
6 图分类任务
图分类任务
- 本次应用图神经网络存在两个主要的难点
- 构建图,函数调用图是节点名称和类型不一致的。如何构建一个合理的图很关键。需要对多余的节点进行拆分和组合。去掉冗余的边和路径。
- readout,如何定义经过卷积处理的图网络的读出函数。让他能够体现整个图网络的信息,节点是不是得按照一定的顺序读取才行。
总结图网络的分类任务。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2021-03-08
TensorFlow-Summary&Tensorboard
tensorflow 数据可视化 tf.summary 在TensorFlow中,最常用的可视化方法有三种途径,分别为TensorFlow与OpenCv的混合编程、利用Matpltlib进行可视化、利用TensorFlow自带的可视化工具TensorBoard进行可视化。 原理介绍tf.summary中相关的方法会输出一个含tensor的Summary protocol buffer,这是一种能够被tensorboard模块解析的结构化数据格式。 protocol buffer(protobuf)是谷歌专用的数据序列化工具。速度更快,但格式要求更严格,应用范围可能更小。 用法详解1. tf.summary.scalar用来显示标量信息: 123tf.summary.scalar(tags, values, collections=None, name=None)例如:tf.summary.scalar('mean', mean)一般在画loss,accuary时会用到这个函数。 参数说明: name:生成节点的名字,也会作为TensorBoard中的...

2022-04-18
01 简介
JavaScript 介绍什么是 JavaScriptJavaScript 是一种由 Netscape 的 LiveScript 发展而来的原型化继承的基于对象的动态类型的区分大小写的客户端脚本语言,主要目的是为了解决服务器端语言,比如 Perl,遗留的速度问题,为客户提供更流畅的浏览效果。 当时服务端需要对数据进行验证,由于网络速度相当缓慢,只有 28.8kbps,验证步骤浪费的时间太多。于是 Netscape 的浏览器 Navigator 加入了 JavaScript,提供了数据验证的基本功能。 JavaScript,一种直译式脚本语言,是一种动态类型、弱类型、基于原型的语言,内置支持类型。它的解释器被称为 JavaScript 引擎,为浏览器的一部分,广泛用于客户端的脚本语言,最早是在 HTML 网页上使用,用来给HTML网页增加动态功能。然而现在 JavaScript 也可被用于网络服务器,如 Node.js。 JavaScript发展历史 在 1995 年由 Netscape (网景)公司推出 LiveScript。在此之前,没有所谓的前端技术。所有的处理都需要由服务器...

