
10.0-chinese
第10章 多线程程序的测试和调试
本章主要内容
- 并发相关的错误
- 定位错误和代码审查
- 设计多线程测试用例
- 多线程代码的性能
目前为止,我们了解如何写并发代码——可以使用哪些工具,这些工具应该如何使用。不过,在软件开发中重要的一部分我们还没有提及:测试与调试。如果你希望阅读完本章后就能很轻松的去调试并发代码,本章无法满足你的预期。
测试和调试并发代码比较麻烦。除了对一些重要问题的思考,我也会展示一些技巧让测试和调试变得简单一些。
测试和调试就像一个硬币的两面——测试是为了找到代码中可能存在的错误,需要调试来修复错误。如果在开发阶段发现了某个错误,而非发布后发现,这将会将使错误的破坏力降低好几个数量级。
了解测试和调试前,需要了解并发代码可能会出现的问题。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐
2021-03-20
21
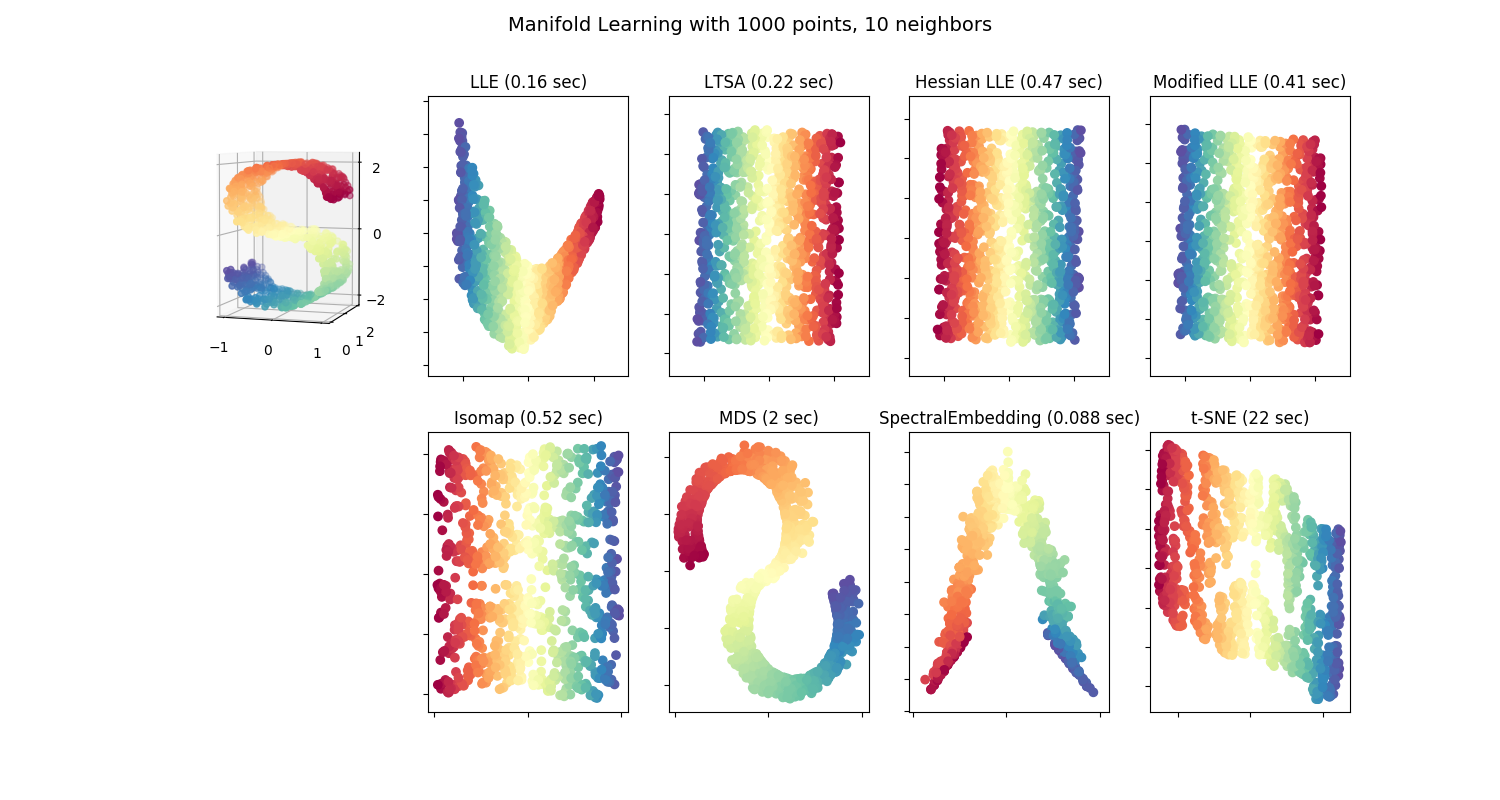
2.2. 流形学习校验者: @XuJianzhi @RyanZhiNie @羊三 @Loopy @barrycg翻译者: @XuJianzhi @羊三 Look for the bare necessities The simple bare necessities Forget about your worries and your strife I mean the bare necessitiesOld Mother Nature’s recipes That bring the bare necessities of life – Baloo的歌 [奇幻森林] 流形学习是一种非线性降维方法。其算法基于的思想是:许多数据集维度过高的现象完全是人为导致得。 2.2.1. 介绍高维数据集通常难以可视化。虽然,可以通过绘制两维或三维的数据来...
