
60
选择正确的评估器(estimator)
校验者:
翻译者:
@李孟禹
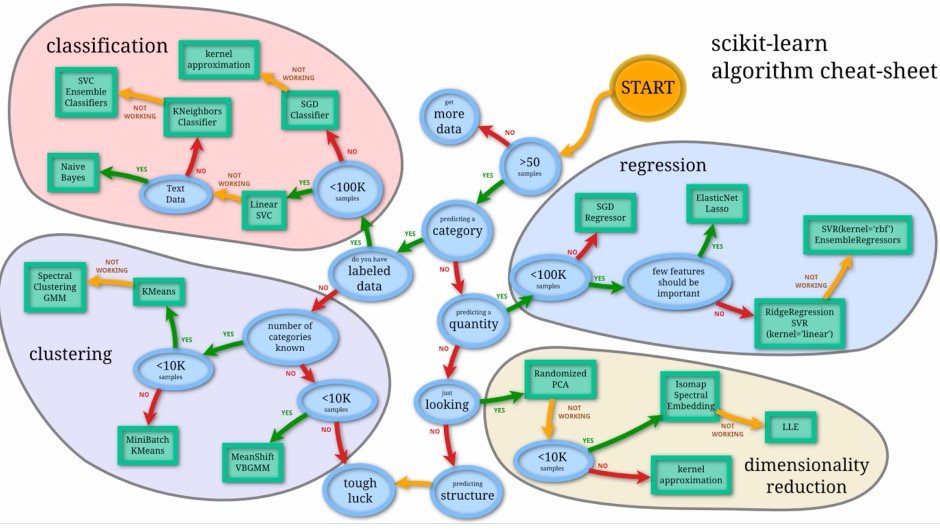
通常,解决机器学习问题的最困难的部分可能是找到恰当的的评估器(estimator)。
不同的评估器更适合不同类型的数据和不同的问题。
下面的流程图是一些粗略的指导,可以让用户根据自己的数据来选择应该尝试哪些评估器。
点击下图的任何评估器,查看其文档。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐
2021-03-20
8
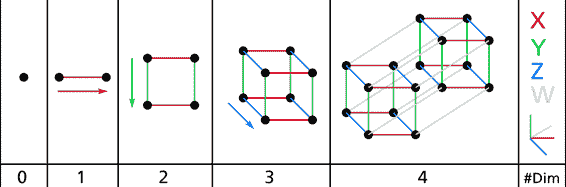
八、降维 译者:@loveSnowBest 校对者:@飞龙、@PeterHo、@yanmengk、@XinQiu、@Lisanaaa 很多机器学习的问题都会涉及到有着几千甚至数百万维的特征的训练实例。这不仅让训练过程变得非常缓慢,同时还很难找到一个很好的解,我们接下来就会遇到这种情况。这种问题通常被称为维数灾难(curse of dimentionality)。 幸运的是,在现实生活中我们经常可以极大的降低特征维度,将一个十分棘手的问题转变成一个可以较为容易解决的问题。例如,对于 MNIST 图片集(第 3 章中提到):图片四周边缘部分的像素几乎总是白的,因此你完全可以将这些像素从你的训练集中扔掉而不会丢失太多信息。图 7-6 向我们证实了这些像素的确对我们的分类任务是完全不重要的。同时,两个相邻的像素往往是高度相关的:如果你想要将他们合并成一个像素(比如取这两个像素点的平均值)你并不会丢失很多信息。 警告:降维肯定会丢失一些信息(这就好比将一个图片压缩成 JPEG 的格式会降低图像的质量),因此即使这种方法可以加快训练的速度,同时也会让你的系统表现的稍微差一点。降维...

