05 Set
0 Set 接口
Set接口
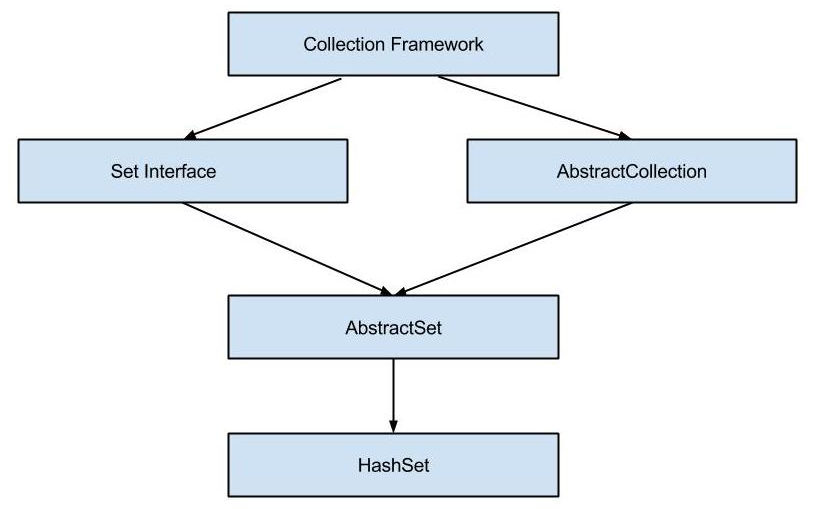
Set接口继承了Collection接口,是一个不包括重复元素的集合,更确切地说,Set 中任意两个元素不会出现 o1.equals(o2),而且 Set 至多只能存储一个 NULL 值元素,Set 集合的组成部分可以用下面这张图概括:
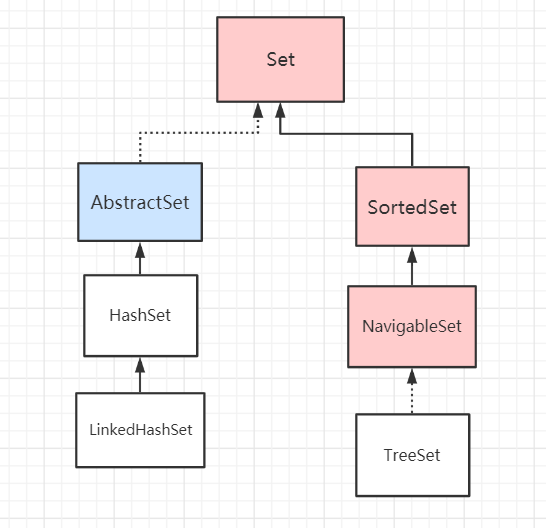
在 Set 集合体系中,我们需要着重关注两点:
存入可变元素时,必须非常小心,因为任意时候元素状态的改变都有可能使得 Set 内部出现两个相等的元素,即
o1.equals(o2) = true,所以一般不要更改存入 Set 中的元素,否则将会破坏了equals()的作用!Set 的最大作用就是判重,在项目中最大的作用也是判重!
接下来我们去看它的实现类和子类: AbstractSet 和 SortedSet
AbstractSet 抽象类
AbstractSet 是一个实现 Set 的一个抽象类,定义在这里可以将所有具体 Set 集合的相同行为在这里实现,避免子类包含大量的重复代码
所有的 Set 也应该要有相同的 hashCode() 和 equals() 方法,所以使用抽象类把该方法重写后,子类无需关心这两个方法。
1 | public abstract class AbstractSet<E> implements Set<E> { |
SortedSet 接口
SortedSet 是一个接口,它在 Set 的基础上扩展了排序的行为,所以所有实现它的子类都会拥有排序功能。
1 | public interface SortedSet<E> extends Set<E> { |
1 HashSet
底层实现
HashSet 底层借助 HashMap 实现,我们可以观察它的多个构造方法,本质上都是 new 一个 HashMap
1 | public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, Serializable { |
