体方法:
def parse(self, response): l = ItemLoader(item**=Product(),
response=response) l.add_xpath(‘name’, ‘//div[@class=”product_name”]’)
l.add_xpath(‘name’, ‘//div[@class=”product_title”]’)
l.add_xpath(‘price’, ‘//p[@id=”price”]’) l.add_css(‘stock’, ‘p#stock]’)
l.add_value(‘last_updated’, ‘today’) # you can also use literal values
return l.**load_item()
ItemLoader在每个字段中包含了一个输入处理器和一个输出处理器。
输入处理器收到数据时,理科提取数据,通过add_xpath(),add_css(),add_value()方法
之后输入处理器的结果被手气起来并保存到ItemLoader内。
收集到所有的数据后,调用ItemLoader.load_item()方法来填充,并得到填充后的Item对象。
这是当输出处理器和之前手机到的数据被调用。数据的结果是被分配多啊Item的最终值。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐
2020-01-04
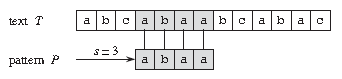
3.7 字符串算法-匹配算法
字符串匹配算法问题分析字符串匹配问题的形式定义 文本(Text)是一个长度为 n 的数组 T[1..n]; 模式(Pattern)是一个长度为 m 且 m≤n 的数组 P[1..m]; T 和 P 中的元素都属于有限的字母表 Σ 表; 如果 0≤s≤n-m,并且 T[s+1..s+m] = P[1..m],即对 1≤j≤m,有 T[s+j] = P[j],则说模式 P 在文本 T 中出现且位移为 s,且称 s 是一个有效位移(Valid Shift)。 比如上图中,目标是找出所有在文本 T = abcabaabcabac 中模式 P = abaa 的所有出现。该模式在此文本中仅出现一次,即在位移 s = 3 处,位移 s = 3 是有效位移。 解决字符串匹配的算法包括 朴素算法(Naive Algorithm) Rabin-Karp 算法 有限自动机算法(Finite Automation) Knuth-Morris-Pratt 算法(即 KMP Algorithm) Boyer-Moore 算法、Simon 算...

2021-12-24
vgremove
vgremove用于用户删除LVM卷组 补充说明vgremove命令 用于用户删除LVM卷组。当要删除的卷组上已经创建了逻辑卷时,vgremove命令需要进行确认删除,防止误删除数据。 语法1vgremove(选项)(参数) 选项1-f:强制删除。 参数卷组:指定要删除的卷组名称。 实例使用vgremove命令删除LVM卷组”vg1000”。在命令行中输入下面的命令: 12[root@localhost ~]# vgremove vg1000 #删除卷组"vg1000"Volume group "vg1000" successfully removed