2021-03-09
命令和语句
命令和语句 >命令行的特点 命名和语句 字母开头,字母下划线,区分大小写 不声明不定义拿来即用。 分号决定语句是否输出 英文省略号续行 赋值 等于号赋值给变量 无赋值对象时默认赋值给ans 变量管理 工作空间窗口查看 who whos 查看 全局的文件操作 清除变量的命令clear,清除所有变量或者单个变量 save[文件名][变量名][-append][-ascii] .mat文件是一种数据文件的类型,用于储存matlab中的数据 >数据的类型和显示 format函数,控制显示 short long e rat hex + bank compact loose MATLAB中常见的数据类型 数值型:双精度,单精度,符号整型数据 字符串、结构体、单元、多维矩阵、稀疏矩阵 默认双精度double unit8()将double型数据转换成无符号整型 double()能够将int类型转换为double类型的数据 class(变量)能够显示一个数据的类型 字符串类型的访问 单引号 double()或者...

2022-12-05
08 随机数Random
2 Random简介在 Java中要生成一个指定范围之内的随机数字有两种方法:一种是调用 Math 类的 random() 方法,一种是使用 Random 类。 Random():该构造方法使用一个和当前系统时间对应的数字作为种子数,然后使用这个种子数构造 Random 对象。Random(long seed):使用单个 long 类型的参数创建一个新的随机数生成器。 Random 类提供的所有方法生成的随机数字都是均匀分布的,也就是说区间内部的数字生成的概率是均等的 实例123456789101112131415161718192021package cn.itcast.demo1; import java.util.Random;//使用时需要先导包import java.util.Scanner; public class RAndom { public static void main(String[] args) { Random r = new Random();//以系统自身时间为种子数 int i = r.n...

2021-04-14
19 内存对齐
概述概念 编译器为程序中的每个“数据单元”安排在适当的位置上。 原因 平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。 性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。 补充观点:字节对齐主要是为了提高内存的访问效率,比如intel 32位cpu,每个总线周期都是从偶地址开始读取32位的内存数据,如果数据存放地址不是从偶数开始,则可能出现需要两个总线周期才能读取到想要的数据,因此需要在内存中存放数据时进行对齐。 例如64位操作系统,存储32位int值。如果两个int值占用同一个64位的寻址空间,那么方位第二个int值,需要两次寻址过程。首先找到地址,然后得到偏移。 规则每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。程序员可以通过预编译命令#pragma pack(n),n=1,2,4,8,16来改变这一系数,其中的n就是你要指定的“对齐系数”。 数据成员...