我们可以观察 add() 方法和remove()方法是如何将 HashSet 的操作嫁接到 HashMap 的。
1 | private static final Object PRESENT = new Object(); |
我们看到 PRESENT 就是一个静态常量:使用 PRESENT 作为 HashMap 的 value 值,使用HashSet的开发者只需关注于需要插入的 key,屏蔽了 HashMap 的 value
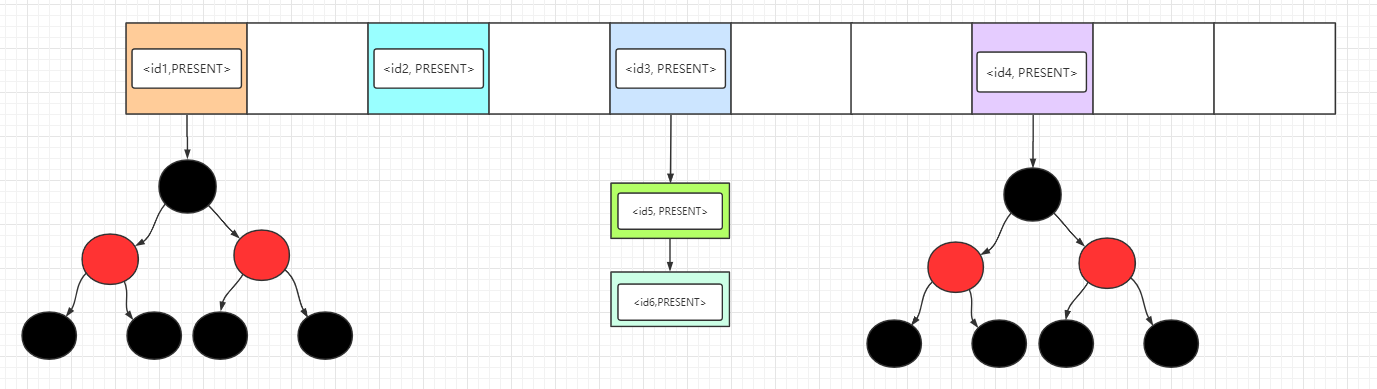
上图可以观察到每个Entry的value都是 PRESENT 空对象,我们就不用再理会它了。
HashSet 在 HashMap 基础上实现,所以很多地方可以联系到 HashMap:
- 底层数据结构:HashSet 也是采用
数组 + 链表 + 红黑树实现 - 线程安全性:由于采用 HashMap 实现,而 HashMap 本身线程不安全,在HashSet 中没有添加额外的同步策略,所以 HashSet 也线程不安全
- 存入 HashSet 的对象的状态最好不要发生变化,因为有可能改变状态后,在集合内部出现两个元素
o1.equals(o2),破坏了equals()的语义。
继承结构
- 实现了Set接口。
- HashSet中不允许重复的值。
- HashSet中允许一个NULL元素。
- 无序集合,并且不保证集合的迭代顺序。
- 为基本操作(添加,删除,包含和调整大小)提供恒定的时间性能。
- HashSet不同步。 如果多个线程同时访问哈希集,并且至少有一个线程修改了哈希集,则必须在外部对其进行同步。使用Collections.synchronizedSet(new HashSet())方法获取同步的哈希集。
基本使用
- 默认初始容量为16 。 我们可以通过在构造函数HashSet(int initialCapacity)传递默认容量来覆盖此默认容量。
1 | public boolean add(E e) :如果指定的元素不存在,则将其添加到Set中。 此方法在内部使用equals()方法检查重复项。 如果元素重复,则元素被拒绝,并且不替换值。 |
2 LinkedHashSet
底层原理
