
90 API-RPC
远程通信和分布式训练的框架。
可以学习一下,用来实现pysyft的过程。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2021-03-12
4 队列
队列1 简介概念 队列可以定义为有序列表。在一端执行插入操作rear,删除操作在另一端执行,称为front。 队列被称为先进先出列表。 应用 单个共享资源(如打印机,磁盘,CPU)的等待列表。 异步数据传输。管道,文件IO,套接字。 缓冲区. 操作系统中处理中断。 时间复杂度 时间复杂性 访问 搜索 插入 删除 平均情况 θ(n) θ(n) θ(1) θ(1) 最坏情况 θ(n) θ(n) θ(1) θ(1) 2 队列的操作基本操作 创建 遍历(显示第一个元素) 插入 删除 3 队列的实现队列的数组实现123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103#include<stdio.h> #in...

2022-12-05
28.你知道哪些设计模式?分别对应的应用场景有哪些?
你知道哪些设计模式?分别对应的应用场景有哪些?上一课时我们讲了单例模式的 8 种实现方式以及它的优缺点,可见设计模式的内容是非常丰富且非常有趣。我们在一些优秀的框架中都能找到设计模式的具体使用,比如前面 MyBatis 中(第 13 课时)讲的那些设计模式以及具体的使用场景,但由于设计模式的内容比较多,有些常用的设计模式在 MyBatis 课时中并没有讲到。因此本课时我们就以全局的视角,来重点学习一下这些常用设计模式。 我们本课时的面试题是,你知道哪些设计模式?它的使用场景有哪些?它们有哪些优缺点? 典型回答设计模式从大的维度来说,可以分为三大类:创建型模式、结构型模式及行为型模式,这三大类下又有很多小分类。 创建型模式是指提供了一种对象创建的功能,并把对象创建的过程进行封装隐藏,让使用者只关注具体的使用而并非对象的创建过程。它包含的设计模式有单例模式、工厂模式、抽象工厂模式、建造者模式及原型模式。 结构型模式关注的是对象的结构,它是使用组合的方式将类结合起来,从而可以用它来实现新的功能。它包含的设计模式是代理模式、组合模式、装饰模式及外观模式。 行为型模式关注的是对象的行为,它...

2022-12-05
13.MyBatis使用了哪些设计模式?在源码中是如何体现的?
MyBatis 使用了哪些设计模式?在源码中是如何体现的?MyBatis 的前身是 IBatis,IBatis 是由 Internet 和 Abatis 组合而成,其目的是想当做互联网的篱笆墙,围绕着数据库提供持久化服务的一个框架,2010 年正式改名为 MyBatis。它是一款优秀的持久层框架,支持自定义 SQL、存储过程及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作,还可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Ordinary Java Object,普通 Java 对象)为数据库中的记录。 关于 MyBatis 的介绍与使用,官方已经提供了比较详尽的中文参考文档,可点击这里查看,而本课时则以面试的角度出发,聊一聊不一样的知识点,它也是 MyBatis 比较热门的面试题之一,MyBatis 使用了哪些设计模式?在源码中是如何体现的? 注意:本课时使用的 MyBatis 源码为 3.5.5。 典型回答1.工厂模式工厂模式想必都比较熟悉,它是 Java 中最常用的设计模式之一。工厂模式就...