2019-10-15
5.2 链路层-多路访问
多路访问控制 参考文献 计算机网络——“自顶向下方法之链路层 计算机网络-链路层 1 概述点对点链路由链路一端的单个发送方和链路另一端的单个接收方组成。使用的协议包括:点对点协议(PPP)、高级数据链路控制(HDLC)。 广播链路多个发送和接受节点都连接到相同的、单一的、共享的广播信道上。多路访问协议用于规范节点在共享的广播信道上的传输行为。 多路访问控制(multiple access control protocol,MAC)协议可以分为三类——信道划分协议,随机接入协议和轮流协议。 TDM和FDM都是信道划分协议,而CDMA则是码分多址,如果配置恰当,可以同时接收节点而不被干扰。 随机接入协议在每一次碰撞后等待随机时间再发。时隙ALOHA是一个很简单的随机接入协议,而AHOHA效率是时隙ALOHA的一半。载波侦听多路访问(CSMA)会在开始之前监测是否有人说话,而如果其他人同时开始说话,则停下。 轮流协议轮效率低下,若调配节点出问题则崩盘。轮流协议包括令牌协议。 2 MAC-信道划分协议TDM时分多路复用(TDM),将时间划分为时间帧,并进一步划分每个时间帧...
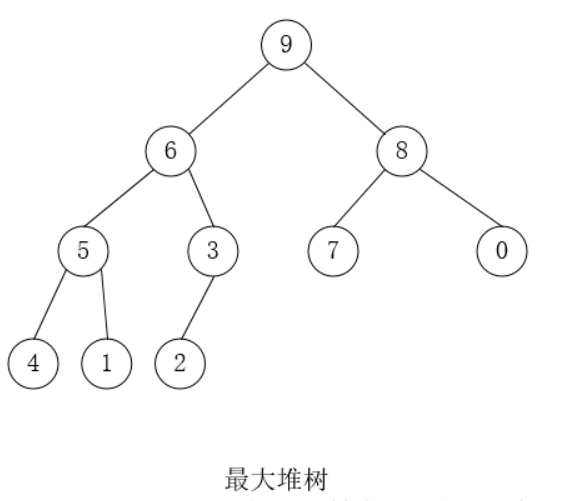
2021-03-13
6.8 堆树
堆 二叉搜索树、多路搜索树都是左小右大。堆树是上下大小不一样。 二叉搜索树是从根节点向叶子节点构造。进行插入。堆树是从叶子节点,向根节点进行构造。 参考文献 堆,但是有很严重的错误 1 简介 堆是一颗完全二叉树; 堆中的某个结点的值总是大于等于(最大堆)或小于等于(最小堆)其孩子结点的值。 堆中每个结点的子树都是堆树。 因为堆的第三条性质,堆的每一个子树,都是一个堆树。如果从叶节点开始进行一次向上调整。虽然能够保证最大值上浮到根节点。但是却无法保证它是一个堆树。因为进行一次向上调整。根节点的子树也许不是堆树。 使用数组表示的堆树 应用 堆结构的一个常见应用是建立优先队列(Priority Queue)。 普通树占用的内存空间比它们存储的数据要多。你必须为节点对象以及左/右子节点指针分配内存。堆仅仅使用一个数组来存储数组,且不使用指针。 2 操作基本操作 上浮 下沉 取顶 创建:把一个乱序的数组变成堆结构的数组,时间复杂度为 $O(n)$ 插入:把一个数值放进已经是堆结构的数组中,并保持堆结构,时间复杂度为 $O(log N)$ 删除:从最大...
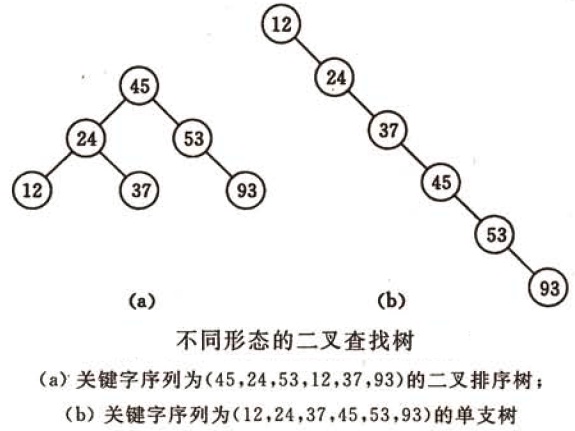
2020-01-04
3.1 查找算法
查找算法 阅读目录 顺序查找 二分查找 插值查找 斐波那契查找 树表查找 分块查找 哈希查找 0 概述 查找是在大量的信息中寻找一个特定的信息元素,在计算机应用中,查找是常用的基本运算,例如编译程序中符号表的查找。 本文简单概括性的介绍了常见的七种查找算法,说是七种,其实二分查找、插值查找以及斐波那契查找都可以归为一类——插值查找。 插值查找和斐波那契查找是在二分查找的基础上的优化查找算法。树表查找和哈希查找会在后续的博文中进行详细介绍。 查找算法,一般适用于线性结构。 搜索算法,一般适用于树和图。 查找定义 根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素(或记录)。 查找算法分类: 静态查找和动态查找; 静态或者动态都是针对查找表而言的。动态表指查找表中有删除和插入操作的表。 无序查找和有序查找。 无序查找:被查找数列有序无序均可; 有序查找:被查找数列必须为有序数列。 平均查找长度(Average Search Length,ASL) 需和指定key进行比较的关键字的个数的期望值,称为查找算法在查找成功时的平均查找长度。 对于...

2020-09-27
9.树回归
第9章 树回归 树回归 概述我们本章介绍 CART(Classification And Regression Trees, 分类回归树) 的树构建算法。该算法既可以用于分类还可以用于回归。 树回归 场景我们在第 8 章中介绍了线性回归的一些强大的方法,但这些方法创建的模型需要拟合所有的样本点(局部加权线性回归除外)。当数据拥有众多特征并且特征之间关系十分复杂时,构建全局模型的想法就显得太难了,也略显笨拙。而且,实际生活中很多问题都是非线性的,不可能使用全局线性模型来拟合任何数据。 一种可行的方法是将数据集切分成很多份易建模的数据,然后利用我们的线性回归技术来建模。如果首次切分后仍然难以拟合线性模型就继续切分。在这种切分方式下,树回归和回归法就相当有用。 除了我们在 第3章 中介绍的 决策树算法,我们介绍一个新的叫做 CART(Classification And Regression Trees, 分类回归树) 的树构建算法。该算法既可以用于分类还可以用于回归。 1、树回归 原理1.1、树回归 原理概述为成功构建以分段常数为叶节点的树,需要度量出数据的一致性。第3章使用树进...