LinkedHashSet 的代码少的可怜,不信我给你我粘出来
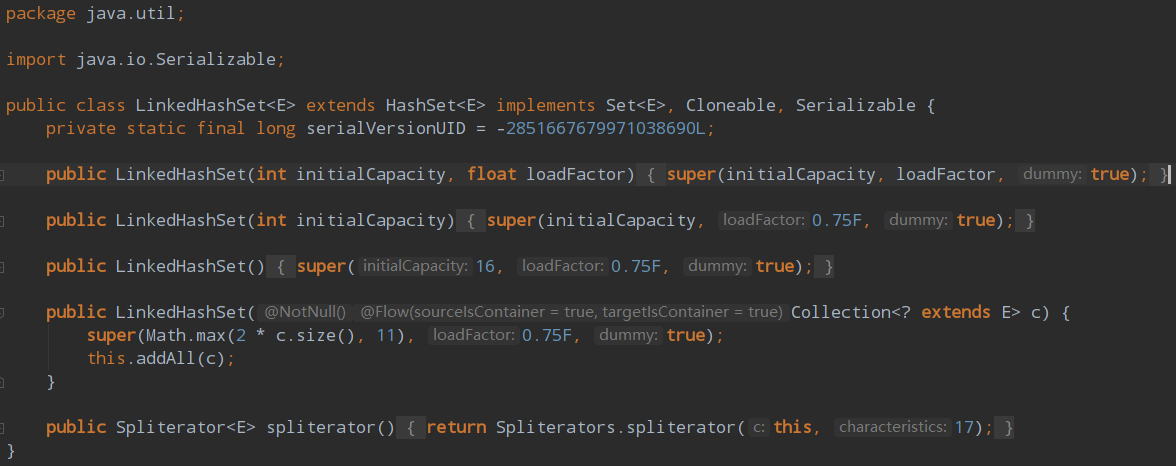
少归少,还是不能闹,LinkedHashSet继承了HashSet,我们跟随到父类 HashSet 的构造方法看看
1 | HashSet(int initialCapacity, float loadFactor, boolean dummy) { |
发现父类中 map 的实现采用LinkedHashMap,这里注意不是HashMap,而 LinkedHashMap 底层又采用 HashMap + 双向链表 实现的,所以本质上 LinkedHashSet 还是使用 HashMap 实现的。
LinkedHashSet -> LinkedHashMap -> HashMap + 双向链表
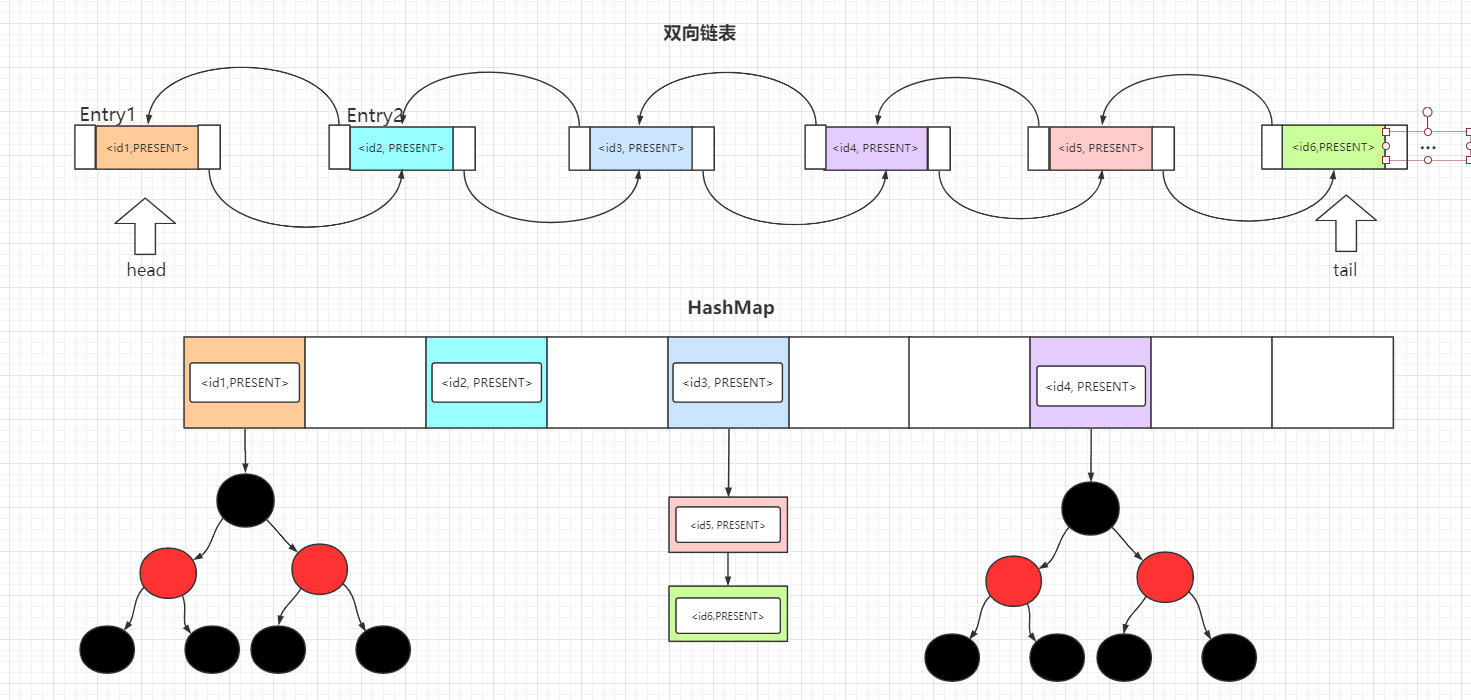
而 LinkedHashMap 是采用 HashMap和双向链表实现的,这条双向链表中保存了元素的插入顺序。所以 LinkedHashSet 可以按照元素的插入顺序遍历元素,如果你熟悉LinkedHashMap,那 LinkedHashSet 也就更不在话下了。
关于 LinkedHashSet 需要注意几个地方:
- 它继承了
HashSet,而 HashSet 默认是采用 HashMap 存储数据的,但是 LinkedHashSet 调用父类构造方法初始化 map 时是 LinkedHashMap 而不是 HashMap,这个要额外注意一下 - 由于 LinkedHashMap 不是线程安全的,且在 LinkedHashSet 中没有添加额外的同步策略,所以 LinkedHashSet 集合也不是线程安全的
继承关系
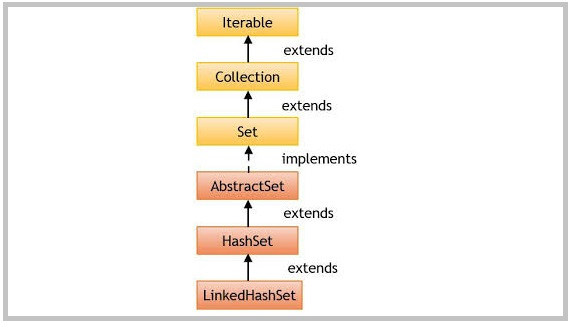
- 它扩展了HashSet类,后者扩展了AbstractSet类。
- 它实现Set接口。
- LinkedHashSet中不允许重复的值 。
- LinkedHashSet中允许一个NULL元素。
- 它是一个ordered collection ,它是元素插入到集合中insertion-order ( insertion-order )。
