
SUMMARY
- 其他示例
- 双聚类
- 校准
- 分类
- 多聚类
- 协方差估计
- 交叉分解
- 数据集示例
- 决策树
- 分解
- 集成方法
- 基于真实数据集的示例
- 特征选择
- 高斯混合模型
- 高斯机器学习过程
- 广义线性模型
- 检查
- 流行学习
- 缺失值插补
- 选型
- 多输出方法
- 最近邻
- 神经网络
- 管道和复合估计器
- 预处理
- 发布要点
- 半监督分类
- 支持向量机
- 建成练习
- 文本文档工作
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2020-01-05
4.2 大整数乘法问题
大整数乘法 参考文献 大数乘法的问题及其高效的算法 问题描述 题目描述: 输出两个不超过100位的大整数的乘积。 输入: 输入两个大整数,如1234567 和 123 输出: 输出乘积,如:151851741 数字以字符串的形式给出。 1求 1234567891011121314151617181920 * 2019181716151413121110987654321 的乘积结果 问题分析 所谓大数相乘(Multiplication algorithm),就是指数字比较大,相乘的结果超出了基本类型的表示范围,所以这样的数不能够直接做乘法运算。参考了很多资料,包括维基百科词条Multiplication algorithm,才知道目前大数乘法算法主要有以下几种思路: 模拟小学乘法:最简单的乘法竖式手算的累加型; 分治乘法:最简单的是Karatsuba乘法,一般化以后有Toom-Cook乘法; 快速傅里叶变换FFT:(为了避免精度问题,可以改用快速数论变换FNTT),时间复杂度O(N lgN lglgN)。具体可参照Schönhage–Strassen algorith...

2021-03-20
plot_multi_task_lasso_support
多任务Lasso实现联合特征选择 翻译者:@Loopy校验者:@barrycg 多任务lasso允许多元回归问题上进行合并训练,并在多个任务间强制选择相同的特征。这个示例模拟了部分序列测量,每个任务都是即时的,并且相关的特征幅值趋向相同时,又会随时间变化而震动。多任务lasso强制要求在一个时间点选择的特征必需适用于所有时间点。这使得多任务LASSO的特征选择更加稳定。 1234import matplotlib.pyplot as pltimport numpy as npfrom sklearn.linear_model import MultiTaskLasso, Lasso 123456789101112131415rng = np.random.RandomState(42)# 使用具有随机频率和相位的正弦波生成二维系数n_samples, n_features, n_tasks = 100, 30, 40n_relevant_features = 5coef = np.zeros((n_tasks, n_features))times = np.linspace...
2023-08-15
01 简介
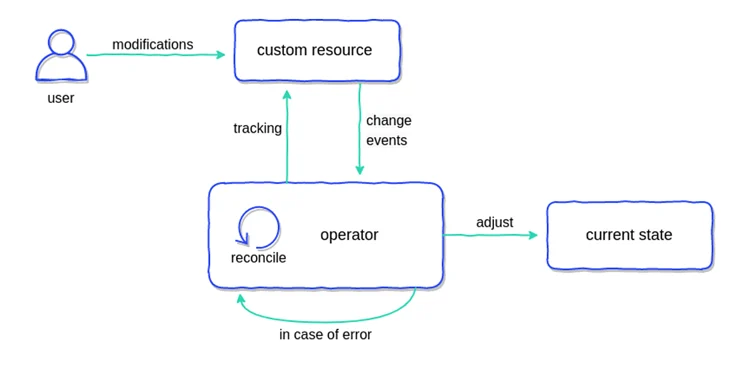
基本介绍简介Operator 是由 CoreOS 开发的,用来扩展 Kubernetes API,特定的应用程序控制器,它用来创建、配置和管理复杂的有状态应用,如数据库、缓存和监控系统。Operator 基于 Kubernetes 的资源和控制器概念之上构建,但同时又包含了应用程序特定的领域知识。创建Operator 的关键是CRD(自定义资源)的设计。 Operator 直接使用 Kubernetes API进行开发,也就是说他们可以根据这些控制器内部编写的自定义规则来监控集群、更改 Pods/Services、对正在运行的应用进行扩缩容。 Operator pattern首先由 CoreOS 提出,通过结合 CRD 和 custom controller 将特定应用的运维知识转换为代码,实现应用运维的自动化和智能化。Operator 允许 kubernetes 来管理复杂的,有状态的分布式应用程序,并由 kubernetes 对其进行自动化管理,例如,etcd operator 能够创建并管理一组 etcd 集群, 定制化的 controller 组件了解这些资源,...
