
面试问题整理
1. 对网络模型的理解
五层网络模型、七层网络模型。各层的主要作用。各层的数据结构。各层运行的协议。
2. TCP可靠数据传输的实现机制
停止等待、回退N步、选择重传。
- 校验和
- 序号机制
- 确认机制和超时重传。
- 滑动窗口和流水线技术
- 累计确认机制
- 选择重传机制
3. TCP的三次握手四次挥手
报文段类型SYN、FIN。状态迁移。序号变化。
4. TCP的流量控制和拥塞控制
- 慢启动
- 拥塞避免
- 快重传
- 快回复
5 路由算法
- 链路状态路由算法
- 距离向量路由算法
- 层次路由算法OSPF、BGP
6 为什么会出现粘包
主要原因就是tcp数据传递模式是流模式,在保持长连接的时候可以进行多次的收和发。
“粘包”可发生在发送端也可发生在接收端:
- 由Nagle算法造成的发送端的粘包:Nagle算法是一种改善网络传输效率的算法。
简单来说就是当我们提交一段数据给TCP发送时,TCP并不立刻发送此段数据,
而是等待一小段时间看看在等待期间是否还有要发送的数据,若有则会一次把这两段数据发送出去。 - 接收端接收不及时造成的接收端粘包:TCP会把接收到的数据存在自己的缓冲区中,然后通知应用层取数据。
当应用层由于某些原因不能及时的把TCP的数据取出来,就会造成TCP缓冲区中存放了几段数据。
解决办法
出现”粘包”的关键在于接收方不确定将要传输的数据包的大小,因此我们可以对数据包进行封包和拆包的操作。
封包:封包就是给一段数据加上包头,这样一来数据包就分为包头和包体两部分内容了(过滤非法包时封包会加入”包尾”内容)。
包头部分的长度是固定的,并且它存储了包体的长度,根据包头长度固定以及包头中含有包体长度的变量就能正确的拆分出一个完整的数据包。
我们可以自己定义一个协议,比如数据包的前4个字节为包头,里面存储的是发送的数据的长度。
7. HTTP请求的过程
- 域名解析
- 三次握手
- 浏览器HTTP请求、服务器HTTP响应
- 浏览器得到HTML、JS代码。
- 浏览器渲染页面,给用户。
具体过程
- 域名解析
- DNS缓存(浏览器DNS缓存、操作系统DNS缓存)
- Host匹配
- 域名服务器递归解析(IP地址)
- 封包过程与解包过程
- 应用层:HTML报文
- 传输层:TCP报文段。添加TCP报头。
- 网络层:IP数据报。分片。
- 链路层:帧
- 物理层:比特
- 应用层
- 服务器的应用层负责处理请求的业务逻辑,返回结果。
- 客户端的应用层负责将得到的数据进行渲染和解析。
- 传输层
- TCP三次握手
- 滑动窗口传输数据。可靠传输、拥塞控制
- TCP四次挥手
- 网络层
- 路由。OSPF、BGP等协议,利用路由算法,确定下一跳的地址。路由表。
- 链路层
- 转发。ARP地址解析协议。将IP地址转换为MAC地址。交换机表。控制碰撞
- 物理层
- 比特。防止碰撞。
8 HTTP2.0
HTTP2.0和HTTP1.X相比的新特性
新的二进制格式(Binary Format),HTTP1.x的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
多路复用(MultiPlexing),即连接共享,即每一个request都是是用作连接共享机制的。一个request对应一个id,这样一个连接上可以有多个request,每个连接的request可以随机的混杂在一起,接收方可以根据request的 id将request再归属到各自不同的服务端请求里面。
header压缩,如上文中所言,对前面提到过HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
服务端推送(server push),同SPDY一样,HTTP2.0也具有server push功能。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2021-10-14
一次HTTP请求的过程
过程概览 对www.baidu.com这个网址进行DNS域名解析,得到对应的IP地址 根据这个IP,找到对应的服务器,发起TCP的三次握手 建立TCP连接后发起HTTP请求 服务器响应HTTP请求,浏览器得到html代码 浏览器解析html代码,并请求html代码中的资源(如js、css图片等)(先得到html代码,才能去找这些资源) 浏览器对页面进行渲染呈现给用户 注:1.DNS域名解析采用的是递归查询的方式,过程是,先去找DNS缓存->缓存找不到就去找根域名服务器->根域名又会去找下一级,这样递归查找之后,找到了,给我们的web浏览器2.为什么HTTP协议要基于TCP来实现? TCP是一个端到端的可靠的面相连接的协议,HTTP基于传输层TCP协议不用担心数据传输的各种问题(当发生错误时,会重传)3.最后一步浏览器是如何对页面进行渲染的? a)解析html文件构成 DOM树,b)解析CSS文件构成渲染树, c)边解析,边渲染 , d)JS 单线程运行,JS有可能修改DOM结构,意味着JS执行完成前,后续所有资源的下载是没有必要的,所以JS是单线程,会阻塞...