2021-03-20
30
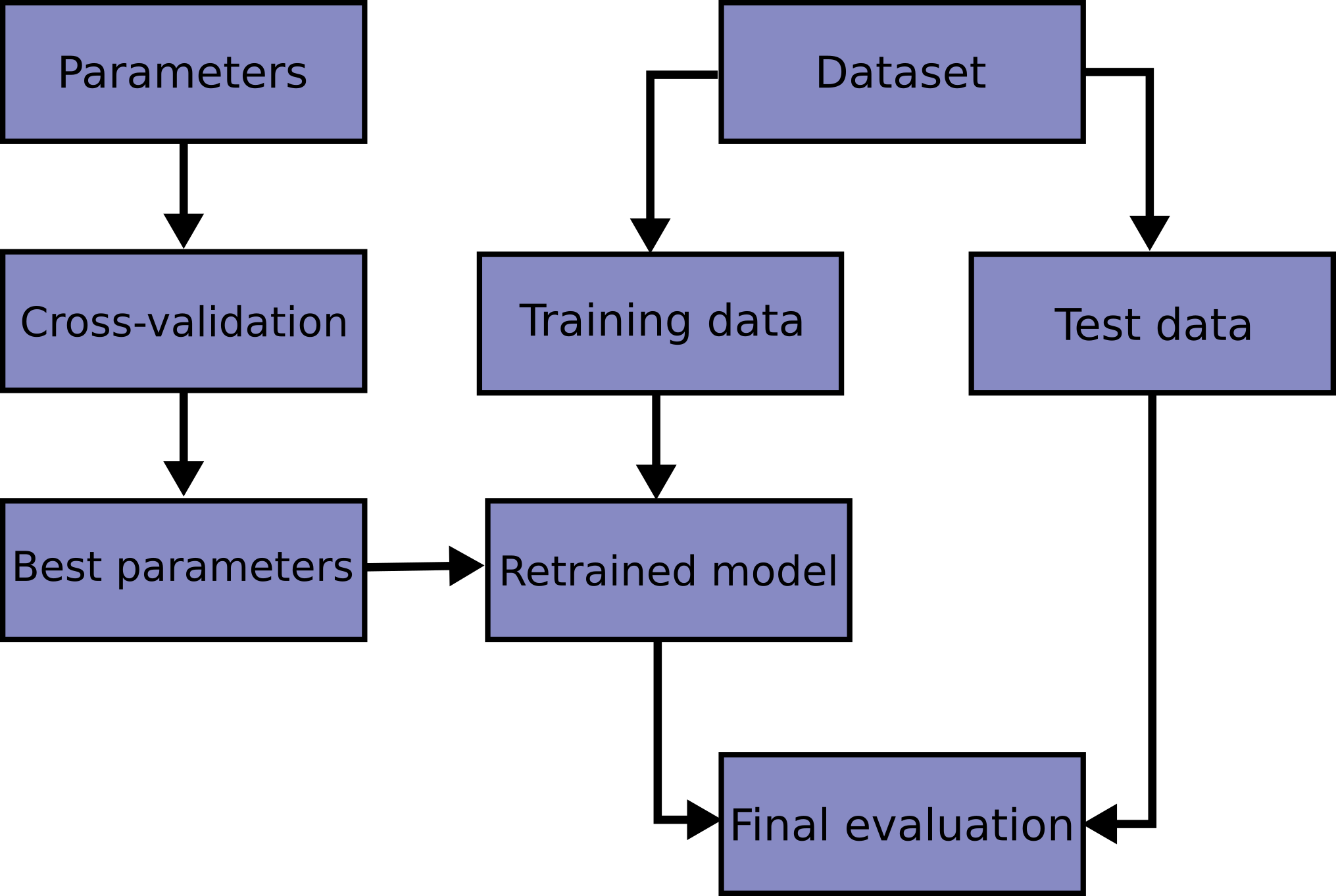
3.1. 交叉验证:评估估算器的表现校验者: @想和太阳肩并肩 @樊雯 @Loopy翻译者: @\S^R^Y/ 学习预测函数的参数,并在相同数据集上进行测试是一种错误的做法: 一个仅给出测试用例标签的模型将会获得极高的分数,但对于尚未出现过的数据它则无法预测出任何有用的信息。 这种情况称为 overfitting(过拟合). 为了避免这种情况,在进行(监督)机器学习实验时,通常取出部分可利用数据作为 test set(测试数据集) X_test, y_test。需要强调的是这里说的 “experiment(实验)” 并不仅限于学术(academic),因为即使是在商业场景下机器学习也往往是从实验开始的。下面是模型训练中典型的交叉验证工作流流程图。通过网格搜索可以确定最佳参数。 利用 scikit-learn 包中的 train_test_split 辅助函数可以很快地将实验数据集划分为任何训练集(training sets)和测试集(test sets)。 下面让我们载入 iris 数据集,并在此数据集上训练出线...