2023-08-18
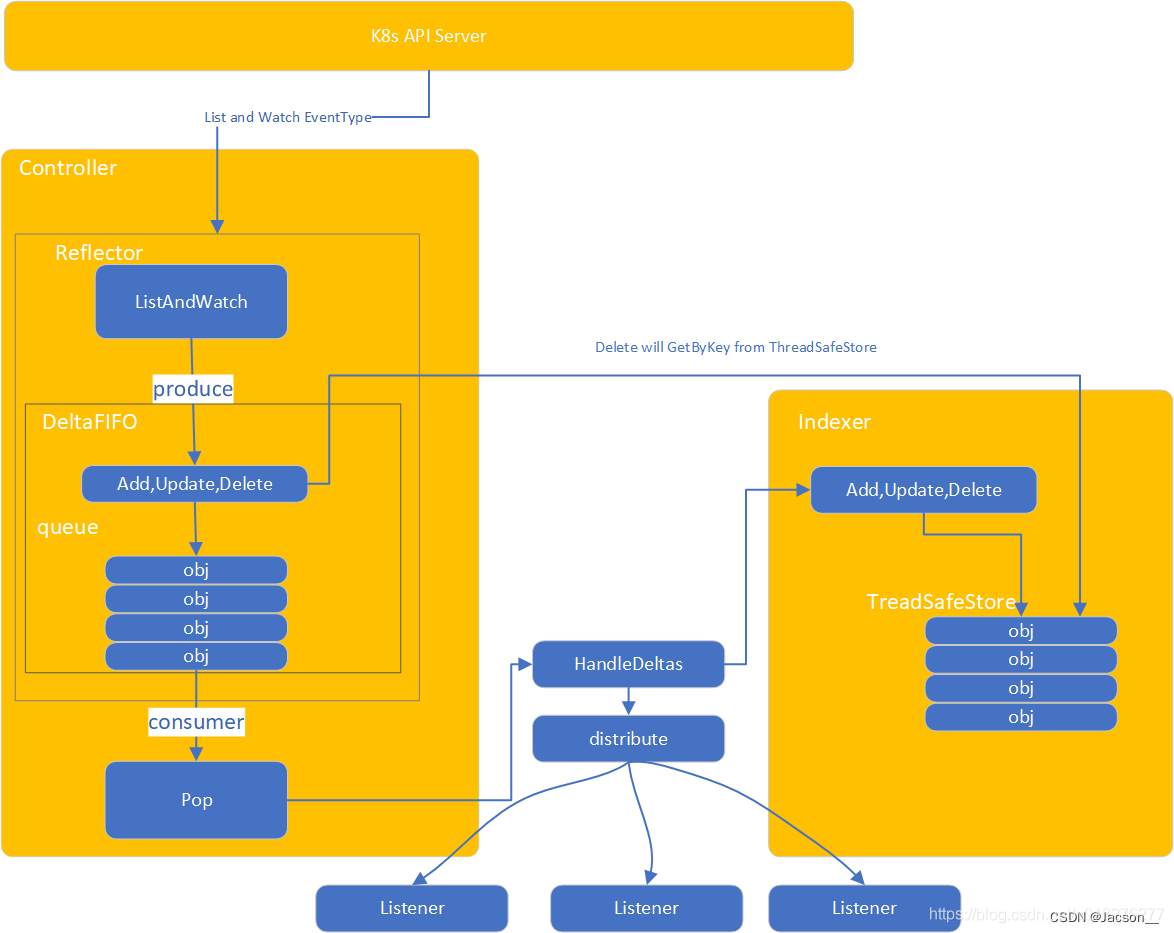
05 client-go
Client-go简介client-go是对K8s集群的二次开发工具,所以client-go是k8s开发者的必备工具之一。client-go实现对kubernetes集群中资源对象(包括deployment、service、ingress、replicaSet、pod、namespace、node等)的增删改查等操作。 client-go主要提供了四种类型的客户端: RESTClient: 是对HTTP Request进行了封装,实现了RESTful风格的API。其他客户端都是在RESTClient基础上的实现。可与用于k8s内置资源和CRD资源 ClientSet:是对k8s内置资源对象的客户端的集合,默认情况下,不能操作CRD资源,但是通过client-gen代码生成的话,也是可以操作CRD资源的。 DynamicClient:不仅能对K8S内置资源进行处理,还可以对CRD资源进行处理,不需要client-gen生成代码即可实现。 DiscoveryClient:用于发现kube-apiserver所支持的资源组、资源版本、资源信息(即Group、Version、Re...
2020-01-04
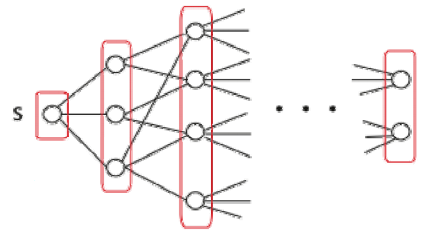
3.2 搜索算法-广度优先搜索
广度优先搜索1 概述特点 广度优先搜索(BFS:Breadth-First Search)是一种树和图搜索策略,其将搜索限制到 2 种操作: 访问图中的一个节点; 访问该节点的邻居节点; 过程 广度优先搜索(BFS)由 Edward F. Moore 在 1950 年发表,起初被用于在迷宫中寻找最短路径。在 Prim 最小生成树算法和 Dijkstra 单源最短路径算法中,都采用了与广度优先搜索类似的思想。 对图的广度优先搜索与对树(Tree)的广度优先遍历(Breadth First Traversal)是类似的,区别在于图中可能存在环,所以可能会遍历到已经遍历的节点。BFD 算法首先会发现和源顶点 s 距离边数为 k 的所有顶点,然后才会发现和 s 距离边数为 k+1 的其他顶点。 例子 例如,下面的图中,从顶点 2 开始遍历,当遍历到顶点 0 时,邻接的顶点为 1 和 2,而顶点 2 已经遍历过,如果不做标记,遍历过程将陷入死循环。所以,在 BFS 的算法实现中需要对顶点是否访问过做标记。 上图的 BFS 遍历结果为 [ 2, 0, 3, 1 ]。 实...




