
19 内存对齐
概述
概念
- 编译器为程序中的每个“数据单元”安排在适当的位置上。
原因
- 平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
- 性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
补充观点:字节对齐主要是为了提高内存的访问效率,比如intel 32位cpu,每个总线周期都是从偶地址开始读取32位的内存数据,如果数据存放地址不是从偶数开始,则可能出现需要两个总线周期才能读取到想要的数据,因此需要在内存中存放数据时进行对齐。
例如64位操作系统,存储32位int值。如果两个int值占用同一个64位的寻址空间,那么方位第二个int值,需要两次寻址过程。首先找到地址,然后得到偏移。
规则
每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。程序员可以通过预编译命令#pragma pack(n),n=1,2,4,8,16来改变这一系数,其中的n就是你要指定的“对齐系数”。
- 数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员的对齐按照#pragma pack指定的数值和这个数据成员自身长度中,比较小的那个进行。
- 结构(或联合)的整体对齐规则:在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将按照#pragma pack指定的数值和结构(或联合)最大数据成员长度中,比较小的那个进行。
- 结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储。
- 结合1、2可推断:当#pragma pack的n值等于或超过所有数据成员长度的时候,这个n值的大小将不产生任何效果。
结构体对齐规则
- 结构体变量的起始地址能够被其最宽的成员大小整除
- 结构体每个成员相对于起始地址的偏移能够被其自身大小整除,如果不能则在前一个成员后面补充字节
- 结构体总体大小能够被最宽的成员的大小整除,如不能则在后面补充字节
举例
可以通过预编译命令#pragma pack(n),n=1,2,4,8,16来改变这一系数,其中的n就是指定的“对齐系数”。
1 | #pragma pack(2) |
https://estom.github.io/2021/04/13/C++/%E9%9D%A2%E8%AF%95/19%20%E5%86%85%E5%AD%98%E5%AF%B9%E9%BD%90/
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2020-09-26
colorbar_placement
放置色块色标表示图像数据的定量范围。放置在一个图中并不重要,因为需要为它们腾出空间。 最简单的情况是将颜色条附加到每个轴: 123456789101112import matplotlib.pyplot as pltimport numpy as npfig, axs = plt.subplots(2, 2)cm = ['RdBu_r', 'viridis']for col in range(2): for row in range(2): ax = axs[row, col] pcm = ax.pcolormesh(np.random.random((20, 20)) * (col + 1), cmap=cm[col]) fig.colorbar(pcm, ax=ax)plt.show() 第一列在两行中都具有相同类型的数据,因此可能需要通过调用 Figure.colorbar 和轴列表而不是单个轴来组合我们所做的颜色栏。 12345...

2021-09-07
1.2-chinese
1.2 为什么使用并发?主要原因有两个:关注点分离(SOC)和性能。事实上,它们应该是使用并发的唯一原因;如果你观察得足够仔细,所有因素都可以归结到其中的一个原因(或者可能是两个都有。当然,除了像“就因为我愿意”这样的原因之外)。 1.2.1 为了分离关注点编写软件时,分离关注点是个好主意;通过将相关的代码与无关的代码分离,可以使程序更容易理解和测试,从而减少出错的可能性。即使一些功能区域中的操作需要在同一时刻发生的情况下,依旧可以使用并发分离不同的功能区域;若不显式地使用并发,就得编写一个任务切换框架,或者在操作中主动地调用一段不相关的代码。 考虑一个有用户界面的处理密集型应用——DVD播放程序。这样的应用程序,应具备这两种功能:一,要从光盘中读出数据,对图像和声音进行解码,之后把解码出的信号输出至视频和音频硬件,从而实现DVD的无误播放;二,还需要接受来自用户的输入,当用户单击“暂停”、“返回菜单”或“退出”按键的时候执行对应的操作。当应用是单个线程时,应用需要在回放期间定期检查用户的输入,这就需要把“DVD播放”代码和“用户界面”代码放在一起,以便调用。如果使用多线程方式来...
2021-03-09
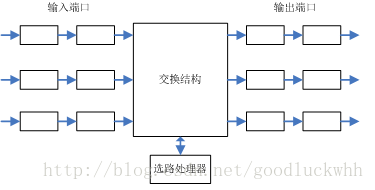
网络层概念学习之一(基本概念、路由器、选路算法)
网络层建立在链路层之上,它的最主要的功能是使得网络中的各个主机之间可以互相通信。在因特网中,IP层是TCP/IP协议族中最为核心的协议,也是最复杂的层次之一。 一、概述 1.转发和选路 网络层的功能是要将分组从一个主机移动到另一个主机从而使得主机之间可以互相通信。为此需要网络层提供两种功能: 存储转发:路由器(三层交换机)将进入其某个输入链路的分组转发到其某个输出链路。它是将分组从一个输入链路移动到一个输出链路,是一个路由器的本地动作。 路由选择:在分组从一个主机流向另一个主机的过程中,网络层必须决定分组所走过的路径。计算这个路径信息的算法就是路由算法。它是一个网络范围的动作,决定分组从其源到目的应该走的路径 路由器在网络层是一个极其重要的设备,每台路由器都由一张转发表。路由器检查到达分组首部中的一个字段的值,然后利用该值在路由器的转发表中进行查询,以决定该如何转发该分组。查询的结果是分组将被转发的路由器的链路接口。 选路算法决定了转发表中的值。选路算法可能是集中式(由某个中心点执行)的也可能是分布式的(运行在各台路由器上),无论采用何种方法,路由器都要接受选路协议报文...