2019-10-15
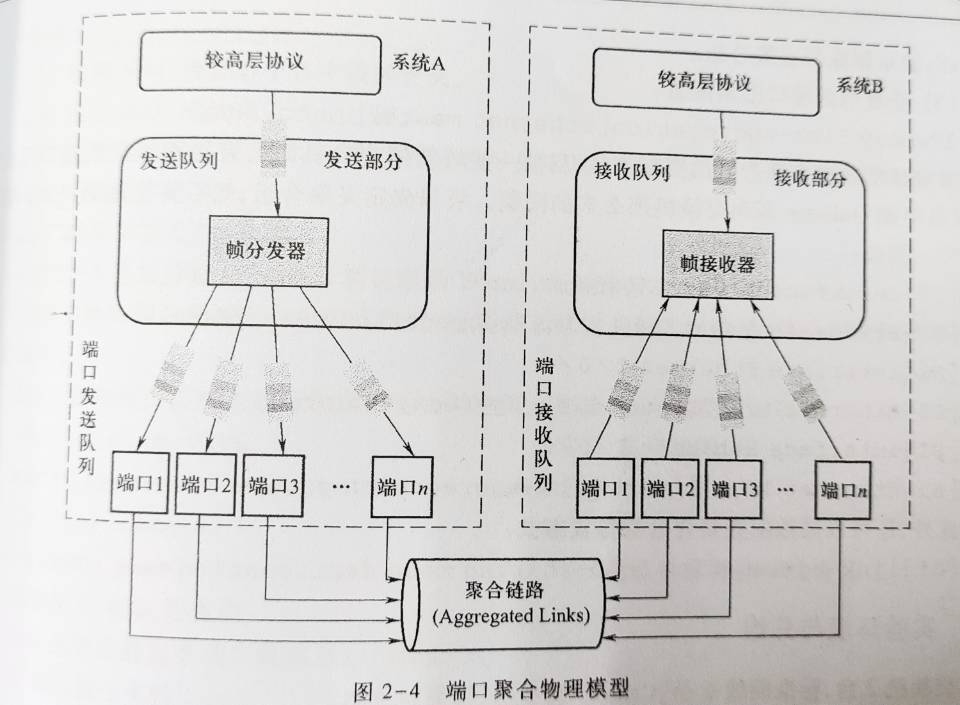
2 链路层实验
链路层实验目录 以太网链路层帧格式分析 交换机的MAC地址表和端口聚合 VLAN的配置与分析 广域网协议分析 设计型实验 1 以太网链路层帧格式分析以太网的技术标准,它规定了包括物理层的连线、电子信号和介质访问层协议的内容。以太网是目前应用最普遍的局域网技术,取代了其他局域网技术如令牌环、FDDI和ARCNET。 以太网是一种网络链路形式,是星型网络。与令牌环、arcnet是链路层网络技术。而不是泛指整个计算机网络。它只是计算机网络某一个层面的一个子集。因特网也是,他是应用层的一种技术,是应用层众多技术中的一个子集,而不是泛指整个计算机网络。 以太网帧格式可以参考链路层-交换局域网的内容。 2 交换机的MAC地址表和端口聚合MAC地址表交换机的转发是基于MAC地址表的。以太网交换机收到数据帧时会进行一下操作: MAC地址表中没有mac-interface匹配项,则向所有(除发送端口外)端口发送数据帧。 如果MAC地址表中有mac-interface匹配项,则表明该端口和目的主机在同一个广播域,转发到指定的端口上。 交换机还将检查收到的数据帧的源mac地址,并查找mac地址表...

