
groupmod
groupmod
更改群组识别码或名称
补充说明
groupmod命令 更改群组识别码或名称。需要更改群组的识别码或名称时,可用groupmod指令来完成这项工作。
语法
1 | groupmod(选项)(参数) |
选项
1 | -g<群组识别码>:设置欲使用的群组识别码; |
参数
组名:指定要修改的工作的组名。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2021-03-20
plot_lasso_model_selection
Lasso模型选择:交叉验证 / AIC / BIC 翻译者:@Loopy校验者:@barrycg 本示例利用Akaike信息判据(AIC)、Bayes信息判据(BIC)和交叉验证,来筛选Lasso回归的正则化项参数alpha的最优值。 通过LassoLarsIC得到的结果,是基于AIC/BIC判据的。 这种基于信息判据(AIC/BIC)的模型选择非常快,但它依赖于对自由度的正确估计。该方式的假设模型必需是正确, 而且是对大样本(渐近结果)进行推导,即,数据实际上是由该模型生成的。当问题的背景条件很差时(特征数大于样本数),该模型选择方式会崩溃。 对于交叉验证,我们使用20-fold的2种算法来计算Lasso路径:LassoCV类实现的坐标下降和LassoLarsCV类实现的最小角度回归(Lars)。这两种算法给出的结果大致相同,但它们在执行速度和数值误差来源方面有所不同。 Lars仅为路径中的每个拐点计算路径解决方案。因此,当只有很少的弯折时,也就是很少的特征或样本时,它是非常有效的。此外,它能够计算完整的路径,而不需要设置任何元参数...
2021-03-20
20
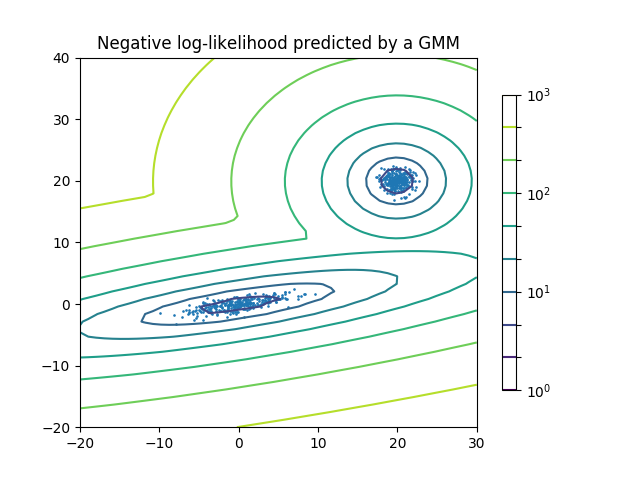
2.1. 高斯混合模型校验者: @why2lyj @Shao Y. @Loopy @barrycg翻译者: @glassy sklearn.mixture 是一个应用高斯混合模型进行非监督学习的包(支持 diagonal,spherical,tied,full 四种协方差矩阵), (注:diagonal 指每个分量有各自独立的对角协方差矩阵, spherical 指每个分量有各自独立的方差(再注:spherical是一种特殊的 diagonal, 对角的元素相等), tied 指所有分量共享一个标准协方差矩阵, full 指每个分量有各自独立的标准协方差矩阵),它可以对数据进行抽样,并且根据数据来估计模型。同时该包也支持由用户来决定模型内混合的分量数量。 (译注:在高斯混合模型中,我们将每一个高斯分布称为一个分量,即 component) 二分量高斯混合模型: 数据点,以及模型的等概率线。 高斯混合模型是一个假设所有的数据点都是生成于有限个带有未知参数的高斯分布所混合的概率模型。 我们可以将这种混合模型看作...

2021-12-24
cp
cp将源文件或目录复制到目标文件或目录中 补充说明cp命令 用来将一个或多个源文件或者目录复制到指定的目的文件或目录。它可以将单个源文件复制成一个指定文件名的具体的文件或一个已经存在的目录下。cp命令还支持同时复制多个文件,当一次复制多个文件时,目标文件参数必须是一个已经存在的目录,否则将出现错误。 语法1cp(选项)(参数) 选项123456789101112-a:此参数的效果和同时指定"-dpR"参数相同;-d:当复制符号连接时,把目标文件或目录也建立为符号连接,并指向与源文件或目录连接的原始文件或目录;-f:强行复制文件或目录,不论目标文件或目录是否已存在;-i:覆盖既有文件之前先询问用户;-l:对源文件建立硬连接,而非复制文件;-p:保留源文件或目录的属性;-R/r:递归处理,将指定目录下的所有文件与子目录一并处理;-s:对源文件建立符号连接,而非复制文件;-u:使用这项参数后只会在源文件的更改时间较目标文件更新时或是名称相互对应的目标文件并不存在时,才复制文件;-S:在备份文件时,用指定的后缀“SUFFIX”代替文件的默认后缀;-b:覆盖已存在的文...

