
0 数据结构基础
数据结构基础
参考文献
1 简介
数据结构的组成
数据结构主要包括两部分。
- 数据的结构。包括存储结构和逻辑结构。存储结构决定在其在计算机内存中的表现形式和具有的特点。逻辑结构决定了“数据”内部之间的关联结构。
- 数据的规则。基于数据的存储结构和逻辑结构。衍生出数据的一系列基本操作。包括创建、遍历、插入、删除等,每一类数据结构都有其相应的基础操作。
本目录主要讲解了。数据的结构和数据的规则。以及这两个东西的实现方法。不包括在这些数据的和数据的规则之上的更顶层的算法。如基于前序遍历(数据的规则)的什么什么算法(上层的算法)。
数据结构预算法
基本术语
数据结构是任何程序或软件的构建块(基础块)。为程序选择适当的数据结构对于程序员来说是最困难的任务。就数据结构而言,使用以下术语 -
- 数据:数据可以定义为基本值或值集合,例如,学生的姓名和ID,成绩等就是学生的数据。
- 组项:具有从属数据项的数据项称为组项,例如,学生的姓名由名字和姓氏组成。
- 记录:记录可以定义为各种数据项的集合,例如,如果以学生实体为例,那么学生的名称,地址,课程和标记可以组合在一起形成学生的记录。
- 文件:文件是一种类型实体的各种记录的集合,例如,如果类中有60名员工,则相关文件中将有20条记录,其中每条记录包含有关每个员工的数据。
- 属性和实体:实体表示某些对象的类。它包含各种属性。每个属性表示该实体的特定属性。
- 字段:字段是表示实体属性的单个基本信息单元。
为什么需要数据结构
随着应用程序变得越来越复杂,数据量日益增加,可能会出现以下问题:
- 处理器速度:要处理非常大的数据,需要高速处理,但随着数据逐日增长到每个实体数十亿个文件,处理器可能无法处理大量数据。
- 数据搜索:假设商店的库存大小是100860个商品,如果应用程序需要搜索某一特定商品,则每次需要遍历100860个商品,这会导致搜索过程变慢。
- 大量请求:如果成千上万的用户在Web服务器上同时搜索数据,在此过程中可能在短时会有一个非常大请求而导致服务器处理不了。
数据结构的优点
- 效率:程序的效率取决于数据结构的选择。
- 可重用性:数据结构是可重用的,即当实现了特定的数据结构,就可以在其他地方使用它。也将数据结构的实现编译到不同客户端使用的程序库中
- 抽象:数据结构由ADT指定,它提供抽象级别。 客户端程序仅通过接口使用数据结构,而不涉及实现细节。
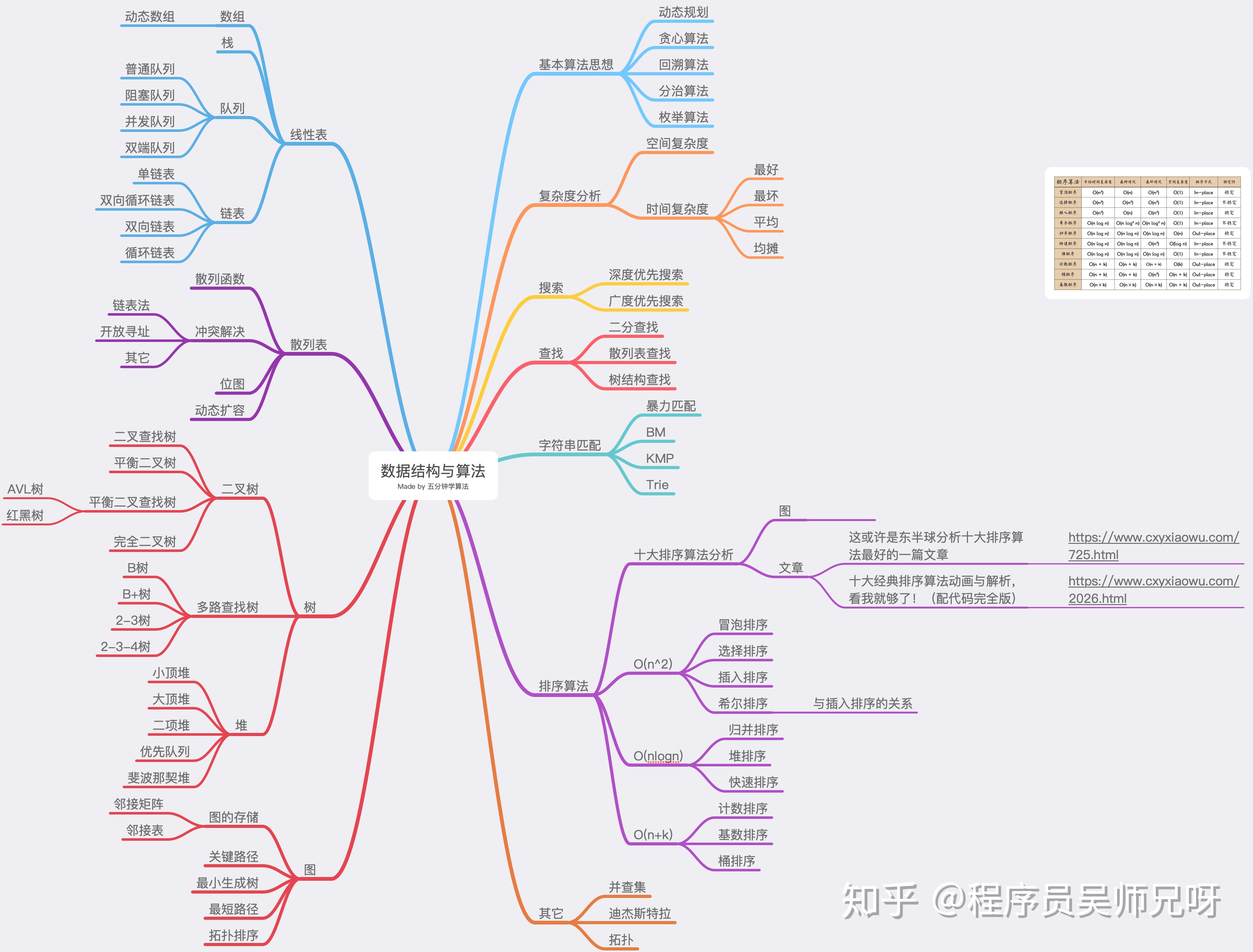
2 数据结构分类
线性数据结构
如果数据结构的所有元素按线性顺序排列,则称为线性数据结构。 在线性数据结构中,元素以非分层方式存储,除了第一个和最后一个元素,它的每个元素具有后继元素和前导元素。
线性数据结构的类型如下:
- 数组:数组是类似数据项的集合,每个数据项称为数组的元素。 元素的数据类型可以是任何有效的数据类型,如char,int,float或double。数组的元素共享相同的变量名,但每个元素都带有一个不同的索引号,这些索引号也称为下标。 数组可以是一维的,二维的或多维的。
1 | age[0], age[1], age[2], age[3],.... age[98], age[99] |
- 链表:链表是一种线性数据结构,用于维护内存中的列表。 它可以看作存储在非连续内存位置的节点集合。链表中的每个节点都包含指向其相邻节点的指针。
