
附录2 MySql性能优化
性能调优
参考文献
0 基础方法
- 数据库设计优化:
- 选择合适的存储引擎
- 设计合理的表结构(符合3NF)
- 添加适当索引(index) 普通索引、主键索引、唯一索引、全文索引、组合索引、覆盖索引。
- 查询语句优化:
- 遵守查询规范。
- 分析日志:通过show status命令了解各种SQL的执行频率。定位执行效率较低的SQL语句(重点select,记录慢查询)
- explain分析低效率的SQL语句
- 查询过程优化
- 从内存中读取数据
- 减少磁盘写入操作(更大的写缓存)
- 提高磁盘读取速度(硬件设备改善)
1.1 存储引擎
- 支持全文索引:MyISAM
- 支持外键:Innodb
- 支持缓存:Innodb
- 支持事务:Innodb
- 支持并发:MyISAM 只支持表级锁,而 InnoDB 还支持行级锁。
- 支持备份:InnoDB 支持在线热备份。
- 崩溃恢复:MyISAM 崩溃后发生损坏的概率比 InnoDB 高很多,而且恢复的速度也更慢。
- 其它特性:MyISAM 支持压缩表和空间数据索引。
1.2 表结构
符合3BNF/EBNF范式
- 属性不可分
- 非主属性依赖完全的主属性
- 非主属性不依赖其他的非主属性
- 消除多值依赖(多对多关系)
1.3 添加索引
索引类型选择:
- 前缀索引。对于 BLOB、TEXT 和 VARCHAR 类型的列,必须使用前缀索引,只索引开始的部分字符。前缀长度的选取需要根据索引选择性来确定。字符串列加索引最好加短索引,即对前该列的前xx个字符,例如:key ‘ind_user_info_addr’ (addr(10)) USINGBTREE代表对addr列的前10个字符家索引。
- 复合索引。在需要使用多个列作为条件进行查询时,使用多列索引比使用多个单列索引性能更好。如果创建了一个(username,age,addr)的复合索引,那么相当于创建了(username,age,addr),(username,age),(username)三个索引,所以在创建复合索引的时候应该将最常用的限制条件的列放在最左边,依次递减。
索引使用规范:
- 不能再索引字段上计算。会导致索引无效,成为全表扫描。
- 将非”索引”数据分离,比如将大篇文章分离存储,不影响其他自动查询。
- 覆盖索引。能够直接通过索引查询到所需要的字段,不需要通过回表查询,找到数据。
- 关联查询。保证关联的字段都建立索引,并且字段类型一致,这样才能两个表都使用索引。如果字段类型不一样,至少一个表不能使用索引。保证连接的索引是相同类型。即a.age = b.age,a表的和b表的age字段类型保证一样,并且都建立了索引。
- 最左匹配原则:索引列如果使用like条件进行查询,那么 like ‘xxx%’ 可以使用索引,like ‘%xxx’ 不能使用索引。
- 索引列的值最好不要有null值。列中只要包含null,则不会被包含到索引中,复合索引中只要有一列为null值,则这个复合索引失效的。所以创建索引列不要设置默认值null
- 如果where条件中使用了一个列的索引,那么后面order by 在用这个列进行排序时,便不会再使用索引。where条件用到复合索引中的字段时,最好把该字段放在复合索引的左端,这样才能使用索引提高查询。
- 排序索引。尽量不要使用包含多个列的排序,如果需要则给这些列加上复合索引。
2.1 查询规范
- 减少请求的数据量。单条查询最后增加 LIMIT,停止全表扫描。
- 只返回必要的列:最好不要使用 SELECT * 语句。
- 只返回必要的行:使用 LIMIT 语句来限制返回的数据。
- 不用 MYSQL 内置的函数,因为内置函数不会建立查询缓存。
- inner join 内连接也叫做等值连接,left/right join 是外连接。能用inner join连接的尽量用inner join连接
- 尽量使用外连接来替换子查询。在使用on和where的时候,先用on,在用where。使用join时,用小的结果驱动大的结果(left join左表结果尽量小,如果有条件,先放左边处理,right join同理反向)。多表联合查询尽量拆分多个简单的sql语句进行查询。
- 尽量不要使用BY RAND()命令。减少排序order by。少用OR。尽量不要使用not in 和<> 操作
- 避免类型转换,也就是转入的参数类型要和字段类型一致。
- 不要在列上进行运算。
- 使用批量插入操作代替一个一个插入
- 对于多表查询可以建立视图。
2.2 分析日志
修改mysql的慢查询.