2020-09-26
data_browser
数据浏览器在多个画布之间连接数据。 此示例介绍了如何与多个画布交互数据。这样,您可以选择并突出显示一个轴上的点,并在另一个轴上生成该点的数据。 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990import numpy as npclass PointBrowser(object): """ Click on a point to select and highlight it -- the data that generated the point will be shown in the lower axes. Use the 'n' and 'p' keys to browse throug...
2021-06-15
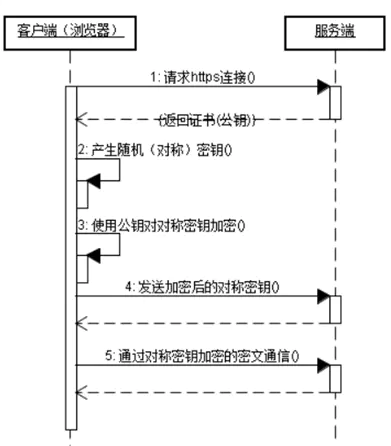
7 HTTPS协议
HTTPS 协议1 HTTPS主要功能 数据完整性:内容传输经过完整性校验 数据隐私性:内容经过对称加密,每个连接生成一个唯一的加密密钥 身份认证:第三方无法伪造服务端(客户端)身份 数据完整性和隐私性由TLS Record Protocol保证,身份认证由TLS Handshaking Protocols实现。 认证过程HTTPS在传输数据之前需要客户端(浏览器)与服务端(网站)之间进行一次握手,在握手过程中将确立双方加密传输数据的密码信息。TLS/SSL协议不仅仅是一套加密传输的协议,更是一件经过艺术家精心设计的艺术品,TLS/SSL中使用了非对称加密,对称加密以及HASH算法。握手过程的具体描述如下: 浏览器将自己支持的一套加密规则发送给网站。 网站从中选出一组加密算法与HASH算法,并将自己的身份信息以证书的形式发回给浏览器。证书里面包含了网站地址,加密公钥,以及证书的颁发机构等信息。 浏览器获得网站证书之后浏览器要做以下工作: 验证证书的合法性(颁发证书的机构是否合法,证书中包含的网站地址是否与正在访问的地址一致等),如果证书受信任,则浏览器栏...
2021-03-09
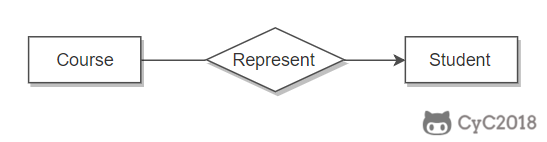
设计篇——2.设计步骤