- 堆栈 :堆栈是一个线性列表,其中只允许在一端插入和删除,称为顶部。堆栈是一种抽象数据类型(ADT),可以在大多数编程语言中实现。 它被命名为堆栈,因为它的行为类似于真实世界的堆栈,例如:成堆的板块或卡片组等,只能在最顶面上操作。
- 队列:队列是一个线性列表,它的元素只能在一端插入(添加),也被称为后端,而只在另一端出队(删除),也被称为前端。
非线性数据结构
非线性数据结构不形成序列,即每个项目或元素以非线性排列与两个或更多个其他项目连接。 数据元素不按顺序结构排列。
非线性数据结构的类型如下:
- 树:树是多级数据结构,其元素之间具有层次关系,树的元素也称为节点。层次中最底层的节点称为叶节点,而最顶层节点称为根节点。 每个节点都包含指向相邻节点的指针。树数据结构基于节点之间的父子关系。 除了叶节点之外,树中的每个节点可以具有多个子节点,而除了根节点之外,每个节点可以具有最多一个父节点。 树可以分为许多类别,本教程在稍后章节中将对此进行讨论。
- 图:图可以定义为由称为边缘的链接连接的元素集(由顶点表示)的图表示。 图不同于树,图可以有循环而树不能具有循环。
3 数据结构的操作
从数据结构的角度
- 遍历:每个数据结构都包含一组数据元素。遍历数据结构表示访问数据结构的每个元素,以便执行某些特定操作,如搜索或排序。示例 :如果需要计算学生在6个不同科目中获得的分数的平均值,需要遍历完整的分数数组并计算总和,然后将总分数除以科目数,即6, 最后得到平均值。
- 插入:插入是在任何位置将元素添加到数据结构的过程。如果数据结构的大小是n,那么只能在n-1个数据元素之间插入元素。
- 删除:从数据结构中删除元素的过程称为删除。 可以在任何随机位置删除数据结构中的元素。如果要从空数据结构中删除元素,则会发生下溢。
- 搜索:在数据结构中查找元素位置的过程称为搜索。 有两种算法可以执行搜索,即线性搜索和二进制搜索。在本教程后面讨论这两种搜索算法。
- 排序:按特定顺序排列数据结构的过程称为排序。 有许多算法可用于执行排序,例如,插入排序,选择排序,冒泡排序等。
- 更新:为更新数据结构中的现有元素而开发的算法。
- 合并:当两个列表分别为大小为M和N的列表A和列表B时,相似类型的元素,连接产生第三个列表,列表C的大小(M + N),则此过程称为合并。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2021-04-05
5.4 并查集
并查集 参考文献 https://zhuanlan.zhihu.com/p/93647900/ https://blog.csdn.net/qq_41754350/article/details/81271567 1 概念定义并查集被很多OIer认为是最简洁而优雅的数据结构之一,主要用于解决一些元素分组的问题。它管理一系列不相交的集合,并支持两种操作: 合并(Union):把两个不相交的集合合并为一个集合。 查询(Find):查询两个元素是否在同一个集合中。 2 并查集原理初始化 初始化所有的节点的根节点是自己。 假如有编号为1, 2, 3, …, n的n个元素,我们用一个数组fa[]来存储每个元素的父节点(因为每个元素有且只有一个父节点,所以这是可行的)。一开始,我们先将它们的父节点设为自己。 查询 我们用递归的写法实现对代表元素的查询:一层一层访问父节点,直至根节点(根节点的标志就是父节点是本身)。要判断两个元素是否属于同一个集合,只需要看它们的根节点是否相同即可。 合并 合并操作也是很简单的,先找到两个集合的代表元素,然后将前者的...

