
4.2 连续存储管理
4.2 连续分配方式存储管理
存储管理方式。内存的分配方式.
概念
- 每个进程占用一个物理上完全连续的存储空间(区域)
1 单一连续分配
- 只能用于单用户、单任务的操作系统中。
- 把内存分为系统区和用户区两部分.系统区仅提供给 OS 使用,通常是放在内存的低址部分;用户区是指除系统区以外的全部内存空间,提供给用户使用。
- 通常采用静态重定位的方式装入程序。
2 固定分区分配
- 这是将内存用户空间划分为若干个固定大小的区域,在每个分区中只装入一道作业,这样,把用户空间划分为几个分区,便允许有几道作业并发运行。
3 动态分区分配
分区分配中所用的数据结构、分区分配算法和分区的分配与回收操作这样三个问题。
数据结构:
- 空闲分区表。在系统中设置一张空闲分区表,用于记录每个空闲分区的情况。每个空闲分区占一个表目,表目中包括分区序号、分区始址及分区的大小等数据项。
- 空闲分区链。为了实现对空闲分区的分配和链接,在每个分区的起始部分,设置一些用于控制分区分配的信息,以及用于链接各分区所用的前向指针;在分区尾部则设置一后向指针,通过前、后向链接指针,可将所有的空闲分区链接成一个双向链,
分区分配算法
- 首次适应算法(first fit) 。FF 算法要求空闲分区链以地址递增的次序链接。在分配内存时,从链首开始顺序查找,直至找到一个大小能满足要求的空闲分区为止;然后再按照作业的大小,从该分区中划出一块内存空间分配给请求者,余下的空闲分区仍留在空闲链中。
- 循环首次适应算法(next fit) 是从上次找到的空闲分区的下一个空闲分区开始查找,直至找到一个能满足要求的空闲分区,从中划出一块与请求大小相等的内存空间分配给作业。
- 最佳适应算法(best fit) 总是把能满足要求、又是最小的空闲分区分配给作业,避免“大材小用”。
- 最坏适应算法(worst fit)最坏适应分配算法要扫描整个空闲分区表或链表,总是挑选一个最大的空闲区分割给作业使用,其优点是可使剩下的空闲区不至于太小,产生碎片的几率最小,对中、小作业有利,同时最坏适应分配算法查找效率很高。
- 快速适应算法(quick fit)该算法又称为分类搜索法,是将空闲分区根据其容量大小进行分类,对于每一类具有相同容量的所有空闲分区,单独设立一个空闲分区链表,这样,系统中存在多个空闲分区链表,同时在内存中设立一张管理索引表,该表的每一个表项对应了一种空闲分区类型,并记录了该类型空闲分区链表表头的指针。
分区的分配与回收操作
- 分配内存。系统应利用某种分配算法,从空闲分区链(表)中找到所需大小的分区。
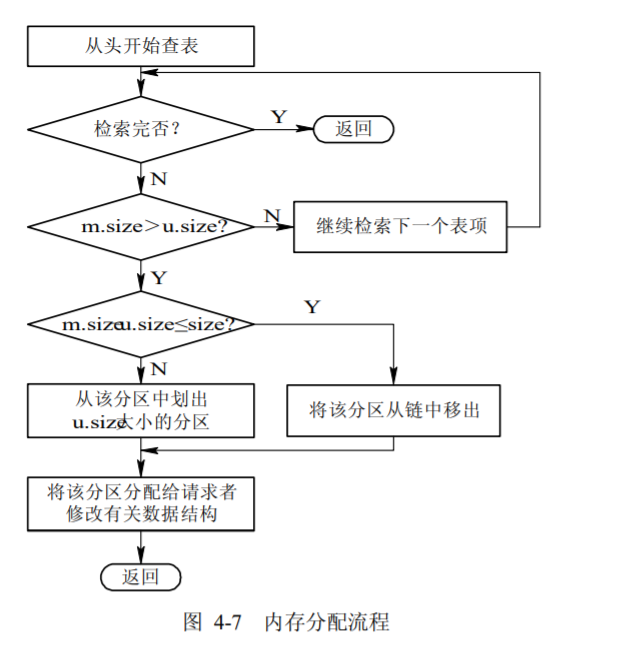
- 回收内存。当进程运行完毕释放内存时,系统根据回收区的首址,从空闲区链(表)中找到相应的插入点,并与相邻空闲分区合并。
4 可重定位的分区分配
动态重定位的引入。
- 在连续分配方式中,必须把一个系统或用户程序装入一连续的内存空间。
