
7 图
图
1 简介
概念
- 图可以定义为用于顶点和边的组合。 图可以看作是循环树,图中顶点(节点)维持它们之间的任何复杂关系,而不是简单的父子关系。
- 图G 可以定义为有序集G(V,E),其中V(G)表示顶点集,E(G)表示用于连接这些顶点的边集。
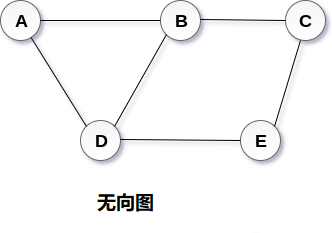
- 图G(V,E)有5个顶点(A,B,C,D,E)和6个边((A,B),(B,C),(C,E),(E,D), (D,B),(D,A))如下图所示。
术语
- 阶(Order) - 图 G 中点集 V 的大小称作图 G 的阶。
- 子图(Sub-Graph) - 当图 G’=(V’,E’)其中 V‘包含于 V,E’包含于 E,则 G’称作图 G=(V,E)的子图。每个图都是本身的子图。
- 生成子图(Spanning Sub-Graph) - 指满足条件 V(G’) = V(G)的 G 的子图 G’。
- 导出子图(Induced Subgraph) - 以图 G 的顶点集 V 的非空子集V1 为顶点集,以两端点均在 V1 中的全体边为边集的 G 的子图,称为 V1 导出的导出子图;以图 G 的边集 E 的非空子集 E1 为边集,以 E1 中边关联的顶点的全体为顶点集的 G 的子图,称为 E1 导出的导出子图。
- 度(Degree) - 一个顶点的度是指与该顶点相关联的边的条数,顶点 v 的度记作 d(v)。
- 入度(In-degree)和出度(Out-degree) - 对于有向图来说,一个顶点的度可细分为入度和出度。一个顶点的入度是指与其关联的各边之中,以其为终点的边数;出度则是相对的概念,指以该顶点为起点的边数。
- 自环(Loop) - 若一条边的两个顶点为同一顶点,则此边称作自环。
- 路径(Path) - 从 u 到 v 的一条路径是节点序列v0,e1,v1,e2,v2,…ek,vk,其中 ei 的顶点为 vi 及 vi - 1,k 称作路径的长度。如果它的起止顶点相同,该路径是“闭”的,反之,则称为“开”的。一条路径称为一简单路径(simple path),如果路径中除起始与终止顶点可以重合外,所有顶点两两不等。
- 行迹(Trace) - 如果路径 P(u,v)中的边各不相同,则该路径称为 u 到 v 的一条行迹。闭的行迹称作回路(Circuit)。
- 轨迹(Track) - 如果路径 P(u,v)中的顶点各不相同,则该路径称为 u 到 v 的一条轨迹。闭的轨迹称作圈(Cycle)。
- 桥(Bridge) - 若去掉一条边,便会使得整个图不连通,该边称为桥。
- 相邻节点如果两个节点u和v通过边e连接,则节点u和v被称为邻居或相邻节点。
分类
- 有向图 - 如果给图的每条边规定一个方向,那么得到的图称为有向图。