2020-01-04
3.4 排序算法-简单排序
排序算法0 比较排序算法分类比较排序(Comparison Sort)通过对数组中的元素进行比较来实现排序。 比较排序算法(Comparison Sorts) Category Name Best Average Worst Memory Stability 插入排序 (Insertion Sorts) 插入排序 (Insertion Sort) n n2 n2 1 Stable 希尔排序 (Shell Sort) n n log2 n n log2 n 1 Not Stable 交换排序 (Exchange Sorts ) 快速排序 (Quick Sort) n log n n log n n2 log n Not Stable 冒泡排序 (Bubble Sort) n ...

2022-01-07
2 GraphEmbedding
图嵌入0 引言概述在图上进行每一个节点的embedding,最终得到的结果是图上每一个节点的嵌入表示。这里主要通过无监督的方法实现embedding的过程。主要包括五种传统算法 Deepwalk LINE SDNE node2vec struct2vec 作用n维onehot向量表示图上的每一个节点。有多少个节点,就有多少onehot向量。如果节点的数量比较多,那么n的维度就会比较大。 代码https://github.com/shenweichen/GraphEmbedding 1 deepwalk 对每一个节点进行多次随机游走得到一系列语义信息。 w表示前后照顾的节点的数量、d表示嵌入后向量的维度、$\gamma$表示迭代的次数、t表示行走的步长 嵌入的维度为d=2的时候,就可以进行二维可视化了。如下所示,通过嵌入后的二维向量可是话,能够得到点的距离关系,相当于利用了图特征。 2 LINE 基于以下两个原理: 节点相互连接,并且相互连接的节点之间的权重很大,具有很高的相似性。 节点的邻居如果很相似的话,那么这两个节点即使不连接,那么他们也非常相似。 ...
2021-04-08
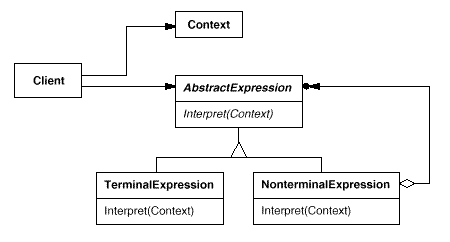
4.3 解释器
意图 给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。 Given a language, define a represention for its grammar along with aninterpreter that uses the representation to interpret sentences in the language. 结构 参与者 AbstractExpression 声明一个抽象的解释操作,这个接口为抽象语法树中所有的节点所共享。 TerminalExpression 实现与文法中的终结符相关联的解释操作。 一个句子中的每一个终结符需要该类的一个实例。 NonterminalExpression 对文法中的规则的解释操作。 Context 包含解释器之外的一些全局信息。 Client 构建表示该语法定义的语言中一个特定的句子的抽象语法树。 调用解释操作 适用性 当有个语言需要解释执行,并且你可将该语言中的句子表示为一个抽象语法树时,可以使用Interpreter 模...
