# 1.1. 广义线性模型
校验者:
[@专业吹牛逼的小明](https://github.com/apachecn/scikit-learn-doc-zh)
[@Gladiator](https://github.com/apachecn/scikit-learn-doc-zh)
[@Loopy](https://github.com/loopyme)
[@qinhanmin2014](https://github.com/qinhanmin2014)
翻译者:
[@瓜牛](https://github.com/apachecn/scikit-learn-doc-zh)
[@年纪大了反应慢了](https://github.com/apachecn/scikit-learn-doc-zh)
[@Hazekiah](https://github.com/apachecn/scikit-learn-doc-zh)
[@BWM-蜜蜂](https://github.com/apachecn/scikit-learn-doc-zh)
本章主要讲述一些用于回归的方法,其中目标值 y 是输入变量 x 的线性组合。 数学概念表示为:如果 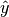 是预测值,那么有:
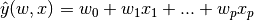
在整个模块中,我们定义向量 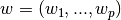 作为 `coef_` ,定义 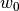 作为 `intercept_` 。
如果需要使用广义线性模型进行分类,请参阅 [logistic 回归](#1111-logistic-回归) 。
## 1.1.1. 普通最小二乘法
[`LinearRegression`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html#sklearn.linear_model.LinearRegression) 拟合一个带有系数 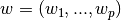 的线性模型,使得数据集实际观测数据和预测数据(估计值)之间的残差平方和最小。其数学表达式为:
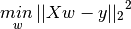
[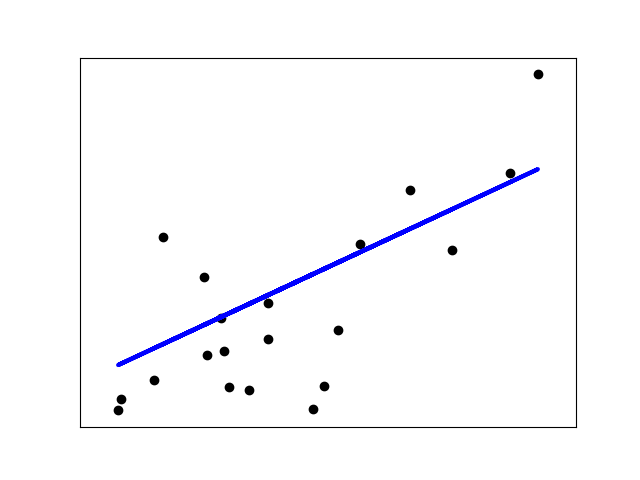](https://scikit-learn.org/stable/auto_examples/linear_model/plot_ols.html)
[`LinearRegression`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html#sklearn.linear_model.LinearRegression) 会调用 `fit` 方法来拟合数组 X, y,并且将线性模型的系数 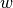 存储在其成员变量 `coef_` 中:
1 2 3 4 5 6 7 >>> from sklearn import linear_model>>> reg = linear_model.LinearRegression()>>> reg.fit ([[0 , 0 ], [1 , 1 ], [2 , 2 ]], [0 , 1 , 2 ])LinearRegression(copy_X=True , fit_intercept=True , n_jobs=1 , normalize=False ) >>> reg.coef_array([ 0.5 , 0.5 ])
该方法使用 X 的奇异值分解来计算最小二乘解。如果 X 是一个形状为 (n_samples, n_features)的矩阵,设 $$ n_{samples} \geq n_{features} $$ , 则该方法的复杂度为 $$ O(n_{samples} n_{fearures}^2) $$
## 1.1.2. 岭回归
[`Ridge`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html#sklearn.linear_model.Ridge) 回归通过对系数的大小施加惩罚来解决 [普通最小二乘法](#1111-普通最小二乘法复杂度) 的一些问题。 岭系数最小化的是带罚项的残差平方和,
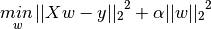
其中, 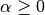 是控制系数收缩量的复杂性参数: 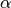 的值越大,收缩量越大,模型对共线性的鲁棒性也更强。
[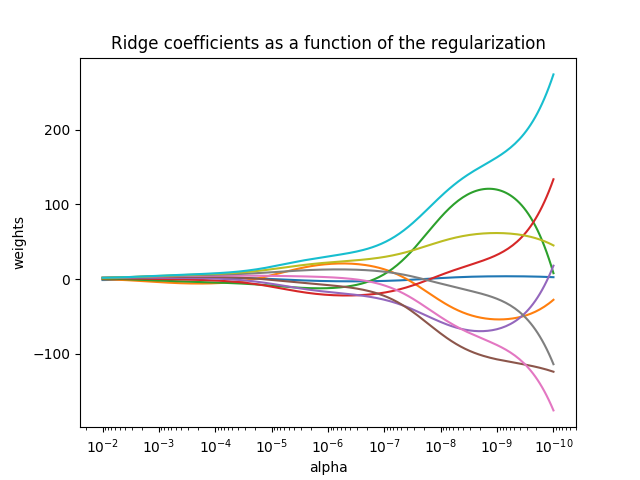](https://scikit-learn.org/stable/auto_examples/linear_model/plot_ridge_path.html)
与其他线性模型一样, [`Ridge`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html#sklearn.linear_model.Ridge) 用 `fit` 方法完成拟合,并将模型系数 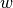 存储在其 `coef_` 成员中:
1 2 3 4 5 6 7 8 9 10 >>> from sklearn import linear_model>>> reg = linear_model.Ridge (alpha = .5 )>>> reg.fit ([[0 , 0 ], [0 , 0 ], [1 , 1 ]], [0 , .1 , 1 ])Ridge(alpha=0.5 , copy_X=True , fit_intercept=True , max_iter=None , normalize=False , random_state=None , solver='auto' , tol=0.001 ) >>> reg.coef_array([ 0.34545455 , 0.34545455 ]) >>> reg.intercept_0.13636 ...
