
6.8 堆树
堆
- 二叉搜索树、多路搜索树都是左小右大。堆树是上下大小不一样。
- 二叉搜索树是从根节点向叶子节点构造。进行插入。堆树是从叶子节点,向根节点进行构造。
参考文献
1 简介
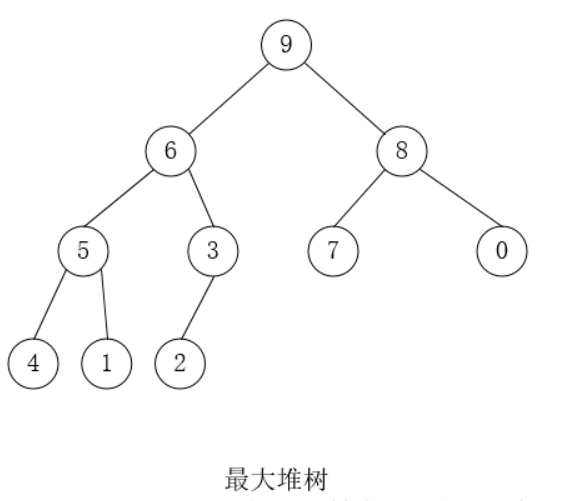
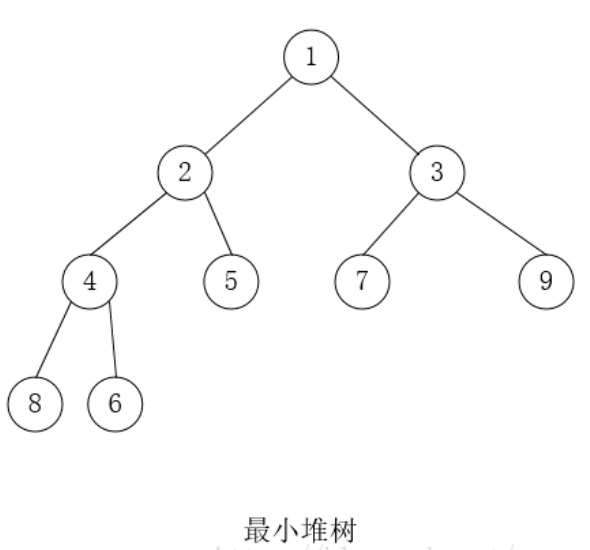
- 堆是一颗完全二叉树;
- 堆中的某个结点的值总是大于等于(最大堆)或小于等于(最小堆)其孩子结点的值。
- 堆中每个结点的子树都是堆树。
因为堆的第三条性质,堆的每一个子树,都是一个堆树。如果从叶节点开始进行一次向上调整。虽然能够保证最大值上浮到根节点。但是却无法保证它是一个堆树。因为进行一次向上调整。根节点的子树也许不是堆树。
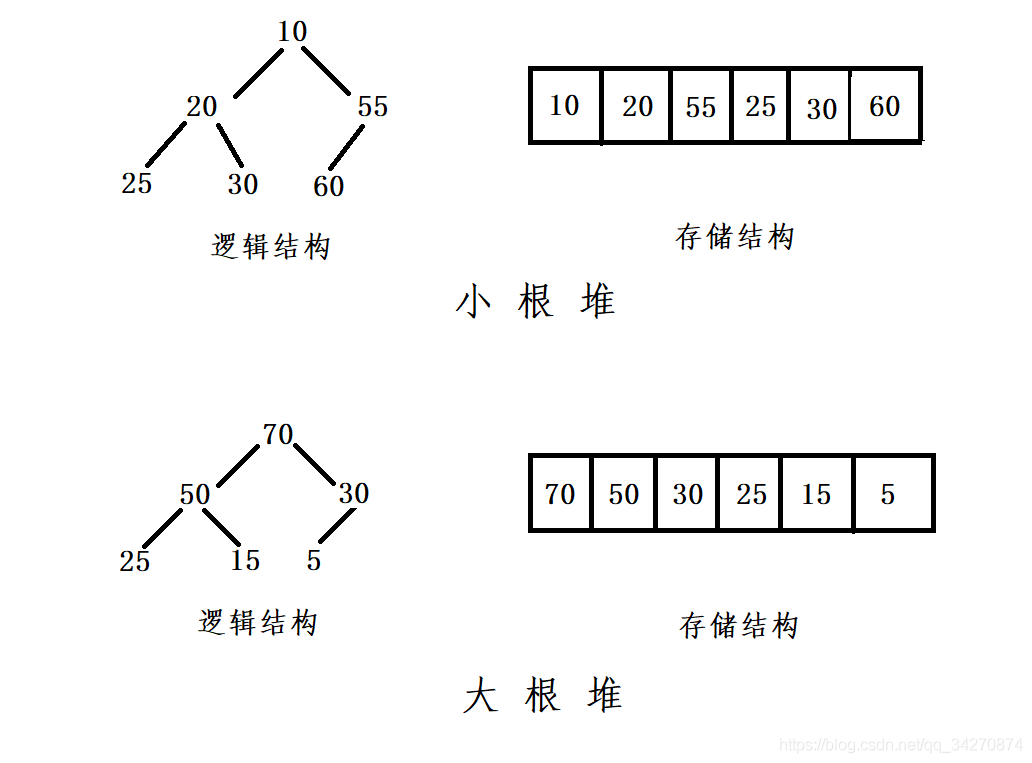
- 使用数组表示的堆树
应用
- 堆结构的一个常见应用是建立优先队列(Priority Queue)。
- 普通树占用的内存空间比它们存储的数据要多。你必须为节点对象以及左/右子节点指针分配内存。堆仅仅使用一个数组来存储数组,且不使用指针。
