
57
把它们放在一起
模型管道化
我们已经知道一些模型可以做数据转换,一些模型可以用来预测变量。我们可以建立一个组合模型同时完成以上工作:
1 | import numpy as np |
用特征面进行人脸识别
该实例用到的数据集来自 LFW_(Labeled Faces in the Wild)。数据已经进行了初步预处理
1 | """ |
 |
 |
|---|---|
| Prediction | Eigenfaces |
数据集中前5名最有代表性样本的预期结果:
1 | precision recall f1-score support |
开放性问题: 股票市场结构
我们可以预测 Google 在特定时间段内的股价变动吗?
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2021-03-09
error & exception & filter
>error错误处理 >>基本错误处理die(“错误反馈字符串”),能终止当前脚本的执行 [php] view plaincopy <span style=”font-size:14px;”><?php if(!file_exists(“welcome.txt”)) { die(“File not found”); } else { $file=fopen(“welcome.txt”,”r”); } ?></span> >>自定义函数处理错误 >>错误记录 >exception异常处理 >>可能的处理方式: 保存代码退出脚本执行 切换到预先定义好的异常处理函 重新执行代码或者从代码另外的位置继续执行脚本 >>异常的基本使用 步骤:抛出异常 - 捕获异常(对异常进行匹配) - 处理异常 [php] view plaincopy <span style=”font-size:14px;”><?p...

2019-11-30
第23节 距离判别
距离判别 分类:数据集带标签聚类:无标签数据集 1 欧氏距离与马氏距离定义:距离判别 判别分析:根据样品的观察值判定归属。 距离判别原理:对距离进行规定,就近原则判定样品的归属。 定义:欧氏距离$$d(x,y)=\sqrt{\sum_{i=1}^n(x_i-y_i)^2}\=\sqrt{(x-y)’(x-y)}$$ 缺点:指标的量纲不同,意义不同。距离会因各个指标单位的变化而改变 定义:马氏距离 声明$$p元总体G的均值\mu和协方差矩阵\Sigma(\Sigma>0)\x,y是取自G的两个样本$$ 结论$$马氏距离d(x,y)=\sqrt{(x-y)’\Sigma^{-1}(x-y)}$$ 马氏距离与欧氏距离只相差一个协方差矩阵。具体原理的理解放到第二轮复习当中。 性质 非负性:$d(x,y)\geq 0,当且仅当x=y时,d(x,y)=0$ 自反性:$d(x,y)=d(y,x)$ 三角不等式:对任意的$x,y,z$,有$d(x,z)\leqd(x,y)+d(y,z)$ 特点 当$\Si...