2019-10-15
5.1 链路层-基本原理
基本原理1 概述两种链路 广播信道:有线局域网、卫星网、混合光纤同轴电缆接入网的多台主机。需要媒体访问控制协议(多路访问控制协议) 点对点通信链路。不需要多路访问控制协议。 概念 结点:运行链路层协议的设备 链路:沿通信路径,连接相邻节点的通信信道 服务 成帧:用链路层帧封装上层数据。网络层数据报插在数据字段。 链路接入:媒体访问控制协议规定了帧在链路上的传输规则,MAC协调多个节点的帧传输,点对点传输不需要媒体访问控制协议。 可靠交付:通过确认重传 差错检测和纠正。 实现在网络适配器中实现。 在发送端,控制器取的协议栈高层生成并存储在主机内存中的数据包,在链路层中封装该数据包。遵循链路接入协议,将该帧传入通信链路。 在接收端,控制器接受了整个帧,抽取网络层数据报。执行差错检测。 2 差错检测和纠正技术概述比特及差错检测和纠正。从一个结点到临近节点,发送的链路层帧中,比特损伤检测和纠正。(Error-Detection and Correction,EDC) 包括奇偶校验、校验和方法、循环冗余检测。 奇偶校验发送方附加一个比特,使得d+1个比特中的1的总数是奇数或者偶数。接...
2019-10-15
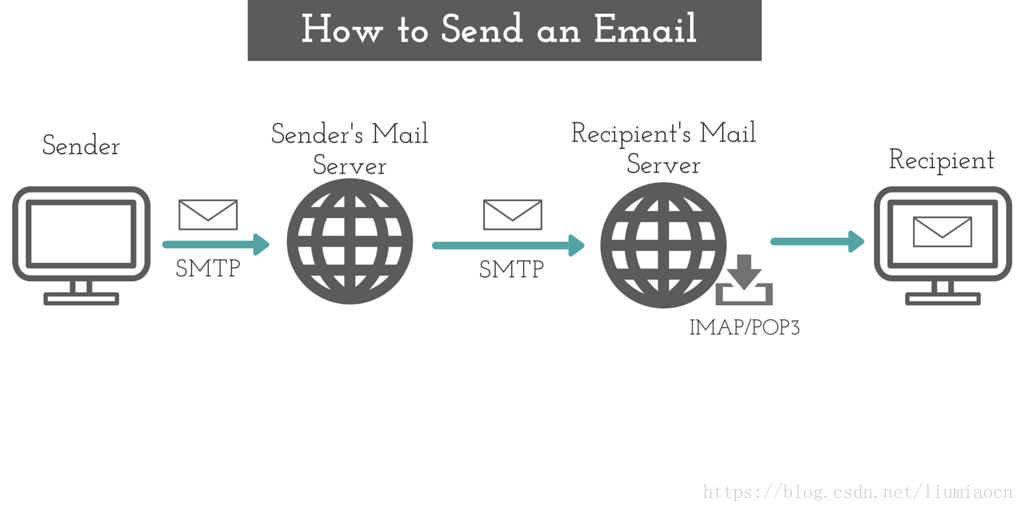
2.4 应用层-邮件协议
邮件协议 协议基础:SMTP SMTP协议介绍 1 SMTP协议概述Simple Mail Transfer Protocol 简单邮件传输协议 SMTP 由两部分:运行在发送方邮件服务器的客户端和运行在接收方邮件服务器的服务器端。每台邮件服务器上既运行 SMTP 的客户端也运行 SMTP 的服务器端程序 SMTP 一般不使用中间服务器发送邮件。如若接收方的邮件服务器没开,TCP 连接报文会保留在发送方的邮件服务器上,等待新的尝试,如若长时间都失败,那么发送方服务器就会删掉该报文并以邮件的形式通知发送方 SMTP 限制所有的邮件报文只能采用简单的 7 比特 ASCII 表示。 与HTTP的对比相同点: 都从一台主机向另一台主机传送文件,持续的 HTTP 和 SMTP 都是用持续连接 不同点: HTTP 是一个 拉协议,TCP 连接是由想要接收文件的机器发起的。SMTP 是一个 推协议,TCP 连接是由想要发送文件的机器发起的。 SMTP 要求报文必须按照 7 比特 ASCII 码进行编码。HTTP 则没有这种限制。 在处理包含多种不同类型的文档时。HTTP把每个对象...

2021-12-24
iostat
iostat监视系统输入输出设备和CPU的使用情况 补充说明iostat命令 被用于监视系统输入输出设备和CPU的使用情况。它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况。同vmstat一样,iostat也有一个弱点,就是它不能对某个进程进行深入分析,仅对系统的整体情况进行分析。 语法1iostat(选项)(参数) 选项12345678-c:仅显示CPU使用情况;-d:仅显示设备利用率;-k:显示状态以千字节每秒为单位,而不使用块每秒;-m:显示状态以兆字节每秒为单位;-p:仅显示块设备和所有被使用的其他分区的状态;-t:显示每个报告产生时的时间;-V:显示版号并退出;-x:显示扩展状态。 参数 间隔时间:每次报告的间隔时间(秒); 次数:显示报告的次数。 实例用iostat -x /dev/sda1来观看磁盘I/O的详细情况: 12345678910111213iostat -x /dev/sda1 Linux 2.6.18-164.el5xen (localhost.localdomain)2010年03月26日 avg-cpu: %user...

2021-03-08
TensorFlow-IO
TensorFlow - IO 在 tf.data 之前,一般使用 QueueRunner,但 QueueRunner 基于 Python 的多线程及队列等,效率不够高,所以 Google发布了tf.data,其基于C++的多线程及队列,彻底提高了效率。所以不建议使用 QueueRunner 了,取而代之,使用 tf.data 模块吧:简单、高效。 preload直接将数据设置为常量,加载到TensorFlow的graph中。 12345678import tensorflow as tfx1 = tf.constant([2,3,4])x2 = tf.constant([4,0,1])y = tf.add(x1,x2)with tf.Session() as sess: print(sess.run(y)) feed_dict使用Python代码获取数据,通过给run()或者eval()函数输入feed_dict参数,传入数据,可以启动运算过程。 1234with tf.Session(): input = tf.placeholder(tf.float32) c...




