
24
5.2 – GPU 加速运算
在 GPU 训练可以大幅提升运算速度. 而且 Torch 也有一套很好的 GPU 运算体系. 但是要强调的是:
- 你的电脑里有合适的 GPU 显卡(NVIDIA), 且支持 CUDA 模块. 请在NVIDIA官网查询
- 必须安装 GPU 版的 Torch, 点击这里查看如何安装
用 GPU 训练 CNN
这份 GPU 的代码是依据之前这份CNN的代码修改的. 大概修改的地方包括将数据的形式变成 GPU 能读的形式, 然后将 CNN 也变成 GPU 能读的形式. 做法就是在后面加上 .cuda() , 很简单.
1 | ... |
再来把我们的 CNN 参数也变成 GPU 兼容形式.
1 | class CNN(nn.Module): |
然后就是在 train 的时候, 将每次的training data 变成 GPU 形式. .cuda()
1 | for epoch ..: |
大功告成~
所以这也就是在我 github 代码 中的每一步的意义啦.
文章来源:莫烦
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2021-12-24
nmap
nmap网络探测和安全审核 补充说明nmap命令 是一款开放源代码的网络探测和安全审核工具,它的设计目标是快速地扫描大型网络。 语法1nmap(选项)(参数) 选项123456789101112131415161718192021222324-O:激活操作探测;-P0:值进行扫描,不ping主机;-PT:是同TCP的ping;-sV:探测服务版本信息;-sP:ping扫描,仅发现目标主机是否存活;-ps:发送同步(SYN)报文;-PU:发送udp ping;-PE:强制执行直接的ICMPping;-PB:默认模式,可以使用ICMPping和TCPping;-6:使用IPv6地址;-v:得到更多选项信息;-d:增加调试信息地输出;-oN:以人们可阅读的格式输出;-oX:以xml格式向指定文件输出信息;-oM:以机器可阅读的格式输出;-A:使用所有高级扫描选项;--resume:继续上次执行完的扫描;-P:指定要扫描的端口,可以是一个单独的端口,用逗号隔开多个端口,使用“-”表示端口范围;-e:在多网络接口Linux系统中,指定扫描使用的网络接口;-g:将指定的端口作为源端口进行扫...
