
07 正则表达式
Java 正则表达式
0 概述
简介
正则表达式(regex)是一个字符串,由字面值字符和特殊符号组成,是用来描述匹配一个字符串集合的模式,可以用来匹配、查找字符串。
正则表达式的两个主要作用:
- 查找:在字符串中查找符合固定模式的子串
- 匹配:整个字符串是否符合某个格式
在匹配和查找的基础上,实现替换、分割等操作。
基本实例
1 | import java.util.regex.Matcher; |
1 正则表达式语法
- 在其他语言中,
\\表示:我想要在正则表达式中插入一个普通的(字面上的)反斜杠,请不要给它任何特殊的意义。 - 在 Java 中,
\\表示:我要插入一个正则表达式的反斜线,所以其后的字符具有特殊的意义。 - 不要在重复词符中使用空白。如B{3,6} ,不能写成 B{3, 6}。空格也是有含义的。
- 可以使用括号来将模式分组。(ab){3}匹配ababab , 而ab{3} 匹配 abbb。
| 字符 | 匹配 | 示例 |
|---|---|---|
| . | 任意单个字符,除换行符外 | jav.匹配java |
| [ ] | [ ] 中的任意一个字符 | java匹配j[abc]va |
| - | [ ] 内表示字符范围 | java匹配[a-z]av[a-g] |
| ^ | 在[ ]内的开头,匹配除[ ]内的字符之外的任意一个字符 | java匹配j[^b-f]va |
| 或 | ||
| \ | 将下一字符标记为特殊字符、文本、反向引用或八进制转义符 | (匹配( |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与”\n”或”\r”之前的位置匹配。 | ;$匹配位于一行及外围的;号 |
| * | 零次或多次匹配前面的字符 | zo*匹配zoo或z |
| + | 一次或多次匹配前面的字符 | zo+匹配zo或zoo |
| ? | 零次或一次匹配前面的字符 | zo?匹配z或zo |
| p{n} | n 是非负整数。正好匹配 n 次 | o{2}匹配food中的两个o |
| p{n,} | n 是非负整数。至少匹配 n 次 | o{2}匹配foood中的所有o |
| p{n,m} | M 和 n 是非负整数,其中 n<= m。匹配至少 n 次,至多 m 次 | o{1,3}匹配fooood中的三个o |
| \p{P} | 一个标点字符 !”#$%&’()*+,-./:;<=>?@[]^_’{ | }~ |
| \b | 匹配一个字边界 | va\b匹配java中的va,但不匹配javar中的va |
| \B | 非字边界匹配 | va\B匹配javar中的va,但不匹配java中的va |
| \d | 数字字符匹配 | 1[\d]匹配13 |
| \D | 非数字字符匹配 | [\D]java匹配Jjava |
| \w | 单词字符 | java匹配[\w]ava |
| \W | 非单词字符 | $java匹配[\W]java |
| \s | 空白字符 | Java 2匹配Java\s2 |
| \S | 非空白字符 | java匹配 j[\S]va |
| \f | 匹配换页符 | 等效于\x0c和\cL |
| \n | 匹配换行符 | 等效于\x0a和\cJ |
分组说明
1 | 正则表达式-字符类 |
2 基本概念
Patter类和Matcher类
Pattern 类:
pattern 对象是一个正则表达式的编译表示。Pattern 类没有公共构造方法。要创建一个 Pattern 对象,你必须首先调用其公共静态编译方法,它返回一个 Pattern 对象。该方法接受一个正则表达式作为它的第一个参数。
Matcher 类:
Matcher 对象是对输入字符串进行解释和匹配操作的引擎。与Pattern 类一样,Matcher 也没有公共构造方法。你需要调用 Pattern 对象的 matcher 方法来获得一个 Matcher 对象。
匹配模式
1、Pattern.MULTILINE模式的用法
正则表达式中出现了^或者$, 默认只会匹配第一行. 设置了Pattern.MULTILINE模式,会匹配所有行。例如,
1 | Pattern p1 = Pattern.compile("^.*b.*$"); |
2、Pattern.DOTALL模式的用法
默认情况下, 正则表达式中点(.)不会匹配换行符, 设置了Pattern.DOTALL模式, 才会匹配所有字符包括换行符。例如,
1 | Pattern p1 = Pattern.compile("a.*b"); |
3、同时指定Pattern.MULTILINE和Pattern.DOTALL模式