2020-01-05
4.5 约瑟夫问题
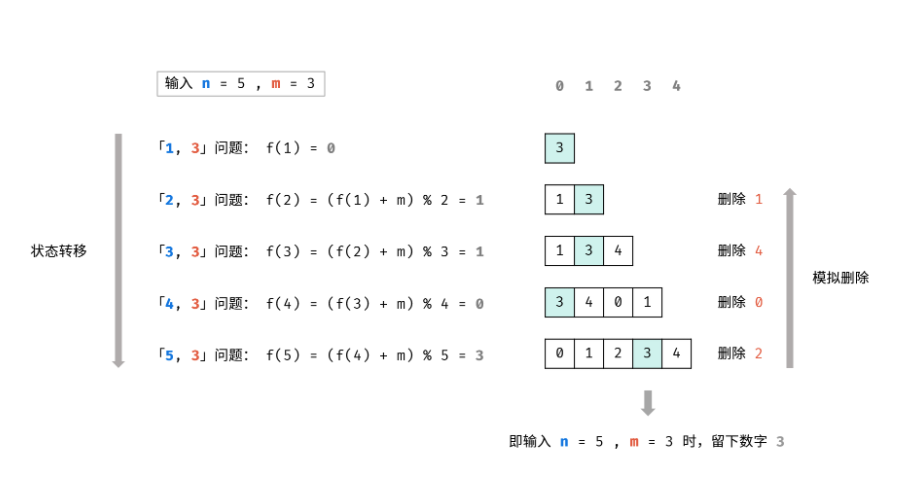
约瑟夫问题问题描述一堆人围城环。每次淘汰第m个人。最终剩下谁。 问题分析算法设计我们将上述问题建模为函数 f(n, m),该函数的返回值为最终留下的元素的序号。 首先,长度为 n 的序列会先删除第 m % n 个元素,然后剩下一个长度为 n - 1 的序列。那么,我们可以递归地求解 f(n - 1, m),就可以知道对于剩下的 n - 1 个元素,最终会留下第几个元素,我们设答案为 x = f(n - 1, m)。 由于我们删除了第 m % n 个元素,将序列的长度变为 n - 1。当我们知道了 f(n - 1, m) 对应的答案 x 之后,我们也就可以知道,长度为 n 的序列最后一个删除的元素,应当是从 m % n 开始数的第 x 个元素。因此有 f(n, m) = (m % n + x) % n = (m + x) % n。 算法分析算法实现 递归 12345678910111213class Solution { int f(int n, int m) { if (n == 1) { ...
2021-03-04
5.C++内存分配
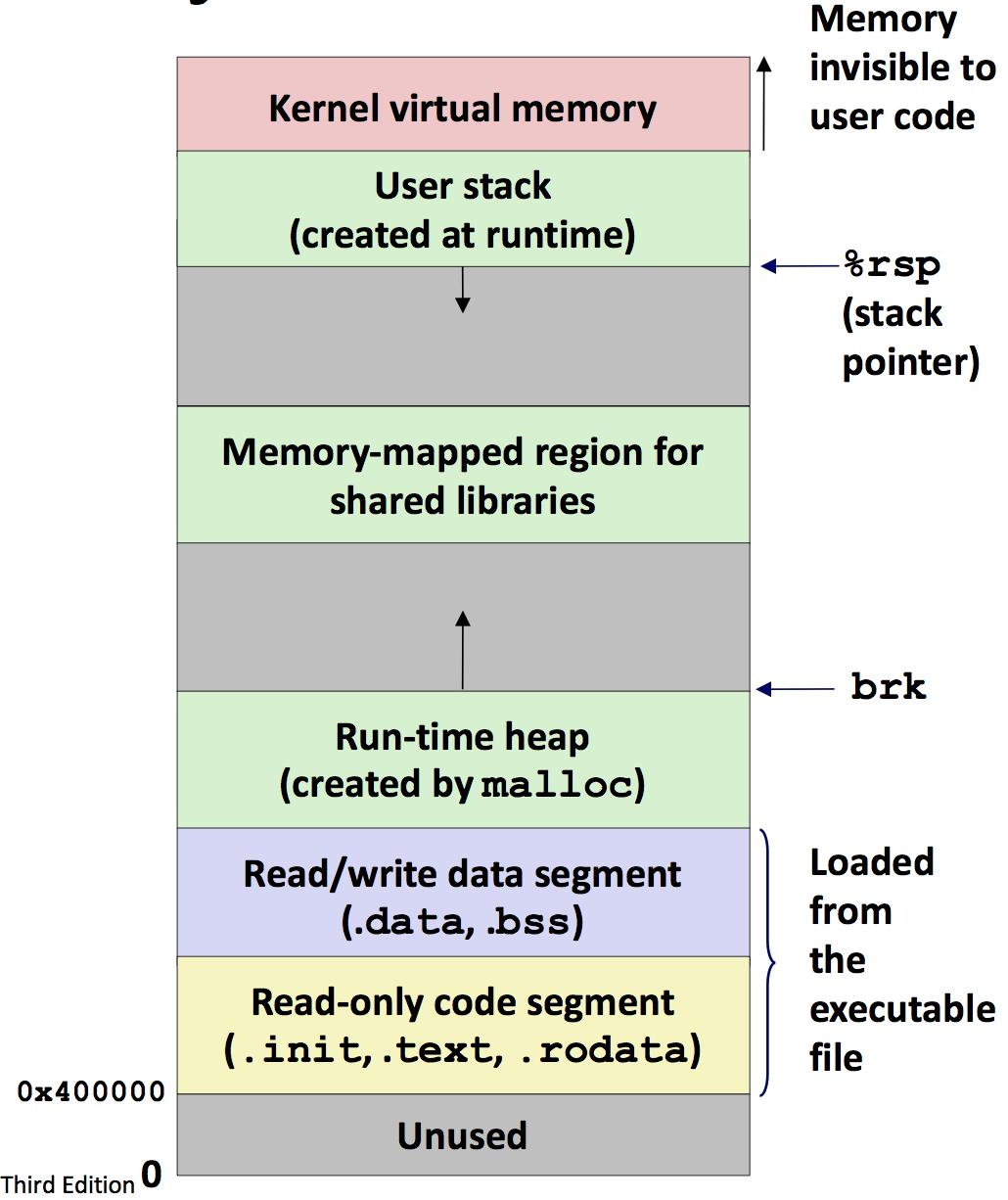
内存分配内存分配示意图 Unused Memory:用于程序代码块对齐Read-only code segment:只读,存代码和一些其他的东西 Read/Write data segment: .data:存初始化的全局变量和static变量,另外还有文字常量区,常量字符串就是放在这里,程序结束后有系统释放 .bss:存未初始化的全局变量和static变量 Heap:通过new和malloc由低到高分配,由delete或free手动释放或者程序结束自动释放 Shared