- 将内存中的所有作业进行移动,使它们全都相邻接,这样,即可把原来分散的多个小分区拼接成一个大分区,这时就可把作业装入该区。这种通过移动内存中作业的位置,以把原来多个分散的小分区拼接成一个大分区的方法,称为“拼接”或“紧凑”,需要对其中的程序进行重定位。
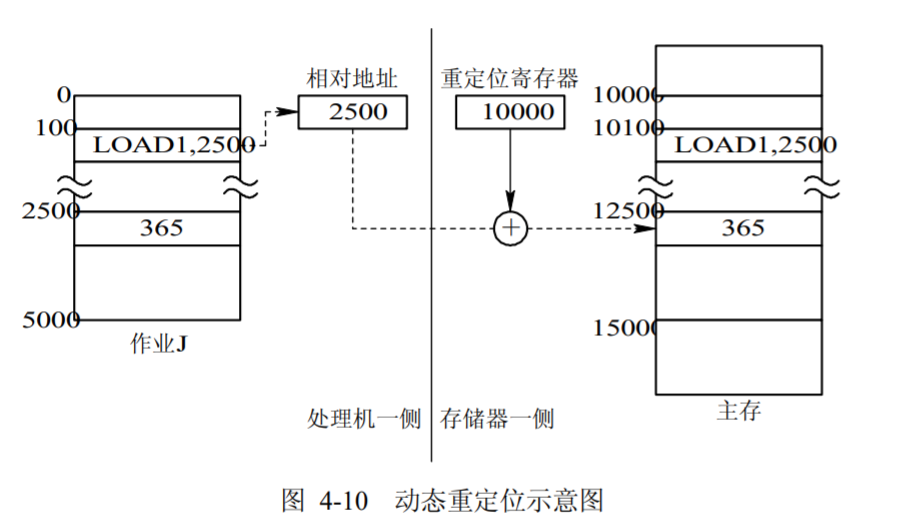
动态重定位的实现
- 增设一个重定位寄存器,用它来存放程序(数据)在内存中的起始地址。程序在执行时,真正访问的内存地址是相对地址与重定位寄存器中的地址相加而形成的。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2021-12-24
useradd
useradd创建的新的系统用户 补充说明useradd命令 用于Linux中创建的新的系统用户。useradd可用来建立用户帐号。帐号建好之后,再用passwd设定帐号的密码.而可用userdel删除帐号。使用useradd指令所建立的帐号,实际上是保存在/etc/passwd文本文件中。 在Slackware中,adduser指令是个script程序,利用交谈的方式取得输入的用户帐号资料,然后再交由真正建立帐号的useradd命令建立新用户,如此可方便管理员建立用户帐号。在Red Hat Linux中, adduser命令 则是useradd命令的符号连接,两者实际上是同一个指令。 语法1useradd(选项)(参数) 选项12345678910111213-c<备注>:加上备注文字。备注文字会保存在passwd的备注栏位中;-d<登入目录>:指定用户登入时的启始目录;-D:变更预设值;-e<有效期限>:指定帐号的有效期限;-f<缓冲天数>:指定在密码过期后多少天即关闭该帐号;-g<群组>:指定用户所属的群组;-G...

2021-12-24
chroot
chroot把根目录换成指定的目的目录 补充说明chroot命令 用来在指定的根目录下运行指令。chroot,即 change root directory (更改 root 目录)。在 linux 系统中,系统默认的目录结构都是以/,即是以根 (root) 开始的。而在使用 chroot 之后,系统的目录结构将以指定的位置作为/位置。 在经过 chroot 命令之后,系统读取到的目录和文件将不在是旧系统根下的而是新根下(即被指定的新的位置)的目录结构和文件,因此它带来的好处大致有以下3个: 增加了系统的安全性,限制了用户的权力: 在经过 chroot 之后,在新根下将访问不到旧系统的根目录结构和文件,这样就增强了系统的安全性。这个一般是在登录 (login) 前使用 chroot,以此达到用户不能访问一些特定的文件。 建立一个与原系统隔离的系统目录结构,方便用户的开发: 使用 chroot 后,系统读取的是新根下的目录和文件,这是一个与原系统根下文件不相关的目录结构。在这个新的环境中,可以用来测试软件的静态编译以及一些与系统不相关的独立开发。 切换系统的根目录位置,引导 L...