2022-07-23
03 JDBCTemplate
Data Access简介概述DataAccess模块主要包括 JDBC ORM OXM JDBCTemplate对JDBC进行封装,很方便的实现对数据库进行操作。 自己开发项目也应该这样做。首先进行设计,把接口、实现、属性、方法定义好。遵循从上到下的设计。然后进行开发,根据具体的业务逻辑实现方法的内容。遵循从下到上的开发。 准备工作 引入相关的jar包 数据库连接池 1234567<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource"> <property name="driverClassName" value="com.mysql.jdbc.Driver"></property> <property name="url" value="jdbc:mysql://localhost:3310/user">...

2020-09-26
cursor_demo_sgskip
光标演示此示例显示如何使用matplotlib提供数据游标。 它使用matplotlib来绘制光标并且可能很慢,因为这需要在每次鼠标移动时重新绘制图形。 使用本机GUI绘图可以更快地进行镜像,就像在wxcursor_demo.py中一样。 mpldatacursor和mplcursors第三方包可用于实现类似的效果。参看这个: https://github.com/joferkington/mpldatacursor https://github.com/anntzer/mplcursors 12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970import matplotlib.pyplot as pltimport numpy as npclass Cursor(object): def __init__(self, ax): self.ax = ax...
2021-03-22
41 单机模型并行
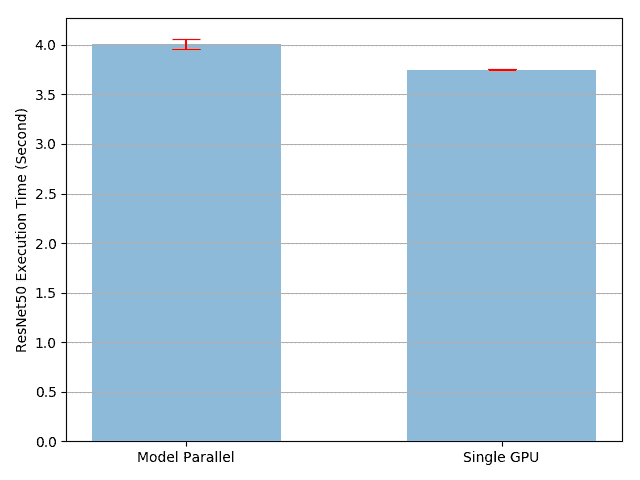
单机模型并行最佳实践 原文:https://pytorch.org/tutorials/intermediate/model_parallel_tutorial.html 作者:Shen Li 模型并行在分布式训练技术中被广泛使用。 先前的帖子已经解释了如何使用DataParallel在多个 GPU 上训练神经网络; 此功能将相同的模型复制到所有 GPU,其中每个 GPU 消耗输入数据的不同分区。 尽管它可以极大地加快训练过程,但不适用于模型太大而无法容纳单个 GPU 的某些用例。 这篇文章展示了如何通过使用模型并行解决该问题,与DataParallel相比,该模型将单个模型拆分到不同的 GPU 上,而不是在每个 GPU 上复制整个模型(具体来说, 假设模型m包含 10 层:使用DataParallel时,每个 GPU 都具有这 10 层中的每一个的副本,而当在两个 GPU 上并行使用模型时,每个 GPU 可以承载 5 层。 模型并行化的高级思想是将模型的不同子网放置在不同的设备上,并相应地实现forward方法以在设备之间移动中间输出。 由于模型的一部分仅在任何单个设备上运行...