- 无向图 - 边没有方向的图称为无向图。
- 连通图连通图是在V中的每两个顶点(u,v)之间存在一些路径的图。连通图中没有孤立的节点。
- 完整图完整图是每个节点与所有其他节点连接的图。 完整图包含n(n-1/2个边,其中n是图中节点的数量。
- 权重图在权重图中,为每个边分配一些数据,例如长度或重量。 边e的权重可以给定为w(e),其必须是指示穿过边缘的成本的正(+)值。
2 图的实现
邻接矩阵
在顺序表示中,使用邻接矩阵来存储由顶点和边表示的映射。在邻接矩阵中,行和列由图顶点表示。 具有n个顶点的图将具有尺寸n×n。
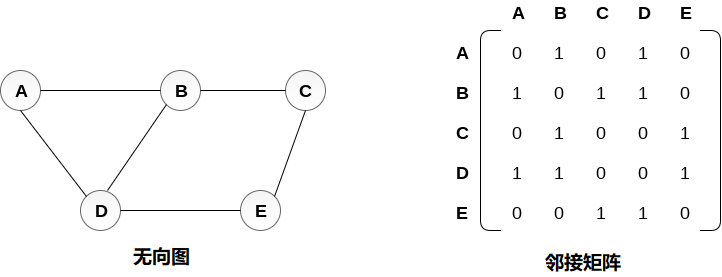
如果在Vi和Vj之间存在边缘,则无向图G的邻接矩阵表示中的项目Mij将为1。
无向图及其邻接矩阵表示如下图所示。
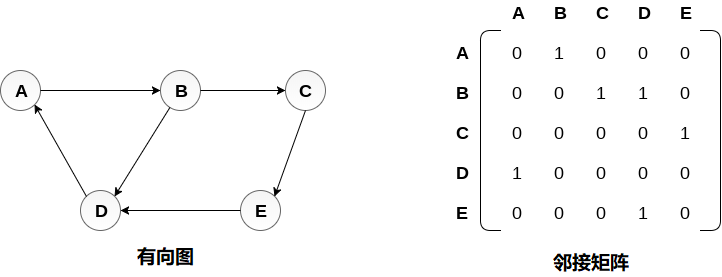
有向图及其邻接矩阵表示如下图所示。
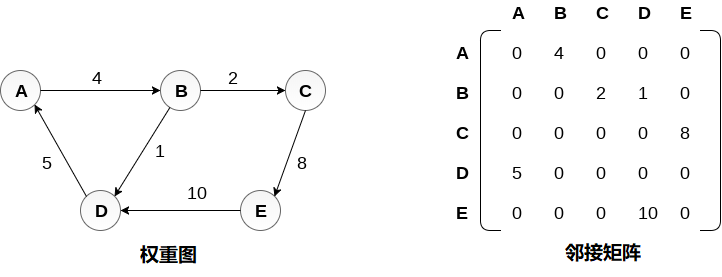
权重有向图以及邻接矩阵表示如下图所示。
邻接链表
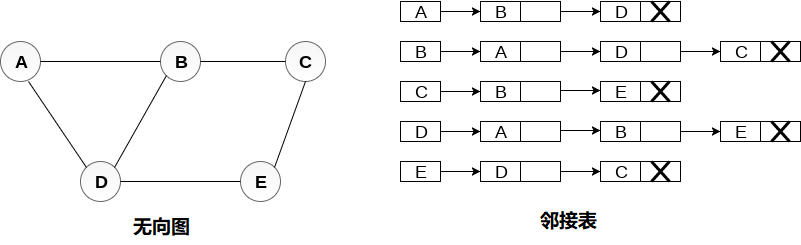
- 邻接列表用于将图存储到计算机的内存中。考虑下图中显示的无向图并检查邻接列表表示。要为图中存在的每个节点维护邻接列表,邻接列表将节点值和指向下一个相邻节点的指针存储到相应节点。 如果遍历所有相邻节点,则将NULL存储在列表的最后一个节点的指针字段中。 邻接列表的长度之和等于无向图中存在的边数的两倍。
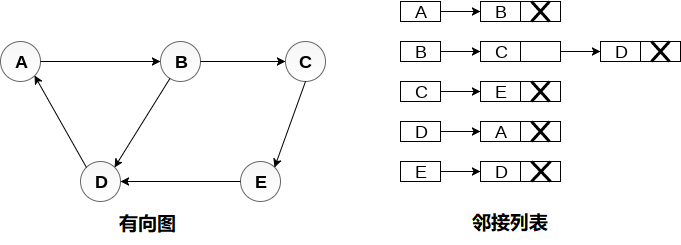
- 有向图,并查看图的邻接列表表示。在有向图中,所有邻接列表的长度之和等于图中存在的边的数量。
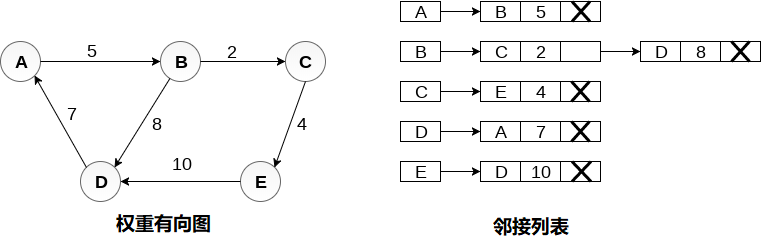
- 加权有向图,每个节点包含一个额外的字段,称为节点的权重。 有向图的邻接列表表示如下图所示。
3 基本操作
基本操作
- 创建一个图结构 - CreateGraph(G)
- 检索给定顶点 - LocateVex(G,elem)
- 获取图中某个顶点 - GetVex(G,v)
- 为图中顶点赋值 - PutVex(G,v,value)
- 返回第一个邻接点 - FirstAdjVex(G,v)
- 返回下一个邻接点 - NextAdjVex(G,v,w)
- 插入一个顶点 - InsertVex(G,v)
- 删除一个顶点 - DeleteVex(G,v)
- 插入一条边 - InsertEdge(G,v,w)
- 删除一条边 - DeleteEdge(G,v,w)
- 遍历图 - Traverse(G,v)
创建
- 图的邻接链表实现方法