设计篇——设计步骤1 ER 图定义Entity-Relationship,有三个组成部分:实体、属性、联系。 用来进行关系型数据库系统的概念设计。 实体的三种联系包含一对一,一对多,多对多三种。 如果 A 到 B 是一对多关系,那么画个带箭头的线段指向 B; 如果是一对一,画两个带箭头的线段; 如果是多对多,画两个不带箭头的线段。 下图的 Course 和 Student 是一对多的关系。 表示出现多次的关系一个实体在联系出现几次,就要用几条线连接。 下图表示一个课程的先修关系,先修关系出现两个 Course 实体,第一个是先修课程,后一个是后修课程,因此需要用两条线来表示这种关系。 联系的多向性虽然老师可以开设多门课,并且可以教授多名学生,但是对于特定的学生和课程,只有一个老师教授,这就构成了一个三元联系。 表示子类用一个三角形和两条线来连接类和子类,与子类有关的属性和联系都连到子类上,而与父类和子类都有关的连到父类上。
2019-10-15
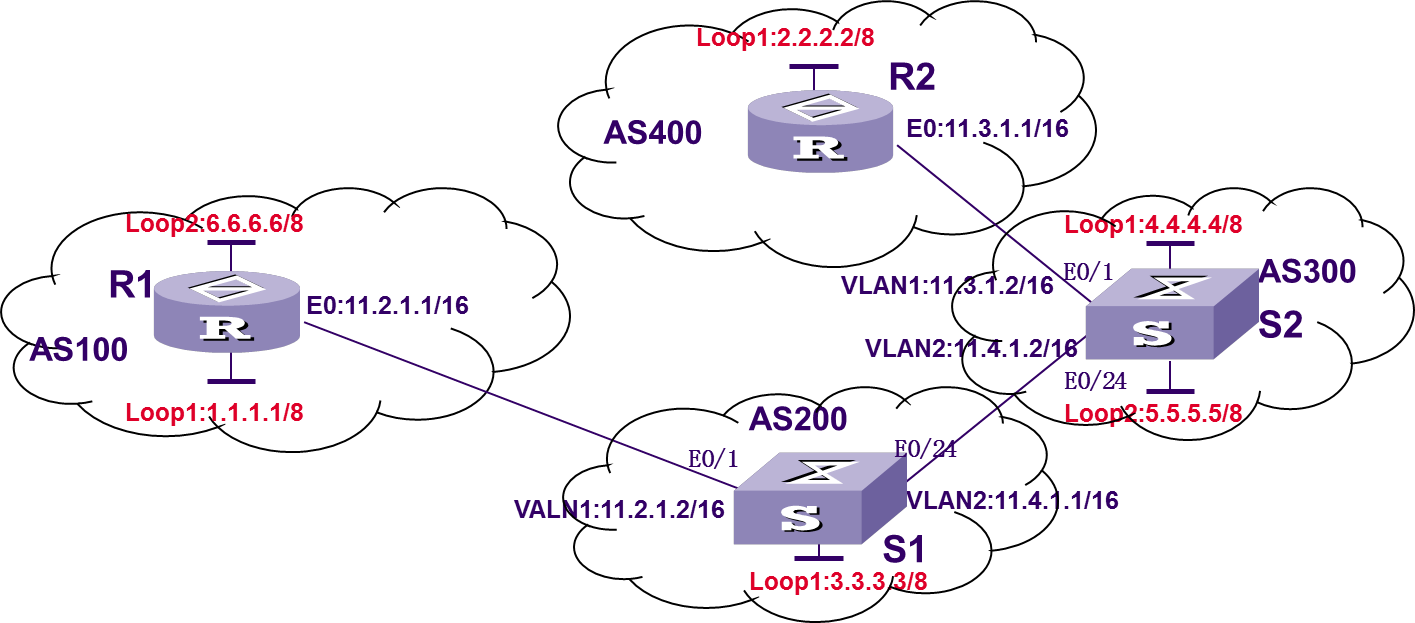
8 BGP实验
BGP实验目录 BGP协议基本分析 状态机的分析 BGP的路由聚合 BGP的基本路由属性分析 BGP的同步机制 BGP的路由策略及应用 BGP设计型实验 关于聚合问题需要进一步学习。包括链路层的端口聚合和OSPF与BGP的路由聚合 1 BGP基本分析BGP的路由只包含BGP路由器。仅指明下一跳。 BGP组成的AS之间的网络结构拓扑图是全连接的?并不是。 BGP协议中带有很多属性信息,便于进行路由策略和路由过滤。 对于路由的routing-table来说,OSPF与BGP是一样的,他们只是不同的路由信息传播策略与路由信息生成策略。但具体的路由过程是完全一致的。也就是说,最终都要提供目的地址和下一跳地址,生成路由表,进行路由转发。 1234567891011# 配置bgp对等体bgp 100peer 1.1.1.2 as-number 300peer 3.1.1.2 as-number 300address-family ipv4 unicastpeer 1.1.1.2 enablepeer 3.1.1.2 enablepeer 3.1.1.2 next-hop...