实际情况中要是比较复杂的情况,可能Pattern.MULTILINE模式和Pattern.DOTAL模式需要同时指定来匹配多行,下面看一下,
1 | Pattern p1 = Pattern.compile("^a.*b$"); |
捕获组
- 捕获组是把多个字符当成一个单独单元进行处理的方法,它通过对括号内的字符分组来创建。
1 | 捕获组通过从左到右计算其括号来编号。 |
- 捕获组可以通过调用matcher对象的groupCount方法来查看表达式有多少个分组。(groupCount方法返回一个int值,来表示matcher对象当前有多少个捕获组)
- 还有一个特殊的组零(group(0)),它代表整个表达式。(该组不包括在groupCount的返回值中)
- 以 (?) 开头的组是纯的非捕获 组,它不捕获文本,也不针对组合计进行计数。
3 Matcher用法
索引方法
- public int start()
返回以前匹配的初始索引。 - public int start(int group)
返回在以前的匹配操作期间,由给定组所捕获的子序列的初始索引 - public int end()
返回最后匹配字符之后的偏移量。 - public int end(int group)
返回在以前的匹配操作期间,由给定组所捕获子序列的最后字符之后的偏移量。
1 | import java.util.regex.Matcher; |
匹配和查找方法
- public boolean lookingAt()
尝试将从区域开头开始的输入序列与该模式匹配。开头匹配。 - public boolean find()
尝试查找与该模式匹配的输入序列的下一个子序列。 - public boolean find(int start)
重置此匹配器,然后尝试查找匹配该模式、从指定索引开始的输入序列的下一个子序列。 - public boolean matches()
尝试将整个区域与模式匹配。全局匹配。
1 | import java.util.regex.Matcher; |
替换方法
- public Matcher appendReplacement(StringBuffer sb, String replacement)
实现非终端添加和替换步骤。 - public StringBuffer appendTail(StringBuffer sb)
实现终端添加和替换步骤。 - public String replaceAll(String replacement)
替换模式与给定替换字符串相匹配的输入序列的每个子序列。 - public String replaceFirst(String replacement)
替换模式与给定替换字符串匹配的输入序列的第一个子序列。 - public static String quoteReplacement(String s)
返回指定字符串的字面替换字符串。这个方法返回一个字符串,就像传递给Matcher类的appendReplacement 方法一个字面字符串一样工作。
1 | import java.util.regex.Matcher; |
1 | import java.util.regex.Matcher; |
4 String自带的正则表达式功能
见String
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2021-03-08
5. 动态交互建模
动态交互建模目录1概念1.1 动态模型概念 描述了被建模系统的控制行为以及构件的交互顺序。对象内部的动态模型——有限状态机模型。对象之间的动态模型——交互图或通信图。 基于用例建模和问题域的静态建模。 2对象交互建模2.1 通信图 描述了一组对象如何通过对象间的消息传递来实现交互。 每一个用例对应一个通信图。通信图中的对象都是用例包含的对象,对象之间的消息发送序列由编号来描述。通信图中的消息序列与用例描述中参与者与系统的交互序列相对应。 2.2 序列图 按照时间顺序展现了对象之间的交互。可以描述循环和迭代的过程。 不需要编号,从上到下,表示了消息的先后顺序。 序列图的优缺点 优: 清楚地显示对象间的消息传递序列 优: 对设计对象操作的执行逻辑有益 缺: 不易表述对象的关联 缺: 涉及多个对象的复杂序列图及使用了循环和判定逻辑的序列图不易阅读 通信图的优缺点 优: 清楚地展现了对象的布局及其关联关系 优: 易于平滑过渡到软件架构的设计 缺: 表示消息序列直观性差(用编号) 缺: 对设计对象操作的执行逻辑帮助有限 2.3 消息序列 交互图上的交互序列描述了用例中的一个场...

