
1 查找问题
1 该类问题的第一个子问题
问题分析
1.1 该类问题的第一个子问题——第一种方法
问题分析
策略选择
算法设计
算法分析
算法实现
1.2 该类问题的第一个子问题——第二中方法
策略选择
算法设计
算法分析
算法实现
该类问题的第三个子问题——第一种方法
问题分析
算法设计
算法分析
算法实现
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2021-03-09
pickle模块
实现文件读写

2022-08-17
14 语法糖
参考文献 1 Java语法糖语法糖(Syntactic Sugar),也叫糖衣语法,是英国计算机科学家彼得·约翰·兰达(Peter J. Landin)发明的一个术语。指的是,在计算机语言中添加某种语法,这种语法能使程序员更方便的使用语言开发程序,同时增强程序代码的可读性,避免出错的机会;但是这种语法对语言的功能并没有影响。 Java中的泛型,变长参数,自动拆箱/装箱,条件编译等都是语法糖。 泛型与C#中的泛型相比,Java的泛型可以算是“伪泛型”了。在C#中,不论是在程序源码中、在编译后的中间语言,还是在运行期泛型都是真实存在的。Java则不同,Java的泛型只在源代码存在,只供编辑器检查使用,编译后的字节码文件已擦除了泛型类型,同时在必要的地方插入了强制转型的代码。泛型代码: 12345public static void main(String[] args) { List<String> stringList = new ArrayList<String>(); stringList.add("oliv...
2022-12-19
05 JUC并发组件
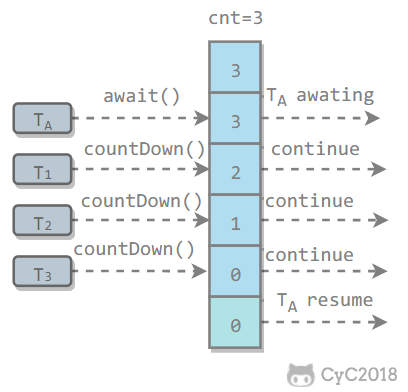
1 J.U.C - AQSjava.util.concurrent(J.U.C)大大提高了并发性能,AQS 被认为是 J.U.C 的核心。 ReentrantLock:lock/unlockReentrantLock 是 java.util.concurrent(J.U.C)包中的锁。 123456789101112131415public class LockExample { private Lock lock = new ReentrantLock(); public void func() { lock.lock(); try { for (int i = 0; i < 10; i++) { System.out.print(i + " "); } } finally { lock.unlock(); // 确保释放锁,...
2021-03-20
21
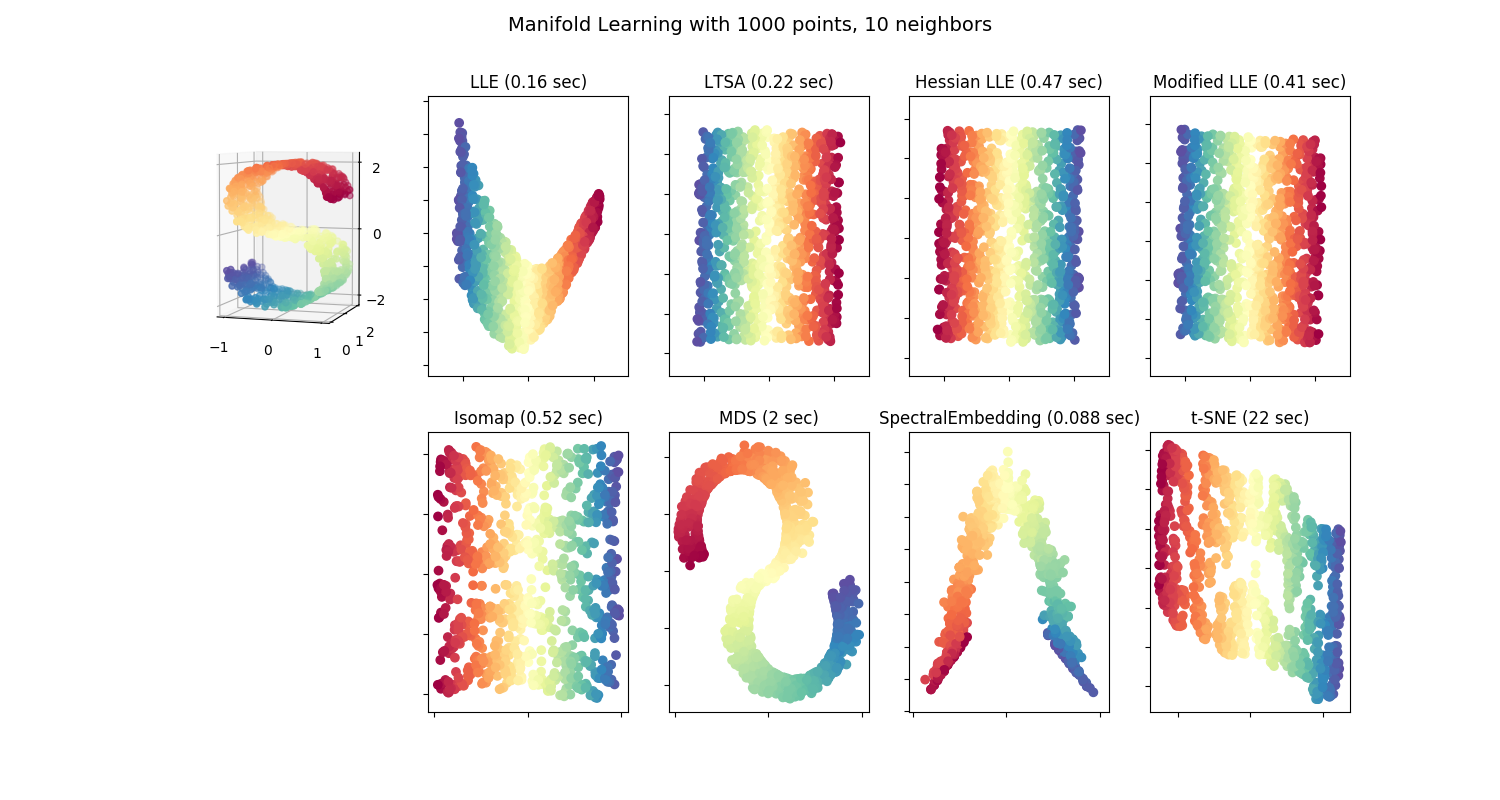
2.2. 流形学习校验者: @XuJianzhi @RyanZhiNie @羊三 @Loopy @barrycg翻译者: @XuJianzhi @羊三 Look for the bare necessities The simple bare necessities Forget about your worries and your strife I mean the bare necessitiesOld Mother Nature’s recipes That bring the bare necessities of life – Baloo的歌 [奇幻森林] 流形学习是一种非线性降维方法。其算法基于的思想是:许多数据集维度过高的现象完全是人为导致得。 2.2.1. 介绍高维数据集通常难以可视化。虽然,可以通过绘制两维或三维的数据来...
