
32 数据集和数据加载器
数据集和数据加载器
1 torchvision.datasets 官方数据集加载
我们使用以下参数加载FashionMNIST 数据集:
- root 是存储训练/测试数据的路径,
- train 指定训练或测试数据集,
- download=True如果数据不可用,则从 Internet 下载数据root。
- transform并target_transform指定特征和标签转
1 | import torch |
对加载的数据集进行可视化显示
1 | labels_map = { |
2 自定义dataset加载数据集
- 自定义 Dataset 类必须实现三个函数:init、len__和__getitem。看看这个实现;FashionMNIST 图像存储在一个目录中img_dir,它们的标签单独存储在一个 CSV 文件中annotations_file。
1 | import os |
- init 函数在实例化 Dataset 对象时运行一次。我们初始化包含图像、注释文件和两个转换的目录
- len 函数返回我们数据集中的样本数。
- getitem 函数从给定索引处的数据集中加载并返回一个样本idx。基于索引,它识别图像在磁盘上的位置,使用 将其转换为张量read_image,从 中的 csv 数据中检索相应的标签self.img_labels,调用它们的变换函数(如果适用),并返回张量图像和相应的标签一个元组。
3 使用DataLoader进行训练
- 我们已将该数据集加载到 中,Dataloader并且可以根据需要遍历数据集。下面的每次迭代都会返回一批train_features和train_labels(batch_size=64分别包含特征和标签)。因为我们指定了shuffle=True,在我们遍历所有批次后,数据会被打乱
1 | # Display image and label. |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2020-10-09
09神经网络实例
假设函数 神经网络本身,即是假设函数能够计算输入相对的输出。 代价函数 $L$表示神经网络的总层数。 $s_L$表示第L层单元的个数。 $K$表示输出层单元的个数 代价函数相当于第i组数据输入时,产生的误差。 $$J(\theta)=-\frac{1}{m}[\sum_i^my^{(i)}\log h_\theta(x^{(i)})+(1-y^{(i)})\log (1-h_\theta (x^{(i)}))]+\frac{\lambda}{2m}\sum_1^n\theta_j^2$$ $a^{(i)}$表示第i层的单元值。 $\Theta^{(i)}$第i层的权重 $z^{(i)}$第i层的加权值 $\delta^{(i)}$第i层的反向传播误差。 最小化代价函数:反向传播算法 在这里的上标,代表的不是输入的代数(即第几次迭代),而是神经网络的层数。下标表示的是神经网络某层的单元数。 原理:神经网络的值会随着假设函数正向传播。神经网络的误差会随着假设函数反向传播到第二层。利用每一层的单元值和神经网络的误差能够计算每一层的梯度下降向量,通过梯度下降向量,完成参...

