@staticmethod @rpc.functions.async_execution defupdate_and_fetch_model(ps_rref, grads): # Using the RRef to retrieve the local PS instance self = ps_rref.local_value() withself.lock: self.curr_update_size += 1 # accumulate gradients into .grad field for p, g inzip(self.model.parameters(), grads): p.grad += g
# Save the current future_model and return it to make sure the # returned Future object holds the correct model even if another # thread modifies future_model before this thread returns. fut = self.future_model
ifself.curr_update_size >= self.batch_update_size: # update the model for p inself.model.parameters(): p.grad /= self.batch_update_size self.curr_update_size = 0 self.optimizer.step() self.optimizer.zero_grad() # by settiing the result on the Future object, all previous # requests expecting this updated model will be notified and # the their responses will be sent accordingly. fut.set_result(self.model) self.future_model = torch.futures.Future()
deftrain(self): name = rpc.get_worker_info().name # get initial model parameters m = self.ps_rref.rpc_sync().get_model().cuda() # start training for inputs, labels inself.get_next_batch(): self.loss_fn(m(inputs), labels).backward() m = rpc.rpc_sync( self.ps_rref.owner(), BatchUpdateParameterServer.update_and_fetch_model, args=(self.ps_rref, [p.grad for p in m.cpu().parameters()]), ).cuda()
defrun_episode(self, agent_rref, n_steps): state, ep_reward = self.env.reset(), NUM_STEPS rewards = torch.zeros(n_steps) start_step = 0 for step inrange(n_steps): state = torch.from_numpy(state).float().unsqueeze(0) # send the state to the agent to get an action action = rpc.rpc_sync( agent_rref.owner(), self.select_action, args=(agent_rref, self.id, state) )
# apply the action to the environment, and get the reward state, reward, done, _ = self.env.step(action) rewards[step] = reward
if done or step + 1 >= n_steps: curr_rewards = rewards[start_step:(step + 1)] R = 0 for i inrange(curr_rewards.numel() -1, -1, -1): R = curr_rewards[i] + args.gamma * R curr_rewards[i] = R state = self.env.reset() if start_step == 0: ep_reward = min(ep_reward, step - start_step + 1) start_step = step + 1
使用批量时,状态以观察者 id 为行 ID 存储在 2D 张量self.states中。 然后,它通过将回调函数安装到批量生成的self.future_actionsFuture对象上来链接Future,该对象将使用使用该观察者 ID 索引的特定行进行填充。 最后到达的观察者一口气通过策略运行所有批量状态,并相应地设置self.future_actions。 发生这种情况时,将触发安装在self.future_actions上的所有回调函数,并使用它们的返回值来填充链接的Future对象,该对象进而通知Agent为所有先前的 RPC 请求准备和传达来自其他观察者的响应。
defrun_episode(self, n_steps=0): futs = [] for ob_rref inself.ob_rrefs: # make async RPC to kick off an episode on all observers futs.append(ob_rref.rpc_async().run_episode(self.agent_rref, n_steps))
# wait until all obervers have finished this episode rets = torch.futures.wait_all(futs) rewards = torch.stack([ret[0] for ret in rets]).cuda().t() ep_rewards = sum([ret[1] for ret in rets]) / len(rets)
# stack saved probs into one tensor ifself.batch: probs = torch.stack(self.saved_log_probs) else: probs = [torch.stack(self.saved_log_probs[i]) for i inrange(len(rets))] probs = torch.stack(probs)
if print_log: print('Episode {}\tLast reward: {:.2f}\tAverage reward: {:.2f}'.format( i_episode, last_reward, running_reward)) else: # other ranks are the observer rpc.init_rpc(OBSERVER_NAME.format(rank), rank=rank, world_size=world_size) # observers passively waiting for instructions from agents rpc.shutdown()
defmain(): for world_size inrange(2, 12): delays = [] for batch in [True, False]: tik = time.time() mp.spawn( run_worker, args=(world_size, args.num_episode, batch), nprocs=world_size, join=True ) tok = time.time() delays.append(tok - tik)
print(f"{world_size}, {delays[0]}, {delays[1]}")
if __name__ == '__main__': main()
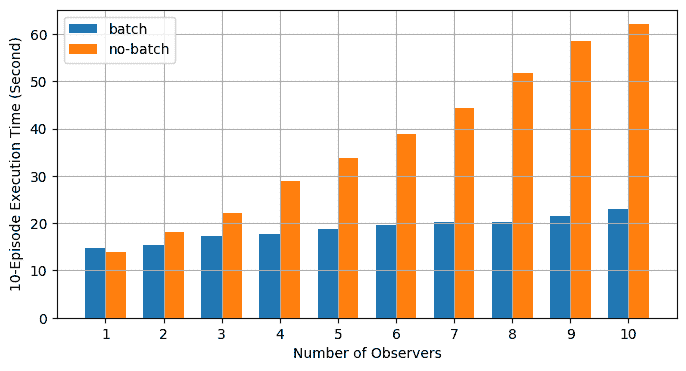
批量 RPC 有助于将操作推断合并为较少的 CUDA 操作,从而减少了摊销的开销。 上面的main函数使用不同数量的观察者(从 1 到 10)在批量和无批量模式下运行相同的代码。下图使用默认参数值绘制了不同世界大小的执行时间。 结果证实了我们的期望,即批量有助于加快训练速度。