2 操作
基本操作
- 上浮
- 下沉
- 取顶
- 创建:把一个乱序的数组变成堆结构的数组,时间复杂度为 $O(n)$
- 插入:把一个数值放进已经是堆结构的数组中,并保持堆结构,时间复杂度为 $O(log N)$
- 删除:从最大堆中取出最大值或从最小堆中取出最小值,并将剩余的数组保持堆结构,时间复杂度为 $O(log N)$。
- 堆排序:借由 HEAPFY 建堆和 HEAPPOP 堆数组进行排序,时间复杂度为$O(N log N)$,空间复杂度为 $O(1)$。
上浮-向上调整
最小堆为例
向上调整 是让调整的结点与其父亲结点进行比较。从当前节点递归处理到根节点。
- 先设定倒数的第一个叶子节点为当前节点(通过下标获取,标记为cur),找出他的父亲节点,用parent来标记。
- 比较parent和cur的值,如果cur比parent小,则不满足小堆的规则,需要进行交换。
- 如果cur比parent大,满足小堆的规则,不需要交换,调整结束。
- 处理完一个节点之后,从当前的parent出发,循环之前的过程。
向上调整算法 小堆
向上调整算法 大堆
上浮能够保证路径上最好的值,上浮到根节点。
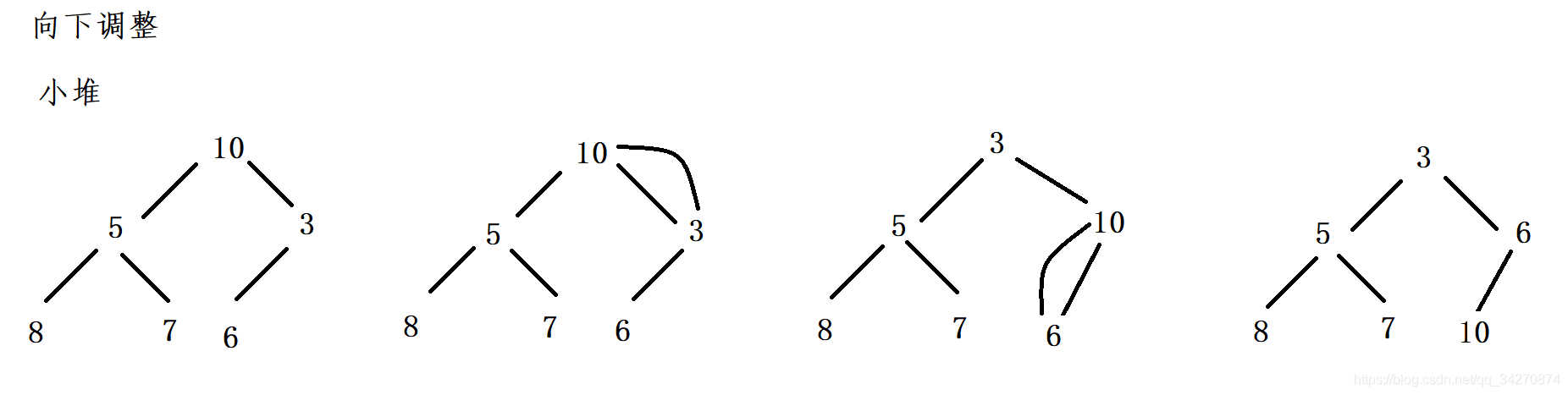
下沉-向下调整
最小堆为例
向下调整 是让调整的结点与其孩子节点进行比较。从当前节点递归处理到叶节点。
- 先设定根节点为当前节点(通过下标获取,标记为cur),比较左右子树的值,找出更小的值,用child来标记。
- 比较child和cur的值,如果child比cur小,则不满足小堆的规则,需要进行交换。
- 如果child比cur大,满足小堆的规则,不需要交换,调整结束。
- 处理完一个节点之后,从当前的child出发,循环之前的过程
向下调整(小堆)示例:
- 向下调整(大堆)示例:
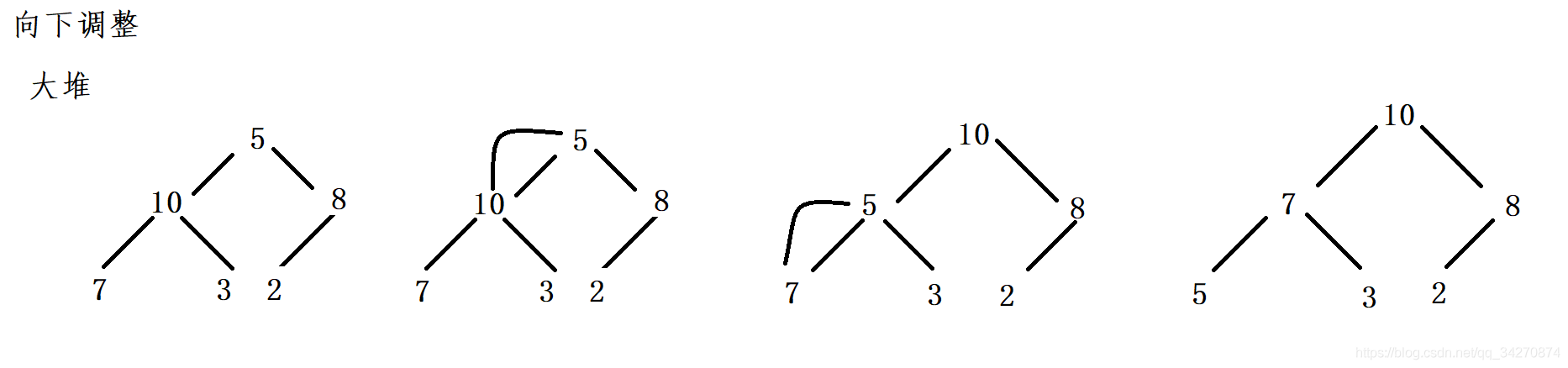
- 下沉不能保证路径上最坏的值下放到叶节点。
创建
类似于冒泡的思想,但是是一中更快的冒泡。保证最后能够建立最好的堆。
- 从根节点向叶节点开始,从前往后开始。进行多次上浮操作。