1 | show variables like 'long_query_time' ; //可以显示当前慢查询时间 |
记录所有查询,这在用 ORM 系统或者生成查询语句的系统很有用。
1 | log=/var/log/mysql.log |
注意不要在生产环境用,否则会占满你的磁盘空间。
记录执行时间超过 1 秒的查询:
1 | long_query_time=1 |
2.3 explain分析查询
分析方法
1 | Explain select * from emp where ename=“wsrcla” |
会产生如下信息:
- select_type:表示查询的类型。
- table:输出结果集的表
- type:表示表的连接类型
- possible_keys:表示查询时,可能使用的索引
- key:表示实际使用的索引
- key_len:索引字段的长度
- rows:扫描出的行数(估算的行数)
- Extra:执行情况的描述和说明
重构查询方式
1. 切分大查询
一个大查询如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
1 | DELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH); |
1 | rows_affected = 0 |
2. 分解大连接查询
将一个大连接查询分解成对每一个表进行一次单表查询,然后在应用程序中进行关联,这样做的好处有:
- 让缓存更高效。对于连接查询,如果其中一个表发生变化,那么整个查询缓存就无法使用。而分解后的多个查询,即使其中一个表发生变化,对其它表的查询缓存依然可以使用。
- 分解成多个单表查询,这些单表查询的缓存结果更可能被其它查询使用到,从而减少冗余记录的查询。
- 减少锁竞争;
- 在应用层进行连接,可以更容易对数据库进行拆分,从而更容易做到高性能和可伸缩。
- 查询本身效率也可能会有所提升。例如下面的例子中,使用 IN() 代替连接查询,可以让 MySQL 按照 ID 顺序进行查询,这可能比随机的连接要更高效。
1 | SELECT * FROM tag |
1 | SELECT * FROM tag WHERE tag='mysql'; |
3.1 内存读取
增大缓存
- 将更新操作先记录在change buffer,减少读磁盘,语句的执行速度会得到明显的提升。而且,数据读入内存是需要占用buffer pool的,所以这种方式还能够避免占用内存,提高内存利用率
- innodb_buffer_pool_size。将数据完全保存在 innodb_buffer_pool中。可以完全从内存中读取数据,最大限度减少磁盘操作。
数据预热
默认情况,只有某条数据被读取一次,才会缓存在 innodb_buffer_pool。数据库启动后,需要进行数据预热,将磁盘上的所有数据缓存到内存中。数据预热可以提高读取速度。
1 | SELECT DISTINCT |
3.2 减少磁盘读写
使用足够大的写入缓存innodb_log_file_size
- 如果用 1G 的 innodb_log_file_size ,假如服务器当机,需要 10 分钟来恢复。
- 推荐 innodb_log_file_size 设置为 0.25 * innodb_buffer_pool_size