2021-09-02
17-并发编程
基于原文 Go语言基础之并发 和 视频 93-111 整理。 17 Go语言中的并发编程并发是编程里面一个非常重要的概念,Go语言在语言层面天生支持并发,这也是Go语言流行的一个很重要的原因。 17.1 并发与并行 并发:同一时间段内执行多个任务(你在用微信和两个女朋友聊天,一个主体同一时间做多个任务)。 并行:同一时刻执行多个任务(你和你朋友都在用微信和女朋友聊天,多个主体同一时间做多个任务)。 Go 语言的并发通过 goroutine 实现。goroutine 类似于线程,属于用户态的线程,我们可以根据需要创建成千上万个 goroutine 并发工作。goroutine 是由 Go 语言的运行时(runtime)调度完成,而线程是由操作系统调度完成。 Go 语言还提供 channel 在多个 goroutine 间进行通信。 goroutine 和 channel 是 Go 语言秉承的 CSP(Communicating Sequential Process)并发模式的重要实现基础。 17.2 goroutine在 java/c++ 中我们要实现并发编程的时候...
2019-10-12
1 自顶向下的计算机网络概述
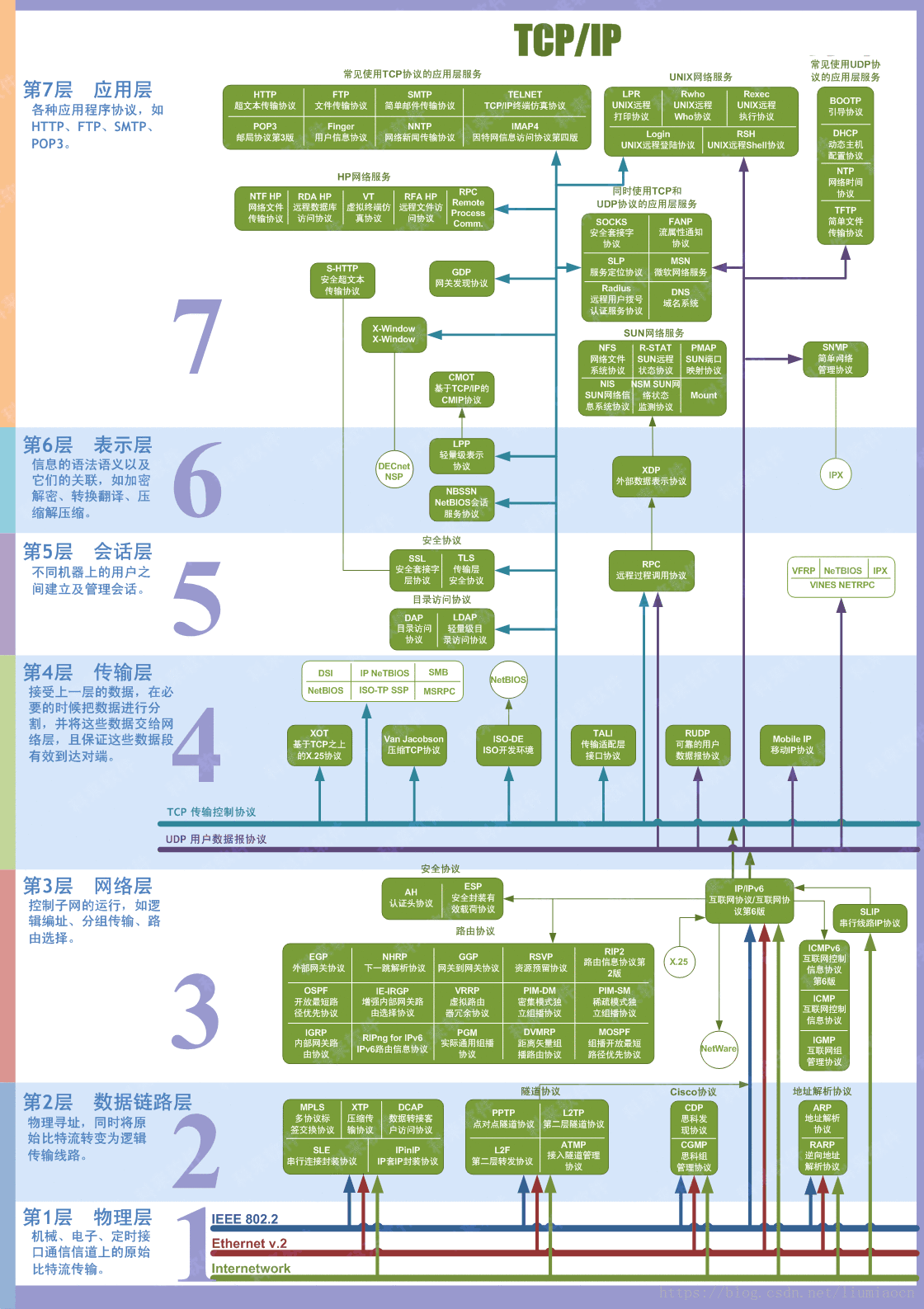
计算机网络概述1 五层模型 每一层都有自己的数据单位或者说数据结构。每一个传输单位都采用了消息头+数据的组合方式用来传输数据。底层对上层的数据内容进行分割与封装,形成底层数据单位,以达到不同的目的。 应用层(application layer) 专门针对某些应用提供服务 数据单位:报文Message 传输层(transport layer) 负责不同主机的进程间的传输。从源主机的进程到目的主机的进程。实现端到端通信。 数据单位:报文段Segment 网络层(network layer) 负责从源地址(source)到目的地地址(destination)的传输,从源主机传输数据到目标主机。实现点到点通信(point to point) 数据单位:数据报datagram 数据链路层(data-link layer) 封装数据报。负责一条连路上,一个节点到另一个节点的传输。单跳(hop-by-hop, node-to-node) 数据单位:帧Frame 物理层(physical layer) 通过线路传送比特(bit)流,只完成一个节点到另一个节点的传输(单跳) 数据单位:比...