libraries:调用的库文件,位于堆和栈之间 Stack:由高向低增长,和堆的增长方式相对,对不同的OS来说,栈的初始大小有规定,可以修改,目前默认一般为2M,由编译器自动分配释放 Kernel virtual memory:用户不可见不能访问 内存分配说明C/C++编译的程序所占用内存区域一般分为以下5个部分: 栈区(stack):由编译器自动分配和释放,用来存放函数的参数、局部变量等。其操作方式类似于数据结构中的栈。 堆区(heap):一般由程序员分配和释放(通过mallo...
2020-09-27
15.大数据与MapReduce
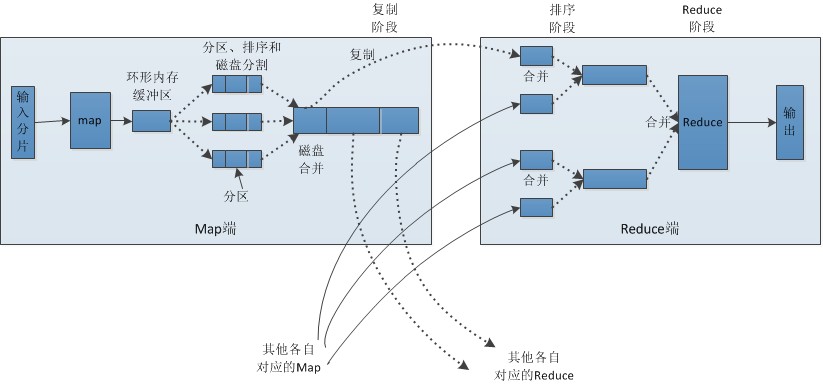
第15章 大数据与MapReduce大数据 概述大数据: 收集到的数据已经远远超出了我们的处理能力。 大数据 场景1234假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则随意浏览后就离开。对于你来说,可能很想识别那些有购物意愿的用户。那么问题就来了,数据集可能会非常大,在单机上训练要运行好几天。接下来: 我们讲讲 MapRedece 如何来解决这样的问题 MapRedeceHadoop 概述12Hadoop 是 MapRedece 框架的一个免费开源实现。MapReduce: 分布式的计算框架,可以将单个计算作业分配给多台计算机执行。 MapRedece 原理 MapRedece 工作原理 主节点控制 MapReduce 的作业流程 MapReduce 的作业可以分成map任务和reduce任务 map 任务之间不做数据交流,reduce 任务也一样 在 map 和 reduce 阶段中间,有一个 sort 和 combine 阶段 数据被重复存放在不同的机器上,以防止某个机器失效 mapper 和 reducer 传输的数据形式为 ke...