- 从后往前第一个非叶节点开始。进行多次下沉操作。
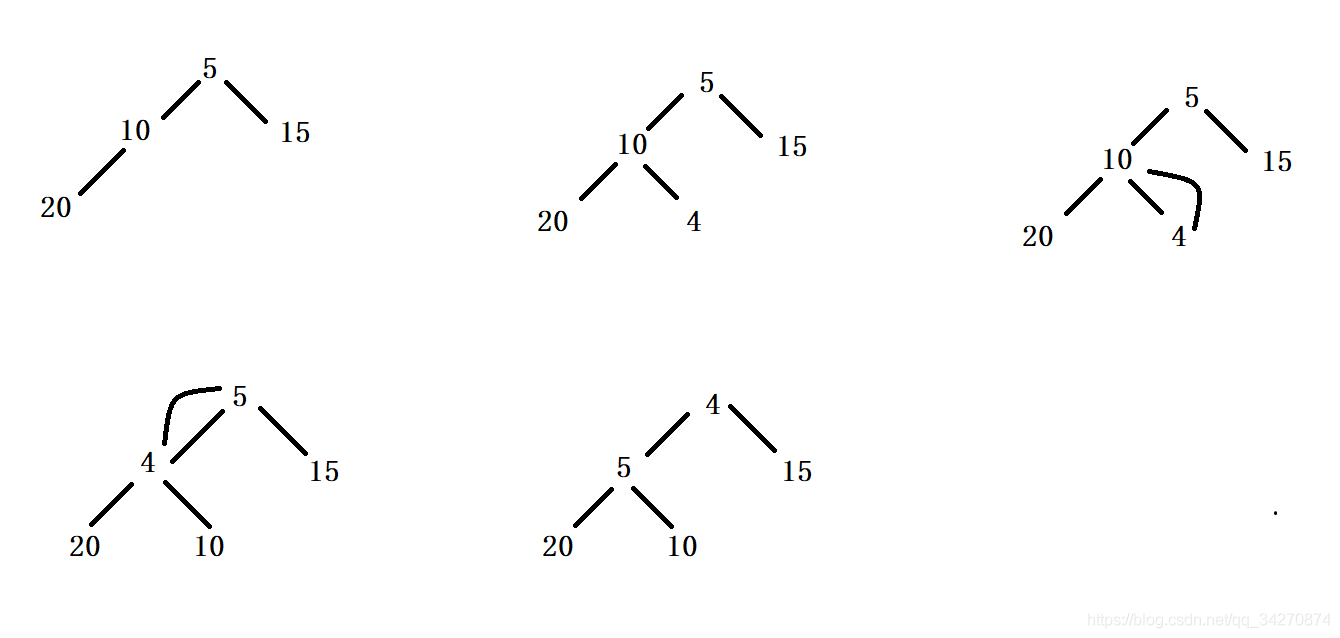
插入(堆尾的数据)
- 将数据插入到数组最后,再进行向上调整。
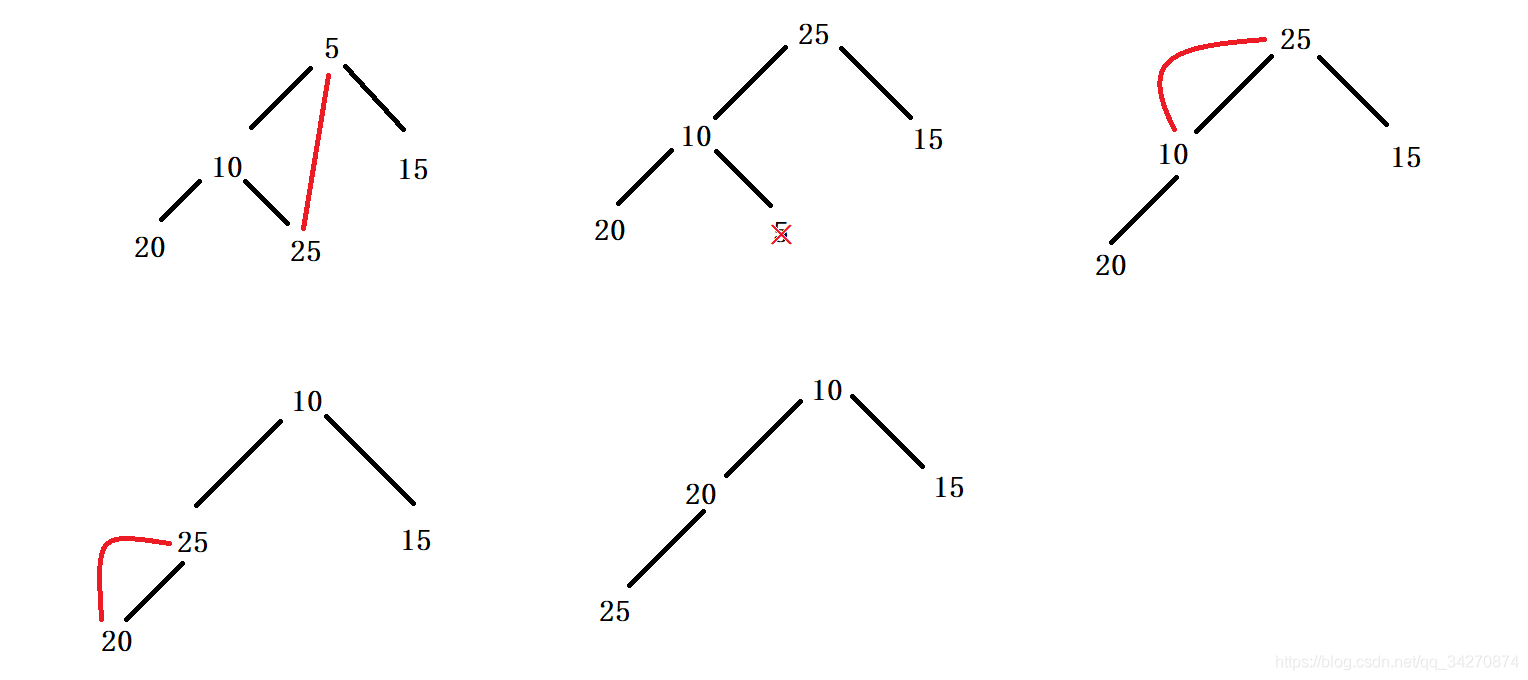
删除(堆顶的数据)
- 删除堆是删除堆顶的数据。将堆顶的数据和最后一个数据交换,然后删除数组最后一个数据,再进行向下调整算法
堆排序
- 堆排序
- 将待排序序列构造成一个大顶堆。
- 此时,整个序列的最大值就是堆顶的根节点。
- 将其与末尾元素进行交换,此时末尾就为最大值。
- 然后将剩余n-1个元素重新构造成一个堆(从根节点开始进行一次向下调整),这样会得到n-1个元素的次小值。如此反复执行,便能得到一个有序序列了。
3 堆的实现
1 |
|
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐
2021-03-20
11
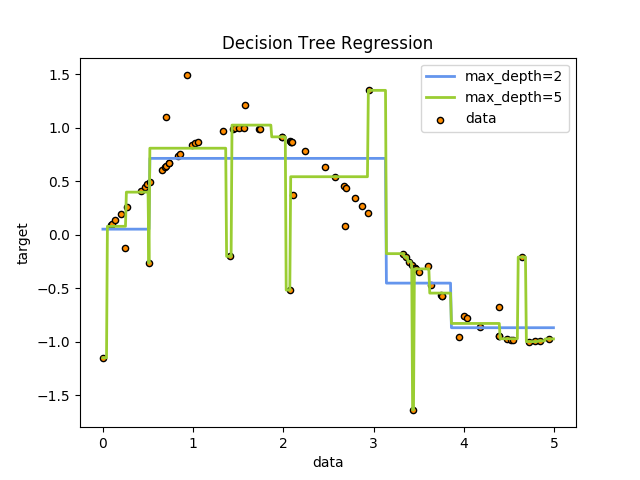
1.10. 决策树校验者: @文谊 @皮卡乒的皮卡乓 @Loopy翻译者: @I Remember Decision Trees (DTs) 是一种用来 classification 和 regression 的无参监督学习方法。其目的是创建一种模型从数据特征中学习简单的决策规则来预测一个目标变量的值。 例如,在下面的图片中,决策树通过if-then-else的决策规则来学习数据从而估测数一个正弦图像。决策树越深入,决策规则就越复杂并且对数据的拟合越好。 决策树的优势: 便于理解和解释。树的结构可以可视化出来。 训练需要的数据少。其他机器学习模型通常需要数据规范化,比如构建虚拟变量和移除缺失值,不过请注意,这种模型不支持缺失值。 由于训练决策树的数据点的数量导致了决策树的使用开销呈指数分布(训练树模型的时间复杂度是参与训练数据点的对数值)。 能够处理数值型数据和分类数据。其他的技术通常只能用来专门分析某一种变量类型的数据集。详情请参阅算法。 能够处理多路输出的问题。 使用白盒模型。如果某种给定的情况在该模型中是...