2021-12-24
skill
skill向选定的进程发送信号冻结进程 补充说明skill命令 用于向选定的进程发送信号,冻结进程。这个命令初学者并不常用,深入之后牵涉到系统服务优化之后可能会用到。 语法1skill(选项) 选项123456789-f:快速模式;-i:交互模式,每一步操作都需要确认;-v:冗余模式;-w:激活模式;-V:显示版本号;-t:指定开启进程的终端号;-u:指定开启进程的用户;-p:指定进程的id号;-c:指定开启进程的指令名称。 实例如果您发现了一个占用大量CPU和内存的进程,但又不想停止它,该怎么办?考虑下面的top命令输出: 1234567891011top -c -p 1651423:00:44 up 12 days, 2:04, 4 users, load average: 0.47, 0.35, 0.311 processes: 1 sleeping, 0 running, 0 zombie, 0 stoppedCPU states: cpu user nice system irq softirq iowait idle ...

2020-01-02
9 随机化
随机化算法随机算法的概述 将算法必须对所有可能的输入都正确地求解问题的条件放宽,只要求它的可能不正确性解能够相对安全地忽略掉,比如说它的出现可能性非常低;而且也不要求对于特定的输入,算法的每一次运行的输出都必须相同。 随机算法可以做如下定义:它是在接收输入的同时,为了随机选择的目的,还接收一串随机比特流并且在运行过程中使用该比特流的算法。 一个随机算法在不同的运行中对于相同的输入可以有不同的结果。由此得出对于相同的输入两次不同的随机算法的执行时间可能不同。 随机算法的优点 首先,较之那些我们所知的解决同一问题最好的确定性算法,随机算法所需的运行时间或空间通常常小一些; 其次,观察迄今为止已经发明的各种随机算法,我们发现这些算法总是易于理解和实现。 1 伪随机数伪随机数的产生$$\begin{cases} a_0=d\ a_n=(ba_{n-1}+c) mod m\end{cases}$$ 其中$a\geq 0,b\geq0,d\geq m,d$是随机序列种子。 2 数值随机化算法3 舍伍德算法 确定性算法随机化。 4 蒙特卡洛算法 蒙特...