2024-05-13
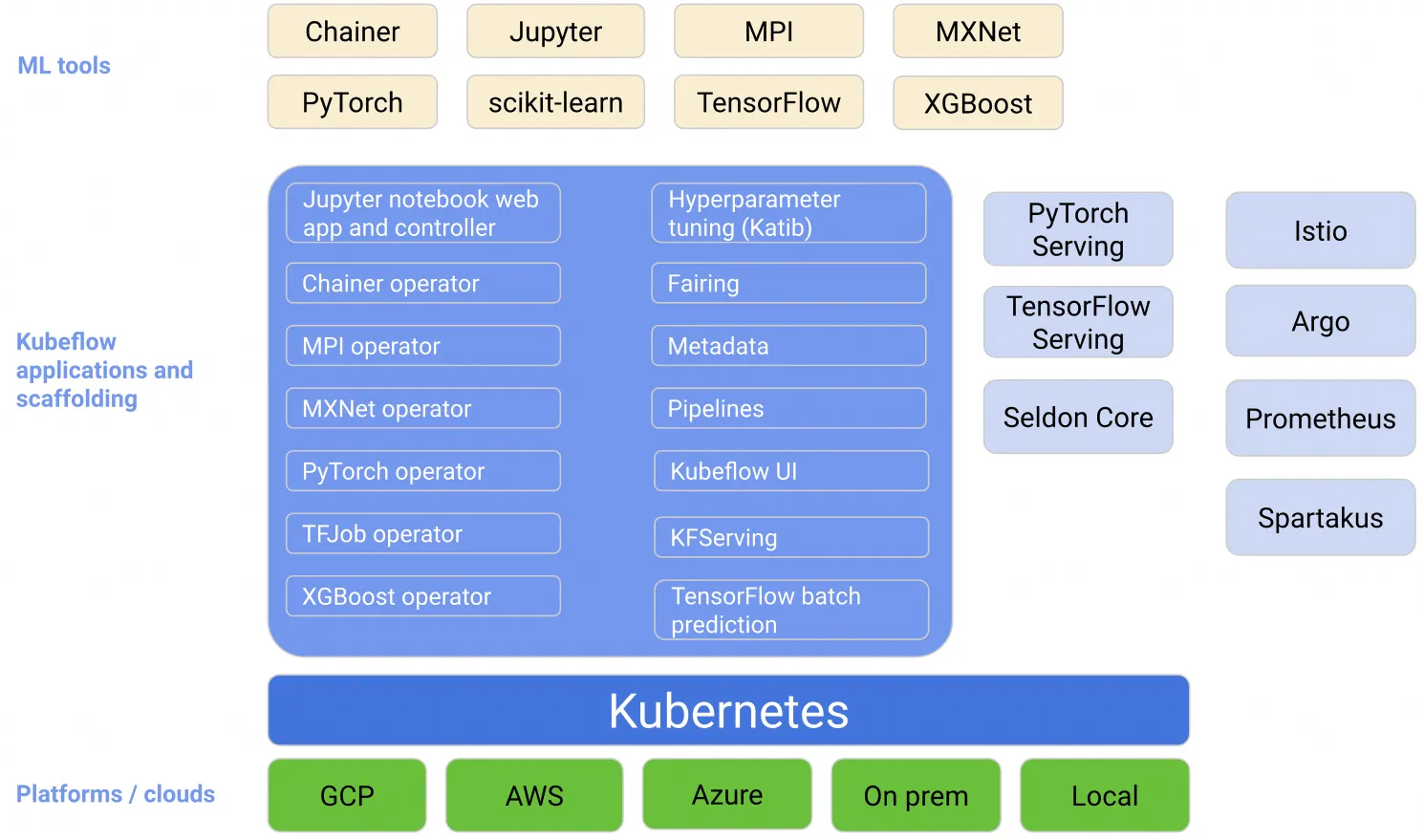
01 kubeflow
MLOps机器学习开发迭代3. 数据收集 a. 大数据量下的文件存储与读取 —— HDFS,NFS 等分布式文件存储系统; b. 非结构化数据 —— S3 等对象存储; c. 向量数据存储 —— milvus 等向量数据库; d. 数据的持续采集与入库 —— Kafka,RabbitMQ 等流式处理工具 ;4. 数据预处理 a. 清洗、格式化、规范化、脱敏 —— Python Pandas; b. 人工标记; c. 特征工程,“数据和特征决定了模型的上限,算法只是在帮忙逼近这个上限”5. 框架选择 a. 训练框架:PyTorch,TensorFlow,PaddlePaddle,……;6. 模型训练 a. 代码开发 —— Python IDE,Notebook; ⅰ. 开发阶段会采集小量的数据,经过小次数的迭代,用于正确性验证, Notebook 可以辅助验证; b. 训练 ⅰ. 本地/单节点/单机单卡/单机多卡/多机多卡 —— GPU 管理与调度 ⅱ. 任务调度/故障转移/check...

2021-12-24
lsb_release
lsb_release显示发行版本信息 补充说明LSB是Linux Standard Base的缩写, lsb_release命令 用来显示LSB和特定版本的相关信息。如果使用该命令时不带参数,则默认加上-v参数。 1234567-v 显示版本信息。-i 显示发行版的id。-d 显示该发行版的描述信息。-r 显示当前系统是发行版的具体版本号。-c 发行版代号。-a 显示上面的所有信息。-h 显示帮助信息。 如果当前发行版是LSB兼容的,那么/etc/lsb_release文件中会包含LSB_VERSION域。这个域的值可以是用冒号隔开的一系列支持的模块。这些模块名是当前版本支持的LSB的模块名。如果当前版本不是LSB兼容的,就不要包含这个域。 可选的域包括DISTRIB_ID, DISTRIB_RELEASE, DISTRIB_CODENAME,DISTRIB_DESCRIPTION,它们可以覆盖/etc/distrib-release文件中的内容。注:这里的distrib要替换为当前的发行版的名字。如果存在/etc/lsb-release.d目录,会在该目录中查找文件名并作为...