2021-04-06
MATLAB8
MATLAB二维底层绘图的修饰> 对象和句柄 似乎MATLAB也能满足面向对象编程的一些条件诶!MATLAB也能实现GUI图形用户界面编程,同强大的C++、Java有一拼 对象和句柄的概念 MATLAB吧构成图形的各个基本要素成为图形对象,产生每一个图形对象时,MATLAB会自动分配一个唯一的值,用于表示这个对象,成为句柄(好像子对象和指向对象的指针) 对象间的基本关系 计算机屏幕->图形窗口->(用户菜单,用户控件,坐标轴) 坐标轴->(曲线,曲面,文字,图像,光源,区域,方框) > 基本地城绘图函数 line对象 h = line([-pi:0.01:pi],sin([-pi:0.01:pi])); 其中h成为line曲线对象的句柄。 line对象的修饰 color属性 LineWidth属性 LineStyle属性 Marker属性 MarkerSize属性 plot函数能够产生line对象,然后继续对返回的句柄进行操作、或者直接在绘制过程进行修饰。 h1 = line('XData',[-pi:0....
2021-03-20
25
# 2.6. 协方差估计 校验者: [@李昊伟](https://github.com/apachecn/scikit-learn-doc-zh) [@小瑶](https://github.com/apachecn/scikit-learn-doc-zh) [@Loopy](https://github.com/loopyme) [@barrycg](https://github.com/barrycg) 翻译者: [@柠檬](https://github.com/apachecn/scikit-learn-doc-zh) 许多统计问题需要估计一个总体的协方差矩阵,这可以看作是对数据集散点图形状的估计。大多数情况下,必须对某个样本进行这样的估计,当它的属性(如尺寸,结构,均匀性)对估计质量有重大影响时。*sklearn.covariance* 包的目的是提供一个能在各种设置下准确估计总体协方差矩阵的工具。 我们假设观察是独立的,相同分布的 (i.i.d.)。 ## 2.6.1. 经验协方差 ...
2021-03-09
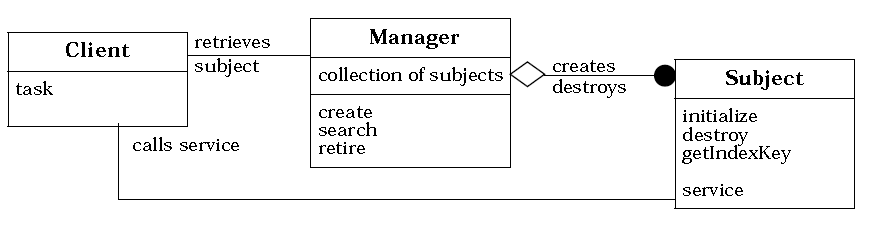
5.3 Manager(管理器)
索引 意图 结构 参与者 适用性 效果 实现 实现方式(一):Manager 模式的示例实现。 意图 将对一个类的所有对象的管理封装到一个单独的管理器类中。 这使得管理职责的变化独立于类本身,并且管理器还可以为不同的类进行重用。 Encapsulates management of a class’s objects into a separate manager object. This allows variation of management functionality independent of the class andthe manager’s reuse for different classes. 结构 参与者 Subject 领域对象。 提供 Client 需要的领域服务。 Manager Manager 类是唯一负责创建和销毁 Subject 对象的类。它负责跟踪和管理 Subject对象。 典型的管理职责包括根据指定的 Key 搜索 Subject 对象。 因为 Subject 对 Manager 无引用,所以 Man...

2022-12-19
08 Comparable&Comparator
Comparable概述Java Comparable接口,用于根据对象的natural order对array或对象list进行natural order 。 元素的自然排序是通过在对象中实现其compareTo()方法来实现的。 1234public interface Comparable<T> { public int compareTo(T o);} 使用123456789101112131415import java.time.LocalDate; public class Employee implements Comparable<Employee> { private Long id; private String name; private LocalDate dob; @Override public int compareTo(Employee o) { return this.getId().compareTo( o.g...

2020-09-26
path_editor
路径编辑器跨GUI共享事件。 此示例演示了使用Matplotlib事件处理与画布上的对象进行交互和修改对象的跨GUI应用程序。 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149import numpy as npimport matplotlib.path as mpathimport matplotlib.patches as mpatchesimport ...