1 2 3 4 5 6 7 8 >>> from sklearn import linear_model>>> reg = linear_model.RidgeCV(alphas=[0.1 , 1.0 , 10.0 ])>>> reg.fit([[0 , 0 ], [0 , 0 ], [1 , 1 ]], [0 , .1 , 1 ]) RidgeCV(alphas=[0.1 , 1.0 , 10.0 ], cv=None , fit_intercept=True , scoring=None , normalize=False ) >>> reg.alpha_ 0.1
1 2 3 4 5 6 7 8 9 >>> from sklearn import linear_model>>> reg = linear_model.Lasso(alpha = 0.1 )>>> reg.fit([[0 , 0 ], [1 , 1 ]], [0 , 1 ])Lasso(alpha=0.1 , copy_X=True , fit_intercept=True , max_iter=1000 , normalize=False , positive=False , precompute=False , random_state=None , selection='cyclic' , tol=0.0001 , warm_start=False ) >>> reg.predict([[1 , 1 ]])array([ 0.8 ])
1 2 3 4 5 6 7 8 9 >>> from sklearn import linear_model>>> reg = linear_model.LassoLars(alpha=.1 )>>> reg.fit([[0 , 0 ], [1 , 1 ]], [0 , 1 ]) LassoLars(alpha=0.1 , copy_X=True , eps=..., fit_intercept=True , fit_path=True , max_iter=500 , normalize=True , positive=False , precompute='auto' , verbose=False ) >>> reg.coef_ array([0.717157 ..., 0. ])
1 2 3 4 5 6 7 8 9 >>> from sklearn import linear_model>>> X = [[0. , 0. ], [1. , 1. ], [2. , 2. ], [3. , 3. ]]>>> Y = [0. , 1. , 2. , 3. ]>>> reg = linear_model.BayesianRidge()>>> reg.fit(X, Y)BayesianRidge(alpha_1=1e-06 , alpha_2=1e-06 , compute_score=False , copy_X=True , fit_intercept=True , lambda_1=1e-06 , lambda_2=1e-06 , n_iter=300 , normalize=False , tol=0.001 , verbose=False )
1 2 3 >>> reg.predict ([[1 , 0. ]])array([ 0.50000013 ])
1 2 3 >>> reg.coef_array([ 0.49999993 , 0.49999993 ])
1 2 3 4 5 6 7 8 9 10 11 12 13 >>> from sklearn.preprocessing import PolynomialFeatures>>> import numpy as np>>> X = np.arange(6 ).reshape(3 , 2 )>>> Xarray([[0 , 1 ], [2 , 3 ], [4 , 5 ]]) >>> poly = PolynomialFeatures(degree=2 )>>> poly.fit_transform(X)array([[ 1. , 0. , 1. , 0. , 0. , 1. ], [ 1. , 2. , 3. , 4. , 6. , 9. ], [ 1. , 4. , 5. , 16. , 20. , 25. ]])
1 2 3 4 5 6 7 8 9 10 11 12 13 >>> from sklearn.preprocessing import PolynomialFeatures>>> from sklearn.linear_model import LinearRegression>>> from sklearn.pipeline import Pipeline>>> import numpy as np>>> model = Pipeline([('poly' , PolynomialFeatures(degree=3 )),... ('linear' , LinearRegression(fit_intercept=False ))])>>> >>> x = np.arange(5 )>>> y = 3 - 2 * x + x ** 2 - x ** 3 >>> model = model.fit(x[:, np.newaxis], y)>>> model.named_steps['linear' ].coef_array([ 3. , -2. , 1. , -1. ])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 >>> from sklearn.linear_model import Perceptron>>> from sklearn.preprocessing import PolynomialFeatures>>> import numpy as np>>> X = np.array([[0 , 0 ], [0 , 1 ], [1 , 0 ], [1 , 1 ]])>>> y = X[:, 0 ] ^ X[:, 1 ]>>> yarray([0 , 1 , 1 , 0 ]) >>> X = PolynomialFeatures(interaction_only=True ).fit_transform(X).astype(int )>>> Xarray([[1 , 0 , 0 , 0 ], [1 , 0 , 1 , 0 ], [1 , 1 , 0 , 0 ], [1 , 1 , 1 , 1 ]]) >>> clf = Perceptron(fit_intercept=False , max_iter=10 , tol=None ,... shuffle=False ).fit(X, y)
1 2 3 4 5 >>> clf.predict(X)array([0 , 1 , 1 , 0 ]) >>> clf.score(X, y)1.0