2021-03-09
Prim 最小生成树算法
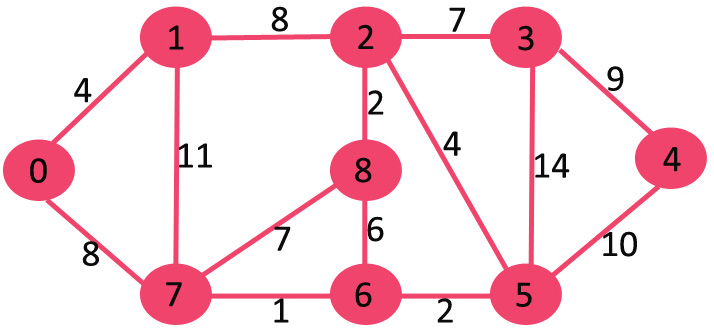
Prim 最小生成树算法 Prim 算法是一种解决**最小生成树问题(Minimum Spanning Tree)**的算法。和Kruskal算法类似,Prim算法的设计也是基于贪心算法(Greedy algorithm)。 Prim算法的思想很简单,一棵生成树必须连接所有的顶点,而要保持最小权重则每次选择邻接的边时要选择较小权重的边。Prim算法看起来非常类似于单源最短路径 Dijkstra算法,从源点出发,寻找当前的最短路径,每次比较当前可达邻接顶点中最小的一个边加入到生成树中。 例如,下面这张连通的无向图 G,包含 9 个顶点和 14条边,所以期待的最小生成树应包含 (9 - 1) = 8 条边。 创建 mstSet 包含到所有顶点的距离,初始为 INF,源点 0 的距离为 0,{0, INF, INF,INF, INF, INF, INF, INF, INF}。 选择当前最短距离的顶点,即还是顶点 0,将 0 加入 MST,此时邻接顶点为 1 和 7。 选择当前最小距离的顶点 1,将 1 加入 MST,此时邻接顶点为 2。 选择 2 和 7 中最小距离的顶...
2021-03-22
41 单机模型并行
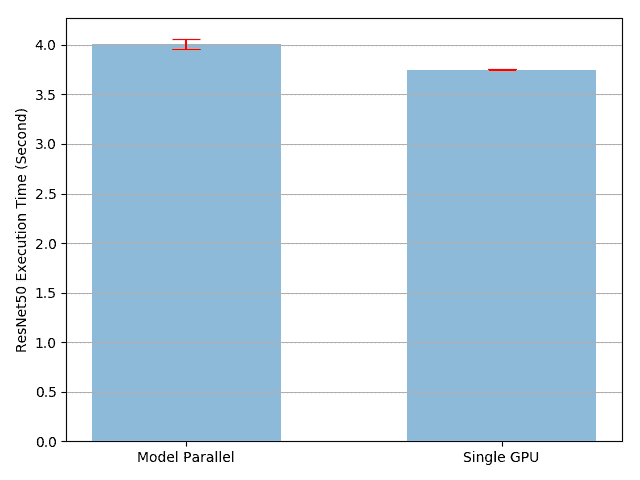
单机模型并行最佳实践 原文:https://pytorch.org/tutorials/intermediate/model_parallel_tutorial.html 作者:Shen Li 模型并行在分布式训练技术中被广泛使用。 先前的帖子已经解释了如何使用DataParallel在多个 GPU 上训练神经网络; 此功能将相同的模型复制到所有 GPU,其中每个 GPU 消耗输入数据的不同分区。 尽管它可以极大地加快训练过程,但不适用于模型太大而无法容纳单个 GPU 的某些用例。 这篇文章展示了如何通过使用模型并行解决该问题,与DataParallel相比,该模型将单个模型拆分到不同的 GPU 上,而不是在每个 GPU 上复制整个模型(具体来说, 假设模型m包含 10 层:使用DataParallel时,每个 GPU 都具有这 10 层中的每一个的副本,而当在两个 GPU 上并行使用模型时,每个 GPU 可以承载 5 层。 模型并行化的高级思想是将模型的不同子网放置在不同的设备上,并相应地实现forward方法以在设备之间移动中间输出。 由于模型的一部分仅在任何单个设备上运行...