2021-03-09
4 UML笔记之规则和公共机制
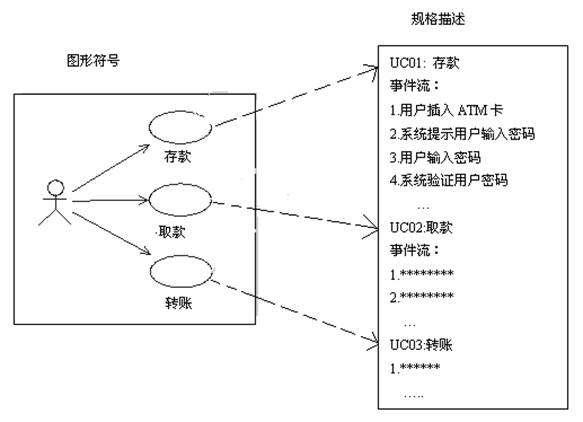
规则 在UML中,代表事物的元素符号在使用时应遵守一系列规则,每个元素必须遵守的3种语义规则如下: l 名称:每个元素应该有一个名字,即,事物、关系和图都应该有一个名字。和任何语言一样,名字即是一个标识符。 l 范围:每个元素起作用的范围。相当于程序设计语言中变量的“作用域”。 l 可见性:我们知道,UML元素可能属于一个类或包中,因此,所有元素都具有可见属性。在UML中,为元素定义了4种可见性,如表2-4所示。 表2-4 UML元素的可见性 元素的可见性 规 则(假设被访问的元素在包中) 标准表示法 public 任一元素若能访问包,则就可以访问包中的元素它 + protected 只有包中的元素或子包才能访问它 # private 只有包中的元素才能访问它 - package 只有声明在同一个包中的元素才能访问该元素 ~ 公共机制 在UML语言中,定义了4种公共机制:规格描述、修饰、通用划分和扩展机制。 规格描述 在UML语言中,对每一个元素有一个图形符号来表示,同时,对每个图形符号的语义有一个详细的文字描...
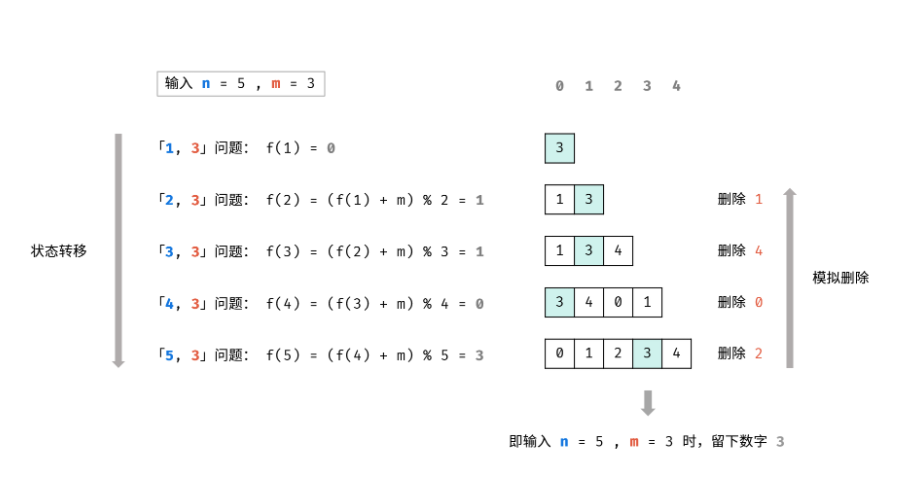
2020-01-05
4.5 约瑟夫问题
约瑟夫问题问题描述一堆人围城环。每次淘汰第m个人。最终剩下谁。 问题分析算法设计我们将上述问题建模为函数 f(n, m),该函数的返回值为最终留下的元素的序号。 首先,长度为 n 的序列会先删除第 m % n 个元素,然后剩下一个长度为 n - 1 的序列。那么,我们可以递归地求解 f(n - 1, m),就可以知道对于剩下的 n - 1 个元素,最终会留下第几个元素,我们设答案为 x = f(n - 1, m)。 由于我们删除了第 m % n 个元素,将序列的长度变为 n - 1。当我们知道了 f(n - 1, m) 对应的答案 x 之后,我们也就可以知道,长度为 n 的序列最后一个删除的元素,应当是从 m % n 开始数的第 x 个元素。因此有 f(n, m) = (m % n + x) % n = (m + x) % n。 算法分析算法实现 递归 12345678910111213class Solution { int f(int n, int m) { if (n == 1) { ...