innodb_flush_log_at_trx_commit
这个选项和写磁盘操作密切相关:
1 | innodb_flush_log_at_trx_commit = 1 则每次修改写入磁盘 |
如果你的应用不涉及很高的安全性 (金融系统),或者基础架构足够安全,或者事务都很小,都可以用 0 或者 2 来降低磁盘操作。
3.3 提高磁盘读取速度
4 其他原则
- 不在数据库做运算:cpu计算务必移至业务层
- 控制单表数据量:单表记录控制在1000w
- 控制列数量:字段数控制在20以内
- 平衡范式与冗余:为提高效率牺牲范式设计,冗余数据
- 拒绝3B:拒绝大sql,大事物,大批量
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐
2019-10-15
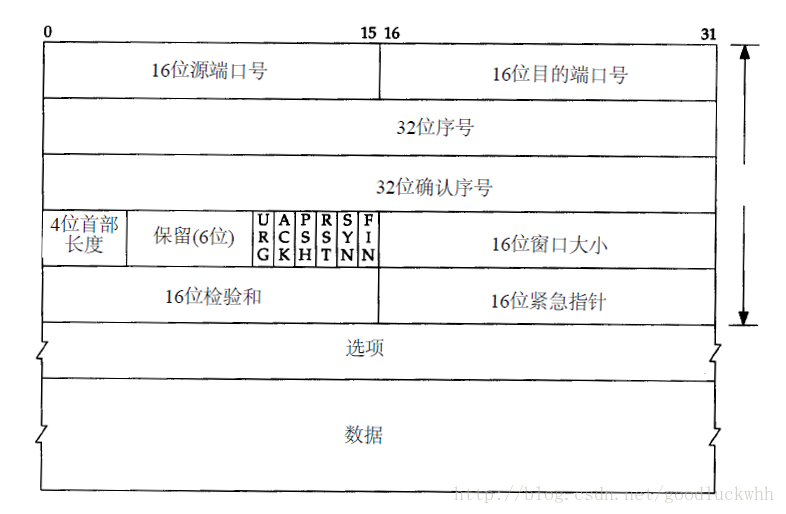
3.4 传输层-TCP
TCP 参考文献 TCP协议详解 TCP 1 概述 2 TCP报文 3 TCP的多路复用和解复用 4 TCP的状态迁移 状态迁移图 状态迁移图说明 5 TCP的连接管理 建立连接 终止连接 连接建立的超时 同时打开 同时关闭 复位连接 1 概述TCP提供的是一种面向连接的、可靠的字节流服务。 面向连接:使用TCP的两端在彼此交换数据之前必须先建立一个TCP连接。TCP连接是点对点的,在一个TCP连接中,仅有两方可以彼此通信,TCP不使用广播和多播。TCP的连接和电话网络的连接不同,它对中间的转发设备即路由器、交换机是透明的,连接的信息只存在于连接的两个端系统之上。 可靠:TCP保证数据传输的可靠性。 字节流:两个应用程序通过TCP连接交换8bit字节构成的字节流。字节流服务中,接收方无法了解发方每次发送了多少字节,可以确保的是一端将字节流放到TCP连接上,同样的字节流将出现在TCP连接的另一端。另外,TCP对字节流的内容不作任何解释。TCP不知道传输的数据字节流是二进制数据,还是ASCII字符、EBCDIC字符或者其他类型数据。对字节流的解释由TCP连接双...
2021-06-15
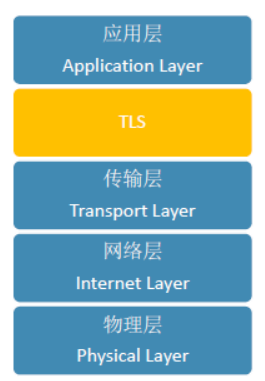
2 TLS加密协议
1 基本概念协议简介SSL/TLS是一种密码通信框架,他是世界上使用最广泛的密码通信方法。SSL/TLS综合运用了密码学中的对称密码,消息认证码,公钥密码,数字签名,伪随机数生成器等,可以说是密码学中的集大成者。 SSL(Secure Socket Layer)安全套接层,是1994年由Netscape公司设计的一套协议,并与1995年发布了3.0版本。 TLS(Transport Layer Security)传输层安全是IETF在SSL3.0基础上设计的协议,实际上相当于SSL的后续版本。 加密算法包括秘钥生成、加密、解密三个主要过程。 非对称加密算法:RSA,DSA/DSS,Diffie–Hellman。协商对称加密的共享密钥。(也称为主密钥或者会话密钥) 对称加密算法:AES,RC4,3DES。用来加密数据 秘钥生成算法:premaster secret、master secret 消息摘要算法消息摘要算法即HASH算法,消息摘要(Message Digest)简要地描述了一分较长的信息或文件,它可以被看做一分长文件的数字指纹。主要分...