2022-01-08
5 图神经网络的综述
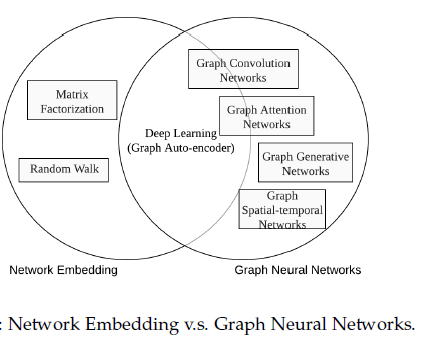
图神经网络的综述主要是对图神经网络的综述,包括各种类型的图神经网络。 0 概述发展原因 计算资源的快速发展(如GPU) 大量训练数据的可用性 深度学习从欧氏空间数据中提取潜在特征的有效性 图嵌入和图神经网络的关系图神经网络的研究与图嵌入或网络嵌入密切相关,图嵌入或网络嵌入是数据挖掘和机器学习界日益关注的另一个课题。 图嵌入旨在通过保留图的网络拓扑结构和节点内容信息,将图中顶点表示为低维向量,以便使用简单的机器学习算法(例如,支持向量机分类)进行处理。许多图嵌入算法通常是无监督的算法,它们可以大致可以划分为三个类别,即矩阵分解、随机游走和深度学习方法。同时图嵌入的深度学习方法也属于图神经网络,包括基于图自动编码器的算法(如DNGR和SDNE)和无监督训练的图卷积神经网络(如GraphSage)。 1 根据神经网络的类型进行分类主要有以下六种: 图卷积网络(Graph Convolution Networks,GCN)、 图递归网络GRNN、 图注意力网络(Graph Attention Networks)、 图自编码器( Graph Autoencoders)、 图生成网络(...

2020-09-25
6广播机制
广播广播(Broadcast)是 numpy 对不同形状(shape)的数组进行数值计算的方式, 对数组的算术运算通常在相应的元素上进行。 低纬度向高维度广播。低纬度在高维度方向上复制。 123456789101112131415import numpy as np a = np.array([[ 0, 0, 0], [10,10,10], [20,20,20], [30,30,30]])b = np.array([1,2,3])bb = np.tile(b, (4, 1)) # 重复 b 的各个维度print(a + bb)输出结果为:[[ 1 2 3] [11 12 13] [21 22 23] [31 32 33]] 广播原则广播的规则: 让所有输入数组都向其中形状最长的数组看齐,形状中不足的部分都通过在前面加 1 补齐。 输出数组的形状是输入数组形状的各个维度上的最大值。 如果输入数组的某个维度和输出数组的对应维度的长度相同或者其长度为 1 时,这个数组能够用来计算,否则出错。 当输入数组的某个维度的...