2021-03-30
4.1 层次结构与装入链接
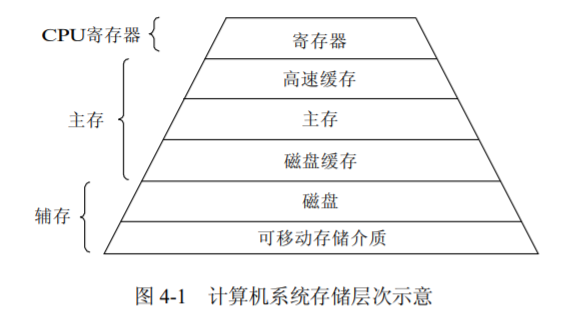
1 存储器的层次结构存储器的层次结构 寄存器 寄存器访问速度最快,完全能与 CPU 协调工作。寄存器用于加速存储器的访问速度,如用寄存器存放操作数,或用作地址寄存器加快地址转换速度等。 高速缓存 Cache是介于CPU和主存储器间的高速小容量存储器,由静态存储芯片SRAM组成,容量较小但比主存DRAM技术更加昂贵而快速,接近于CPU的速度 CPU往往需要重复读取同样的数据库,Cache的引入与缓存容量的增大,可以大幅提升CPU内部读取数据的命中率,从而提高系统性能 分级:由于CPU芯片面积和成本,Cache很小。根据成本控制,划分L1,L2,L3三级。 L1 Cache:分为数据缓存和指令缓存;内置;成本最高,对CPU的性能影响最大;通常在32KB-256KB之间 L2 Cache:分内置和外置两种,后者性能低一些;通常在512KB-8MB之间 L3 Cache:多为外置,在游戏和服务器领域有效;但对很多应用来说,总线改善比设置L3更加有利于提升系统性能 主存储器 主存储器(简称内存或主存)是计算机系统中一个主要部件,用于保存进程运行时的程序和数据,也称可执行存储器。数据...

2021-12-24
init
initinit进程是所有Linux进程的父进程 补充说明init命令 是Linux下的进程初始化工具,init进程是所有Linux进程的父进程,它的进程号为1。init命令是Linux操作系统中不可缺少的程序之一,init进程是Linux内核引导运行的,是系统中的第一个进程。 语法1init(选项)(参数) 选项12-b:不执行相关脚本而直接进入单用户模式;-s:切换到单用户模式。 参数运行等级:指定Linux系统要切换到的运行等级。 实例几个常用的命令 查看系统进程命令:ps -ef | head查看init的配置文件:more /etc/inittab查看系统当前运行的级别:runlevel 运行级别 到底什么是运行级呢?简单的说,运行级就是操作系统当前正在运行的功能级别。这个级别从0到6 ,具有不同的功能。你也可以在/etc/inittab中查看它的英文介绍。 1234567#0 停机(千万不能把initdefault 设置为0)#1 单用户模式#2 多用户,没有 NFS(和级别3相似,会停止部分服务)#3 完全多用户模式#4 没有用到#5 x11(X...

2021-12-24
locate
locate比 find 好用的文件查找工具 补充说明locate 让使用者可以很快速的搜寻档案系统内是否有指定的档案。其方法是先建立一个包括系统内所有档案名称及路径的数据库,之后当寻找时就只需查询这个数据库,而不必实际深入档案系统之中了。在一般的 distribution 之中,数据库的建立都被放在 crontab 中自动执行。 locate命令可以在搜寻数据库时快速找到档案,数据库由updatedb程序来更新,updatedb是由cron daemon周期性建立的,locate命令在搜寻数据库时比由整个由硬盘资料来搜寻资料来得快,但较差劲的是locate所找到的档案若是最近才建立或 刚更名的,可能会找不到,在内定值中,updatedb每天会跑一次,可以由修改crontab来更新设定值。(etc/crontab) locate指定用在搜寻符合条件的档案,它会去储存档案与目录名称的数据库内,寻找合乎范本样式条件的档案或目录录,可以使用特殊字元(如”” 或”?”等)来指定范本样式,如指定范本为kcpaner, locate 会找出所有起始字串为kcpa且结尾为ner的档案...

2021-12-24
w
w显示目前登入系统的用户信息 补充说明w命令 用于显示已经登陆系统的用户列表,并显示用户正在执行的指令。执行这个命令可得知目前登入系统的用户有那些人,以及他们正在执行的程序。单独执行w命令会显示所有的用户,您也可指定用户名称,仅显示某位用户的相关信息。 语法1w(选项)(参数) 选项123456789-h, --no-header 不打印头信息;-u, --no-current 当显示当前进程和cpu时间时忽略用户名;-s, --short 使用短输出格式;-f, --from 显示用户从哪登录;-o, --old-style 老式输出-i, --ip-addr 显示IP地址而不是主机名(如果可能) --help 显示此帮助并退出-V, --version 显示版本信息。 参数用户:仅显示指定用户。 实例1234w 20:39:37 up 136 days, 3:58, 1 user, load average: 0.00, 0.00, 0.00USER TTY FRO...