1 | // 图的邻接链表实现方法 |
搜索——广度优先搜索
广度优先搜索是一种图遍历算法,它从根节点开始遍历图并探索所有相邻节点。 然后,它选择最近的节点并浏览所有未探测的节点。 对于每个最近的节点,该算法遵循相同的过程,直到找到目标为止。
下面给出了广度优先搜索的算法。算法从检查节点A及其所有邻居开始。在下一步中,搜索A的最近节点的邻居,并且在后续步骤中继续处理。 该算法探索所有节点的所有邻居,并确保每个节点只访问一次,并且没有访问任何节点两次。
算法
1 | 第1步:设置状态 = 1(就绪状态) |
实例
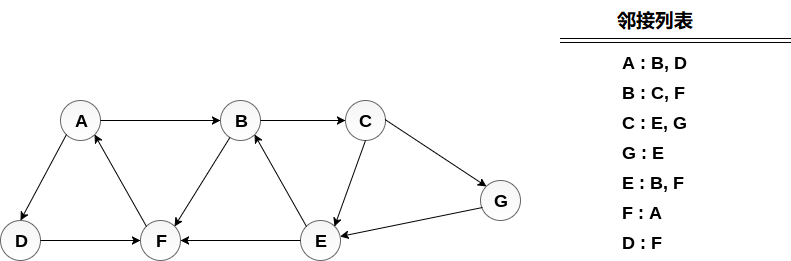
考虑下图中显示的图G,计算从节点A到节点E的最小路径p。给定每条边的长度为1。最小路径P可以通过应用广度优先搜索算法找到,该算法将从节点A开始并将以E结束。算法使用两个队列,即QUEUE1和QUEUE2。 QUEUE1保存要处理的所有节点,而QUEUE2保存从QUEUE1处理和删除的所有节点。
1 | ``` |
第1步:为G中的每个节点设置STATUS = 1(就绪状态)
第2步:将起始节点A推入堆栈并设置其STATUS = 2(等待状态)
第3步:重复第4步和第5步,直到STACK为空
第4步:弹出顶部节点N.处理它并设置其STATUS = 3(处理状态)
第5步:将处于就绪状态(其STATUS = 1)的N的所有邻居推入堆栈并设置它们
STATUS = 2(等待状态)
[循环结束]
第6步:退出
1 | > 实例 |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2021-03-09
Xpath学习 CSS选择器学习
XPath使用路径表达式来选取XML文档中的节点或者节点集合。节点是通过path或者步来选取的。 1. 通过已经有的表达式选取节点、元素、属性和内容 nodename 选取此节点的所有子节点 / 从根节点开始选取 // 从匹配选择的当前节点选择文档中的节点 . 选取当前节点 .. 选取当前节点的父节点 @ 选取属性 2. 带有位于的路径表达式,使用[ ]来表示当前节点被选取的一些条件 /bookstor/book[price>35]/title 3. 通配符来选取未知的元素(一般也用python的re表达式) * 匹配任何元素的节点 @* 匹配带有任何属性节点(没有属性的节点不行) node() 匹配任何类型的接待你。 对于CSS来说,选择器与HTML和CSS相关。 .class intro 查找类别下的元素 #id #firstname id=*的所有用户 element p 选择所有的元素 element,element 并列选择 element element 父子选择 element>ele...