2020-09-26
customize_rc
自定义Rc我不是想在这里做一个好看的人物,而只是为了展示一些动态定制rc params的例子 如果您希望以交互方式工作,并且需要为图形创建不同的默认设置(例如,一组用于发布的默认设置,一组用于交互式探索),您可能希望在自定义模块中定义一些设置默认值的函数, 例如,: 123456def set_pub(): rc('font', weight='bold') # bold fonts are easier to see rc('tick', labelsize=15) # tick labels bigger rc('lines', lw=1, color='k') # thicker black lines rc('grid', c='0.5', ls='-', lw=0.5) # solid gray grid lines rc('savefig', d...
2020-10-14
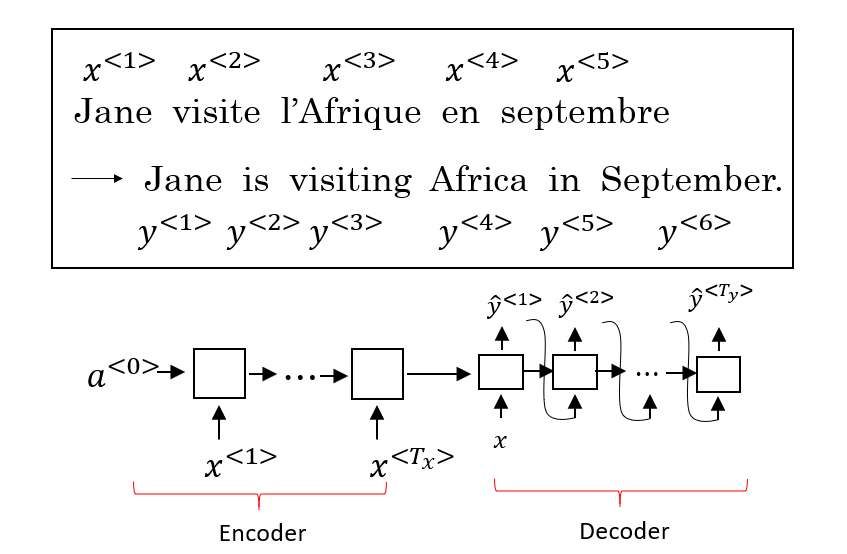
序列模型和注意力机制
序列模型和注意力机制Seq2Seq 模型 Seq2Seq(Sequence-to-Sequence) 模型能够应用于机器翻译、语音识别等各种序列到序列的转换问题。一个 Seq2Seq 模型包含 编码器(Encoder) 和 解码器(Decoder) 两部分,它们通常是两个不同的 RNN。如下图所示,将编码器的输出作为解码器的输入,由解码器负责输出正确的翻译结果。 提出 Seq2Seq 模型的相关论文: Sutskever et al., 2014. Sequence to sequence learning with neural networks Cho et al., 2014. Learning phrase representaions using RNN encoder-decoder for statistical machine translation 这种编码器-解码器的结构也可以用于图像描述(Image captioning)。将 AlexNet 作为编码器,最后一层的 Softmax 换成一个 RNN 作为解码器,网络的输出序列就是对图像的一个描...

2020-09-26
date_index_formatter2
日期索引格式化程序在绘制每日数据时,频繁的请求是绘制忽略跳过的数据,例如,周末没有额外的空格。这在金融时间序列中尤为常见,因为您可能拥有M-F而非Sat,Sun的数据,并且您不需要x轴上的间隙。方法是简单地使用xdata的整数索引和自定义刻度Formatter来获取给定索引的适当日期字符串。 输出: 1loading /home/tcaswell/mc3/envs/dd37/lib/python3.7/site-packages/matplotlib/mpl-data/sample_data/msft.csv 12345678910111213141516171819202122232425262728293031323334import numpy as npimport matplotlib.pyplot as pltimport matplotlib.cbook as cbookfrom matplotlib.dates import bytespdate2num, num2datefrom matplotlib.ticker import Formatterdataf...