2023-09-09
08 Pod网络
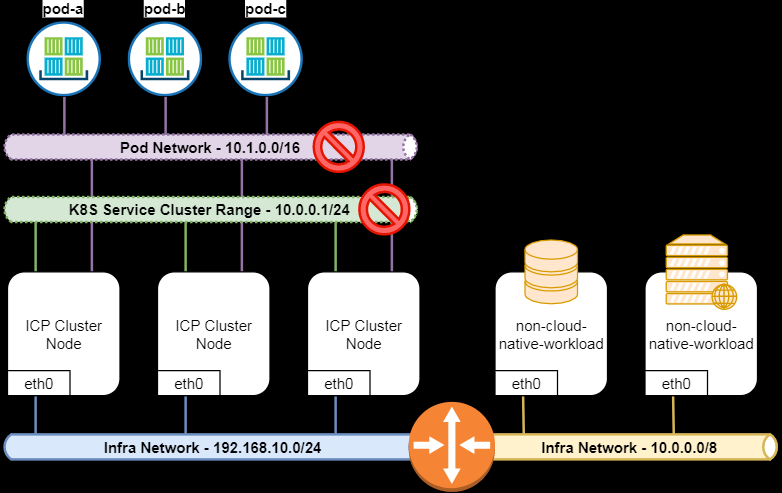
容器网络网络类型 Node Network: 外部网络接口。集群节点所在的网络,这个网络就是你的主机所在的网络,通常情况下是你的网络基础设施提供。如果node处于不同的网段,那么你需要保证路由可达。如上图中的 192.168.10.0/24和10.0.0.0/8这两个网络 Service Network:K8S服务网络,ipvs规则当中的网络,由特定组件提供路由和调度。 service_cluster_ip_range(如图,默认的配置是的10.0.0.1/24)。在上图中,扩充的节点(基础网络是10.0.0.0/8)和 服务网络(10.0.0.1/24)冲突,会造网络问题。 Pod Network: 节点当中pod的内部网络无法与外界通信。第三个网络是Pod的网络, K8s中一个Pod由多个容器组成,但是一个pod只有一个IP地址,Pod中所有的容器共享同一个IP。这个IP启动pod时从一个IP池中分配的, 叫做 pod CIDR, 或者叫network_cidr(如图,默认配置是10.1.0.0/16)。 可以在...

2019-10-15
5.2 链路层-多路访问
多路访问控制 参考文献 计算机网络——“自顶向下方法之链路层 计算机网络-链路层 1 概述点对点链路由链路一端的单个发送方和链路另一端的单个接收方组成。使用的协议包括:点对点协议(PPP)、高级数据链路控制(HDLC)。 广播链路多个发送和接受节点都连接到相同的、单一的、共享的广播信道上。多路访问协议用于规范节点在共享的广播信道上的传输行为。 多路访问控制(multiple access control protocol,MAC)协议可以分为三类——信道划分协议,随机接入协议和轮流协议。 TDM和FDM都是信道划分协议,而CDMA则是码分多址,如果配置恰当,可以同时接收节点而不被干扰。 随机接入协议在每一次碰撞后等待随机时间再发。时隙ALOHA是一个很简单的随机接入协议,而AHOHA效率是时隙ALOHA的一半。载波侦听多路访问(CSMA)会在开始之前监测是否有人说话,而如果其他人同时开始说话,则停下。 轮流协议轮效率低下,若调配节点出问题则崩盘。轮流协议包括令牌协议。 2 MAC-信道划分协议TDM时分多路复用(TDM),将时间划分为时间帧,并进一步划分每个时间帧...
2022-02-23
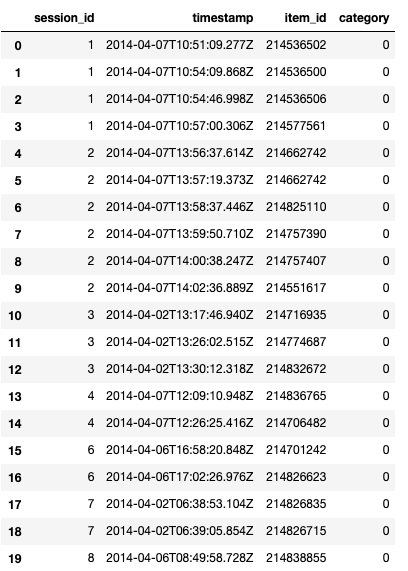
3 训练
1 图分类示例创建数据集1234567891011121314151617181920212223242526import torchfrom torch_geometric.datasets import TUDatasetdataset = TUDataset('/home/ykl/TUDataset', name = 'MUTAG')print()print(f'Dataset: {dataset}:')print('====================')print(f'Number of graphs: {len(dataset)}')print(f'Number of features: {dataset.num_features}')print(f'Number of classes: {dataset.num_classes}')data = ...