2021-04-07
12 集群与分片
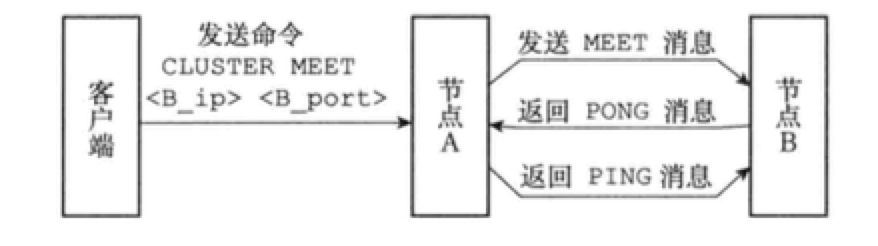
集群分片0 概述Redis集群是分布式的数据库方案,通过分片(sharing)来进行数据共享,并提供复制或故障转移功能。 1 节点一个Redis集群通常由多个节点(node)组成。开始时每个node都是独立的,要将其连接起来: CLUSTER MEET 启动节点一个节点就是运行在集群模式下的Redis服务器,根据cluster-endabled配置选项是否为yes来决定是否开启集群模式。 节点在集群模式下会继续使用单机模式的组件,如: 文件事件处理器 时间事件处理器 使用数据库来保存键值对数据 RDB和AOF持久化 发布与订阅 复制模块 Lua脚本 节点会继续使用redisServer结构保存服务器的状态,redisClient结构保存客户端的状态,集群模式下的数据,保存在cluster.h/clusterNode、cluster.h/clusterLink、cluster.h/clusterState结构中。 集群数据结构cluster.h/clusterNode保存了一个节点的当前状态,如节点的创建时间、名字、配置纪元、IP和端口等。每个节点都有一个自己的clus...

2022-02-23
3 分析图形
分析图形基础处理分析图形的结构 G 可以使用各种图论函数进行分析,例如: 123456789G = nx.Graph()G.add_edges_from([(1, 2), (1, 3)])G.add_node("spam") # adds node "spam"list(nx.connected_components(G))[{1, 2, 3}, {'spam'}]sorted(d for n, d in G.degree())[0, 1, 1, 2]nx.clustering(G){1: 0, 2: 0, 3: 0, 'spam': 0} 一些具有大输出的函数迭代(节点、值)2元组。这些很容易存储在 dict 结构,如果你愿意的话。 123sp = dict(nx.all_pairs_shortest_path(G))sp[3]{3: [3], 1: [3, 1], 2: [3, 1, 2]} 图算法

2021-09-02
1-etcd快速入门
原文: 《etcd 快速入门》 .1 认识etcd.1.1 etcd 概念从哪里说起呢?官网第一个页面,有那么一句话:”A distributed, reliable key-value store for the most critical data of a distributed system”。也就是说 etcd 是一个分布式、可靠 key-value 存储的分布式系统。当然,它不仅仅用于存储,还提供共享配置及服务发现。 .1.2 etcd vs Zookeeper提供配置共享和服务发现的系统比较多,其中最为大家熟知的是 Zookeeper,而 etcd 可以算得上是后起之秀了。在项目实现、一致性协议易理解性、运维、安全等多个维度上,etcd 相比 zookeeper 都占据优势。 本文选取 Zookeeper 作为典型代表与 etcd 进行比较,而不考虑 Consul 项目作为比较对象,因为 Consul 的可靠性和稳定性还需要时间来验证(项目发起方自身服务并未使用 Consul,自己都不用)。 一致性协议: etcd 使用 Raft 协议,Zookeeper 使用 ...