2022-11-27
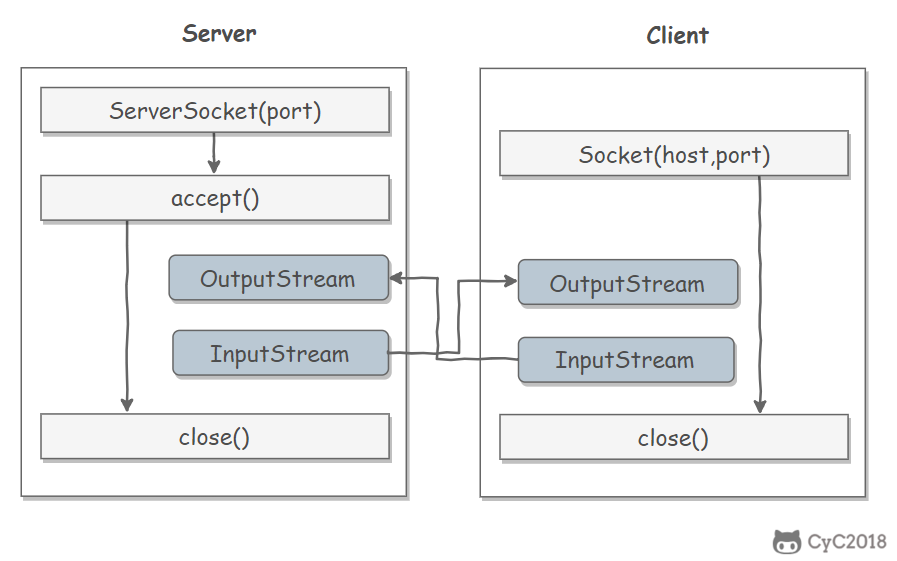
05 Java IO网络
网络操作 https://blog.csdn.net/forezp/article/details/88414741 1 网络编程基础Java 中的网络支持: InetAddress:用于表示网络上的硬件资源,即 IP 地址; URL:统一资源定位符; Sockets:使用 TCP 协议实现网络通信; Datagram:使用 UDP 协议实现网络通信。 InetAddress没有公有的构造函数,只能通过静态方法来创建实例。 12InetAddress.getByName(String host);InetAddress.getByAddress(byte[] address); URL可以直接从 URL 中读取字节流数据。 1234567891011121314151617181920public static void main(String[] args) throws IOException { URL url = new URL("http://www.baidu.com"); /* 字节流 */ InputStre...

2021-12-24
lvcreate
lvcreate用于创建LVM的逻辑卷 补充说明lvcreate命令 用于创建LVM的逻辑卷。逻辑卷是创建在卷组之上的。逻辑卷对应的设备文件保存在卷组目录下,例如:在卷组”vg1000”上创建一个逻辑卷”lvol0”,则此逻辑卷对应的设备文件为”/dev/vg1000/lvol0”。 语法1lvcreate(选项)(参数) 选项12-L:指定逻辑卷的大小,单位为“kKmMgGtT”字节;-l:指定逻辑卷的大小(LE数)。 参数逻辑卷:指定要创建的逻辑卷名称。 实例使用lvcreate命令在卷组”vg1000”上创建一个200MB的逻辑卷。在命令行中输入下面的命令: 1[root@localhost ~]# lvcreate -L 200M vg1000 #创建大小为200M的逻辑卷 输出信息如下: 1Logical volume "lvol0" created 说明:创建成功后,新的逻辑卷”lvol0”,将通过设备文件/dev/vg1000/lvol0进行访问。
2021-03-20
13
1.12. 多类和多标签算法校验者: @溪流-十四号 @大魔王飞仙 @Loopy翻译者: @v 警告 scikit-learn中的所有分类器都可以开箱即用进行多类分类。除非您想尝试不同的多类策略,否则无需使用sklearn.multiclass模块。 sklearn.multiclass 模块采用了 元评估器 ,通过把多类 和 多标签 分类问题分解为 二元分类问题去解决。这同样适用于多目标回归问题。 Multiclass classification 多类分类 意味着一个分类任务需要对多于两个类的数据进行分类。比如,对一系列的橘子,苹果或者梨的图片进行分类。多类分类假设每一个样本有且仅有一个标签:一个水果可以被归类为苹果,也可以 是梨,但不能同时被归类为两类。 Multilabel classification 多标签分类 给每一个样本分配一系列标签。这可以被认为是预测不相互排斥的数据点的属性,例如与文档类型相关的主题。一个文本可以归类为任意类别,例如可以同时为政治、金融、 教育相关或者不属于以上任何类别。 Mul...

2021-12-24
mail
mail命令行下发送和接收电子邮件 补充说明mail命令 是命令行的电子邮件发送和接收工具。操作的界面不像elm或pine那么容易使用,但功能非常完整。 语法1mail(选项)(参数) 选项12345678910-b<地址>:指定密件副本的收信人地址;-c<地址>:指定副本的收信人地址;-f<邮件文件>:读取指定邮件文件中的邮件;-i:不显示终端发出的信息;-I:使用互动模式;-n:程序使用时,不使用mail.rc文件中的设置;-N:阅读邮件时,不显示邮件的标题;-s<邮件主题>:指定邮件的主题;-u<用户帐号>:读取指定用户的邮件;-v:执行时,显示详细的信息。 参数邮件地址:收信人的电子邮箱地址。 实例 直接使用shell当编辑器 123mail -s "Hello from jsdig.com by shell" admin@jsdig.comhello,this is the content of mail.welcome to www.jsdig.com 第一行是输入的命令,-s表示...