2021-09-07
A.5-chinese
A.5 Lambda函数lambda函数在C++11中的加入很是令人兴奋,因为lambda函数能够大大简化代码复杂度(语法糖:利于理解具体的功能),避免实现调用对象。C++11的lambda函数语法允许在需要使用的时候进行定义。能为等待函数,例如std::condition_variable(如同4.1.1节中的例子)提供很好谓词函数,其语义可以用来快速的表示可访问的变量,而非使用类中函数来对成员变量进行捕获。 最简单的情况下,lambda表达式就一个自给自足的函数,不需要传入函数仅依赖管局变量和函数,甚至都可以不用返回一个值。这样的lambda表达式的一系列语义都需要封闭在括号中,还要以方括号作为前缀: 1234[]{ // lambda表达式以[]开始 do_stuff(); do_more_stuff();}(); // 表达式结束,可以直接调用 例子中,lambda表达式通过后面的括号调用,不过这种方式不常用。一方面,如果想要直接调用,可以在写完对应的语句后,就对函数进行调用。对于函数模板,传递一个参数进去时很常见的事情,甚至可以将可调用对象...
2020-09-27
1.机器学习基础
第1章 机器学习基础 参考文献 机器学习实战 ApacheCN机器学习实战笔记 1 机器学习 概述机器学习(Machine Learning,ML) 是使用计算机来彰显数据背后的真实含义,它为了把无序的数据转换成有用的信息。是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。 海量的数据 获取有用的信息 2 机器学习 研究意义机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能”。 “机器学习是对能通过经验自动改进的计算机算法的研究”。 “机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。” 一种经常引用的英文定义是: A computer program is said to learn from experience E with respect to s...
2022-10-08
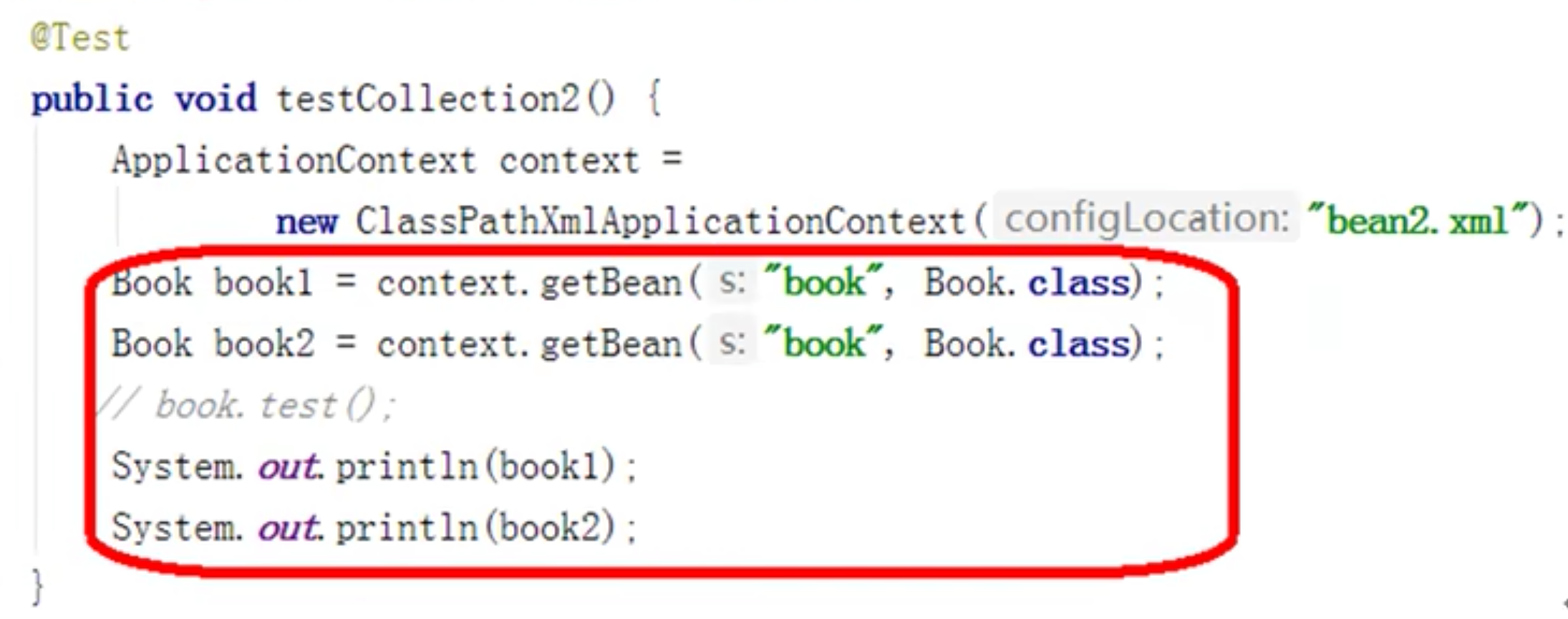
01 2IOC基于XML容器管理
IOCBean管理基于XML方式1 基于XMl方式创建对象1234<bean id="user" class="com.ykl.User"></bean>id:对象唯一标识class:创建对象的类全路径,包类路径name:对象名称标识 在Spring给你配置文件中,使用bean标签,标签里添加对应属性。实现对象的创建 bean中有很多属性 创建对象的时候,执行无参构造函数。 2 基于XML方式注入属性 DI依赖注入,就是注入属性。 原始的属性注入方法123456789101112131415161718192021222324252627282930313233343536/** * Alipay.com Inc. * Copyright (c) 2004-2022 All Rights Reserved. */package com.ykl;/** * @author yinkanglong * @version : Book, v 0.1 2022-10-08 14:32 yinkanglong Exp $...

2021-03-20
41
5.4 缺失值插补校验者: @if only 待二次校验翻译者: @Trembleguy @Loopy 因为各种各样的原因,真实世界中的许多数据集都包含缺失数据,这类数据经常被编码成空格、NaNs,或者是其他的占位符。但是这样的数据集并不能scikit-learn学习算法兼容,因为大多的学习算法都默认假设数组中的元素都是数值,因而所有的元素都有自己的意义。 使用不完整的数据集的一个基本策略就是舍弃掉整行或整列包含缺失值的数据。但是这样就付出了舍弃可能有价值数据(即使是不完整的 )的代价。 处理缺失数值的一个更好的策略就是从已有的数据推断出缺失的数值。有关插补(imputation),请参阅常用术语表和API元素条目。 5.4.1 单变量与多变量插补一种类型的插补算法是单变量算法,它只使用第i个特征维度中的非缺失值(如impute.SimpleImputer)来插补第i个特征维中的值。相比之下,多变量插补算法使用整个可用特征维度来估计缺失的值(如impute.IterativeImputer)。 5.4.2 单变量插补Simp...