2021-03-22
45 分布式RPC框架-参数服务器
使用分布式 RPC 框架实现参数服务器 原文:https://pytorch.org/tutorials/intermediate/rpc_param_server_tutorial.html 作者: Rohan Varma 先决条件: PyTorch 分布式概述 RPC API 文档 本教程介绍了一个简单的示例,该示例使用 PyTorch 的分布式 RPC 框架实现参数服务器。 参数服务器框架是一种范例,其中一组服务器存储参数(例如大型嵌入表),并且多个训练人员查询参数服务器以检索最新参数。 这些训练器可以在本地运行训练循环,并偶尔与参数服务器同步以获得最新参数。 有关参数服务器方法的更多信息,请查阅本文。 使用分布式 RPC 框架,我们将构建一个示例,其中多个训练器使用 RPC 与同一个参数服务器进行通信,并使用 RRef 访问远程参数服务器实例上的状态。 每位训练器将通过使用分布式 Autograd 跨多个节点拼接 Autograd 图,以分布式方式启动其专用的反向传递。 注意:本教程介绍了分布式 RPC 框架的用法,该方法可用于将模型拆分到多台计算机上,或用于实现参...
2020-01-02
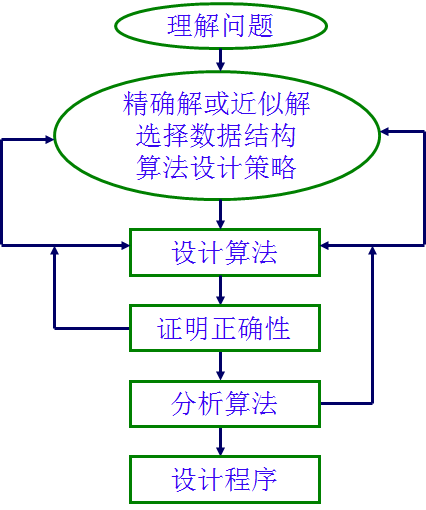
1 算法概述
算法概述 参考文献 八种算法思想 1 基本概念定义 算法是一系列解决问题的清晰指令,对于符合一定规范的输入,算法能够在有限时间内获得所要求的输出。算法是解决问题的一种方法或过程,它是由若干条指令组成的有穷序列。 算法本质上不是数学,而是逻辑。 特征 输入:有零或多个外部量作为算法的输入。 输出:算法产生至少一个量作为输出。 确定性:组成算法的每条指令清晰、无歧义。 有效性:算法中执行的任何计算步骤都是可以被分解为基本的可执行的操作步。 有限性:算法中每条指令的执行次数有限,执行每条指令的时间也有限。 算法的描述 算法的描述方式:自然语言、流程图、伪代码 算法的正确性证明方式:归纳法 算法分析:正确性分析、效率分析、复杂度分析 算法的终极目标 次序order:先做什么、后做什么。前边对后边有影响。 选择if-else:要做什么、不做什么。合并相同的类别,减少分类讨论的情况。 重复while-for:一直做什么。提取相同子结构、相同子操作,进行重复利用。可以通过递归实现重复。 整理说明 以算法结尾,代表的是某一系列或者某一类通用的算法。不依赖于具体的问题。通常可以解决很...