2021-03-20
03
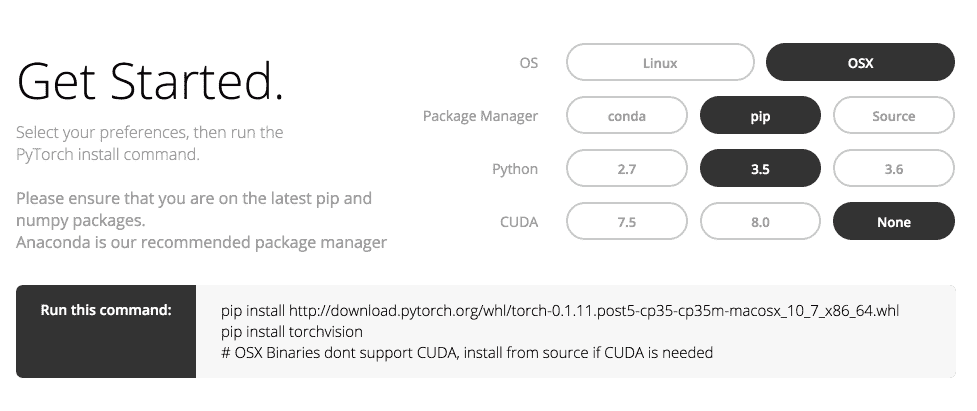
1.2 – 安装 PyTorch支持的系统PyTorch 暂时只支持 MacOS, Linux. 暂不支持 Windows! (可怜的 Windows 同学们.. 又被抛弃了). 不过说不定像 Tensorflow 一样, 因为 Windows 用户的强烈要求, 他们在某天就突然支持了. 安装PyTorch 安装起来很简单, 它自家网页上就有很方便的选择方式 (网页升级改版后可能和下图有点不同): 所以根据你的情况选择适合你的安装方法, 我已自己为例, 我使用的是 MacOS, 想用 pip 安装, 我的 Python 是 3.5 版的, 我没有 GPU 加速, 那我就按上面的选: 然后根据上面的提示, 我只需要在我的 Terminal 当中输入以下指令就好了: 12$ pip install http://download.pytorch.org/whl/torch-0.1.11.post5-cp35-cp35m-macosx_10_7_x86_64.whl$ pip install torchvision 注意, 我安装的是0.1.11版本的 torch, 你需要去他们网...

2020-09-26
timedeltas
时间差Timedelta,时间差,即时间之间的差异,用 日、时、分、秒 等时间单位表示,时间单位可为正,也可为负。 Timedelta 是 datetime.timedelta 的子类,两者的操作方式相似,但 Timedelta 兼容 np.timedelta64 等数据类型,还支持自定义表示形式、能解析多种类型的数据,并支持自有属性。 解析数据,生成时间差Timedelta() 支持用多种参数生成时间差: 12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849In [1]: import datetime# 字符串In [2]: pd.Timedelta('1 days')Out[2]: Timedelta('1 days 00:00:00')In [3]: pd.Timedelta('1 days 00:00:00')Out[3]: Timedelta('1 days 00:00:00...

2021-12-24
dpkg-preconfigure
dpkg-preconfigureDebian Linux中软件包安装之前询问问题 补充说明dpkg-preconfigure命令 用于在Debian Linux中软件包安装之前询问问题。 语法1dpkg-preconfigure(选项)(参数) 选项123-f:选择使用的前端;-p:感兴趣的最低的优先级问题;--apt:在apt模式下运行。 参数软件包:指定“.deb”软件包。 实例导入debconf模板: 1dpkg-preconfigure /var/cache/apt/archives/mysql-server-5.5*.deb