2021-12-24
jq
jq一个灵活的轻量级命令行JSON处理器 补充说明jq 是 stedolan 开发的一个轻量级的和灵活的命令行JSON处理器,源码请参考 jq 项目主页 jq 用于处理JSON输入,将给定过滤器应用于其JSON文本输入并在标准输出上将过滤器的结果生成为JSON。 最简单的过滤器是.,它将jq的输入未经修改地复制到其输出中(格式设置除外)。 请注意,jq 当前仅支持64位双精度浮点数(IEEE754)。 安装12345# Debian系,如 Ubuntusudo apt-get install jq# RedHat系, 如 CentOSyum install jq 语法123jq [options] <jq filter> [file...]jq [options] --args <jq filter> [strings...]jq [options] --jsonargs <jq filter> [JSON_TEXTS...] 选项1234567891011121314151617-c 紧凑而不是漂亮的输出;-n...
2021-04-07
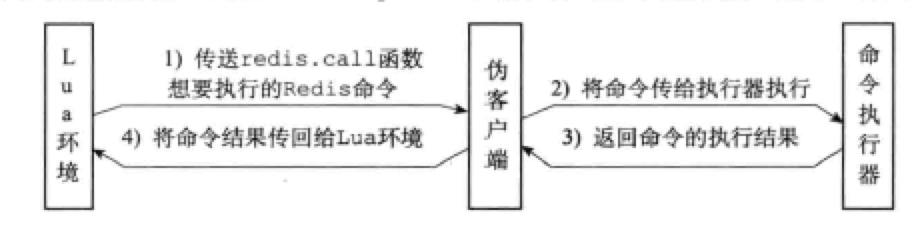
20 Lua脚本
Redis从2.6版本开始引入对Lua脚本的支持,通过在服务器中嵌入Lua环境,Redis客户端可以使用Lua脚本,直接在服务器原子地执行多个Redis命令。 EVAL命令可以直接对输入的脚本进行求值: EVAL “return ‘hello world’” 0 “hello world” EVALSHA命令可以根据脚本的SHA1校验和来对脚本进行求值,但这个命令要求校验和对应的脚本至少被EVAL命令执行过一次,或者被SCRIPT LOAD命令载入过。 20.1 创建并修改Lua环境Redis服务器创建并修改Lua环境的整个过程有以下步骤: 创建一个基础的Lua环境 载入多个函数库到Lua环境 创建全局表格redis,表格包含了对Redis进行操作的函数,如redis.call 使用Redis自制的随机函数来替换Lua原有的带有副作用的随机函数 创建排序辅助函数 创建redis.pcall函数的错误报告辅助函数,这个函数可以提供更详细的出错信息 对Lua环境中的全局变量进行保护,防止用户在执行Lua脚本时添加额外的全局变量 将完成修改的Lua环境保存到服务器状态的lua属性...
2021-03-22
04 Pytorch nn本质
torch.nn到底是什么? 0 MNIST 数据集 1 从零开始的神经网络(没有torch.nn) 2 使用torch.nn.functional 3 使用nn.Module重构 4 使用nn.Linear重构 5 使用optim重构 6 使用Dataset重构 7 使用DataLoader重构 8 添加验证 8 创建fit()和get_data() 9 切换到 CNN nn.Sequential 9 包装DataLoader 10 使用您的 GPU 总结 torch.nn到底是什么?PyTorch 提供设计精美的模块和类torch.nn,torch.optim,Dataset和DataLoader神经网络。 为了充分利用它们的功能并针对您的问题对其进行自定义,您需要真正了解它们在做什么。 为了建立这种理解,我们将首先在 MNIST 数据集上训练基本神经网络,而无需使用这些模型的任何功能。 我们最初将仅使用最基本的 PyTorch 张量函数。 然后,我们将一次从torch.nn,torch.optim,Dataset或DataLoader中逐个添加一个函数,以准确显示每...

2021-09-07
A.5-chinese
A.5 Lambda函数lambda函数在C++11中的加入很是令人兴奋,因为lambda函数能够大大简化代码复杂度(语法糖:利于理解具体的功能),避免实现调用对象。C++11的lambda函数语法允许在需要使用的时候进行定义。能为等待函数,例如std::condition_variable(如同4.1.1节中的例子)提供很好谓词函数,其语义可以用来快速的表示可访问的变量,而非使用类中函数来对成员变量进行捕获。 最简单的情况下,lambda表达式就一个自给自足的函数,不需要传入函数仅依赖管局变量和函数,甚至都可以不用返回一个值。这样的lambda表达式的一系列语义都需要封闭在括号中,还要以方括号作为前缀: 1234[]{ // lambda表达式以[]开始 do_stuff(); do_more_stuff();}(); // 表达式结束,可以直接调用 例子中,lambda表达式通过后面的括号调用,不过这种方式不常用。一方面,如果想要直接调用,可以在写完对应的语句后,就对函数进行调用。对于函数模板,传递一个参数进去时很常见的事情,甚至可以将可调用对象...

2021-04-06
MATLAB8
MATLAB二维底层绘图的修饰> 对象和句柄 似乎MATLAB也能满足面向对象编程的一些条件诶!MATLAB也能实现GUI图形用户界面编程,同强大的C++、Java有一拼 对象和句柄的概念 MATLAB吧构成图形的各个基本要素成为图形对象,产生每一个图形对象时,MATLAB会自动分配一个唯一的值,用于表示这个对象,成为句柄(好像子对象和指向对象的指针) 对象间的基本关系 计算机屏幕->图形窗口->(用户菜单,用户控件,坐标轴) 坐标轴->(曲线,曲面,文字,图像,光源,区域,方框) > 基本地城绘图函数 line对象 h = line([-pi:0.01:pi],sin([-pi:0.01:pi])); 其中h成为line曲线对象的句柄。 line对象的修饰 color属性 LineWidth属性 LineStyle属性 Marker属性 MarkerSize属性 plot函数能够产生line对象,然后继续对返回的句柄进行操作、或者直接在绘制过程进行修饰。 h1 = line('XData',[-pi:0....