2024-04-10
34 JVM参数调优
引言Jvm(Java虚拟机)是Java语言的基石,对于Java应用的性能至关重要。而Jvm启动参数的优化是提高Java应用性能的一个重要手段。本文将介绍Jvm启动参数的优化和一些示例,帮助开发者更好地理解和优化Jvm的启动参数。java启动参数共分为三类;其一是标准参数(-),所有的JVM实现都必须实现这些参数的功能,而且向后兼容;其二是非标准参数(-X),默认jvm实现这些参数的功能,但是并不保证所有jvm实现都满足,且不保证向后兼容;其三是非Stable参数(-XX),此类参数各个jvm实现会有所不同,将来可能会随时取消,需要慎重使用; 优化方案Jvm性能优化Jvm性能优化是应用开发过程中关注的一个重要方面。通过优化Jvm启动参数,可以显著提升Java应用的性能。以下是一些常见的Jvm性能优化参数: 1234567-Xms: 指定Jvm的初始堆大小。-Xmx: 指定Jvm的最大堆大小。-Xmn: 指定Jvm的年轻代堆大小。-XX:MaxPermSize: 指定Jvm的永久代(或元空间)大小。-XX:SurvivorRatio: 指定Jvm的年轻代中Eden区和Survivor...
2020-10-13
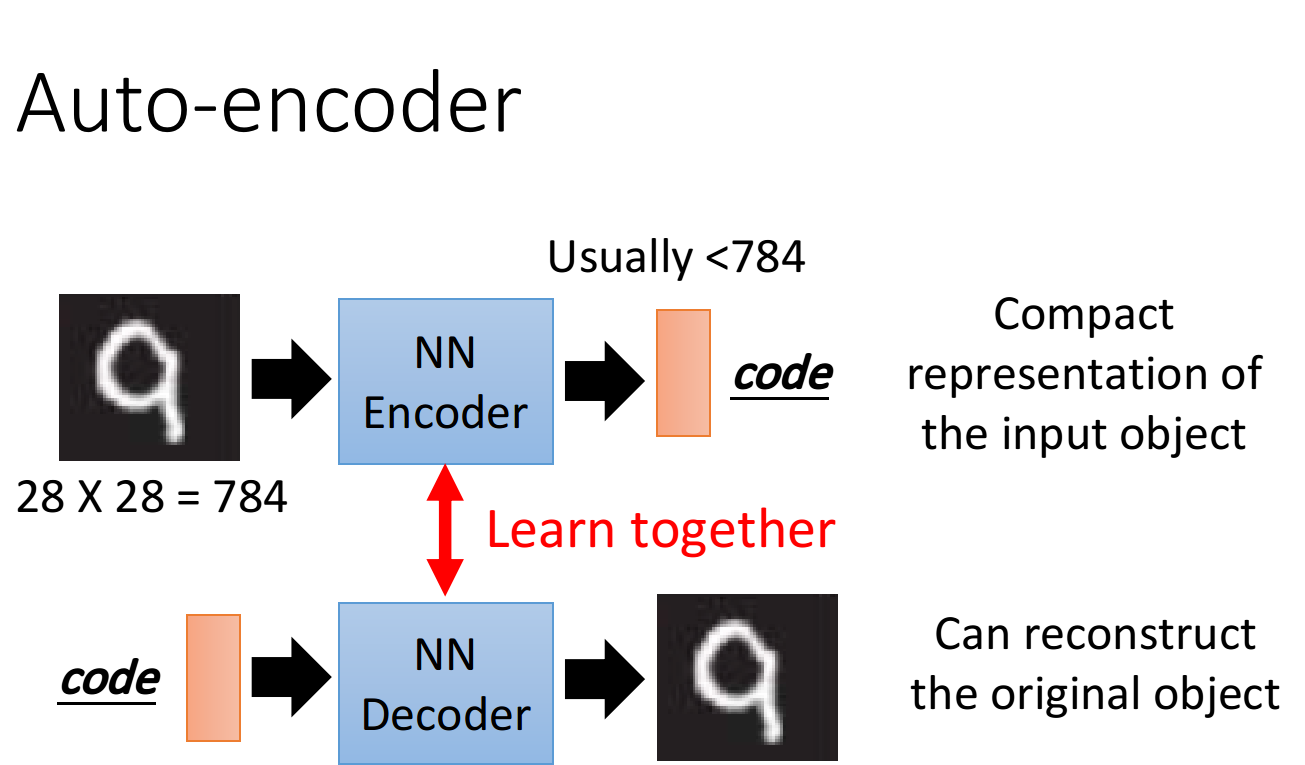
22_Unsupervised Learning Deep Auto-encoder
Unsupervised Learning: Deep Auto-encoder 文本介绍了自编码器的基本思想,与PCA的联系,从单层编码到多层的变化,在文字搜索和图像搜索上的应用,预训练DNN的基本过程,利用CNN实现自编码器的过程,加噪声的自编码器,利用解码器生成图像等内容 IntroductionAuto-encoder本质上就是一个自我压缩和解压的过程,我们想要获取压缩后的code,它代表了对原始数据的某种紧凑精简的有效表达,即降维结果,这个过程中我们需要: Encoder(编码器),它可以把原先的图像压缩成更低维度的向量 Decoder(解码器),它可以把压缩后的向量还原成图像 注意到,Encoder和Decoder都是Unsupervised Learning,由于code是未知的,对Encoder来说,我们手中的数据只能提供图像作为NN的input,却不能提供code作为output;对Decoder来说,我们只能提供图像作为NN的output,却不能提供code作为input 因此Encoder和Decoder单独拿出一个都无法进行训练,我们需要把它们连...

2020-10-13
24_Transfer Learning
Transfer Learning 迁移学习,主要介绍共享layer的方法以及属性降维对比的方法 Introduction迁移学习,transfer learning,旨在利用一些不直接相关的数据对完成目标任务做出贡献 not directly related以猫狗识别为例,解释“不直接相关”的含义: input domain是类似的,但task是无关的 比如输入都是动物的图像,但这些data是属于另一组有关大象和老虎识别的task input domain是不同的,但task是一样的 比如task同样是做猫狗识别,但输入的是卡通类型的图像 compare with real life事实上,我们在日常生活中经常会使用迁移学习,比如我们会把漫画家的生活自动迁移类比到研究生的生活 overview迁移学习是很多方法的集合,这里介绍一些概念: Target Data:和task直接相关的data Source Data:和task没有直接关系的data 按照labeled data和unlabeled data又可以划分为四种: Case 1这里ta...