- 像HashSet一样,此类为基本操作(添加,删除,包含和调整大小)提供constant time performance 。
- LinkedHashSet not synchronized 。 如果多个线程同时访问哈希集,并且至少有一个线程修改了哈希集,则必须在外部对其进行同步。
- 使用Collections.synchronizedSet(new LinkedHashSet())方法来获取同步的LinkedHashSet。
使用方法
1 | public boolean add(E e) :如果指定的元素不存在,则将其添加到Set中。 此方法在内部使用equals()方法检查重复项。 如果元素重复,则元素被拒绝,并且不替换值。 |
3 TreeSet
底层原理
TreeSet 是基于 TreeMap 的实现,所以存储的元素是有序的,底层的数据结构是数组 + 红黑树。
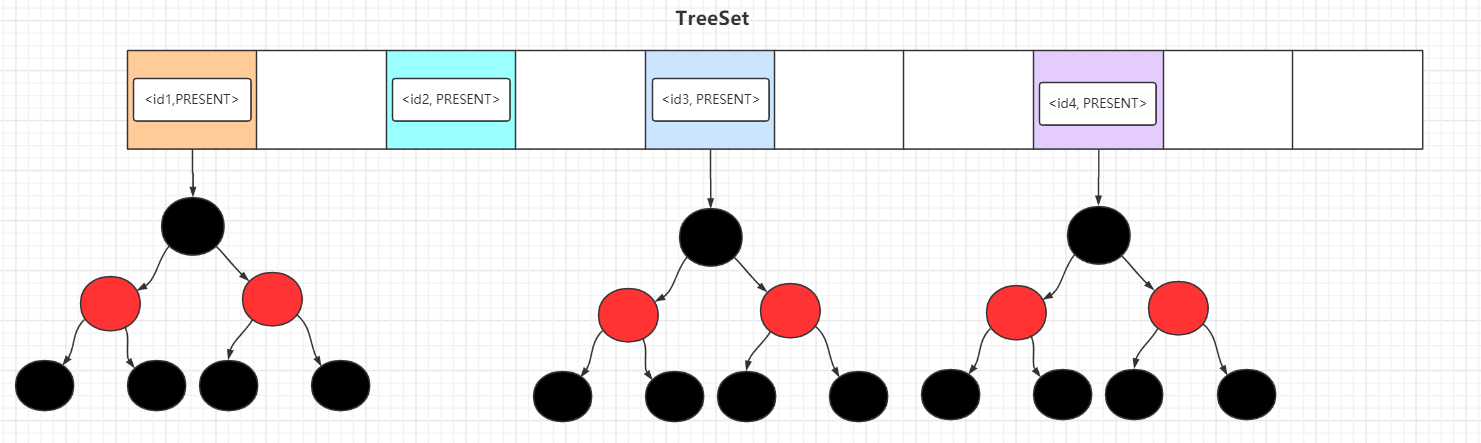
而元素的排列顺序有2种,和 TreeMap 相同:自然排序和定制排序,常用的构造方法已经在下面展示出来了,TreeSet 默认按照自然排序,如果需要定制排序,需要传入Comparator。
1 | public TreeSet() { |
TreeSet 应用场景有很多,像在游戏里的玩家战斗力排行榜
1 | public class Player implements Comparable<Integer> { |
对 TreeSet 介绍了它的主要实现方式和应用场景,有几个值得注意的点。
- TreeSet 的所有操作都会转换为对 TreeMap 的操作,TreeMap 采用红黑树实现,任意操作的平均时间复杂度为
O(logN) - TreeSet 是一个线程不安全的集合
- TreeSet 常应用于对不重复的元素定制排序,例如玩家战力排行榜
注意:TreeSet判断元素是否重复的方法是判断compareTo()方法是否返回0,而不是调用 hashcode() 和 equals() 方法,如果返回 0 则认为集合内已经存在相同的元素,不会再加入到集合当中。
继承关系
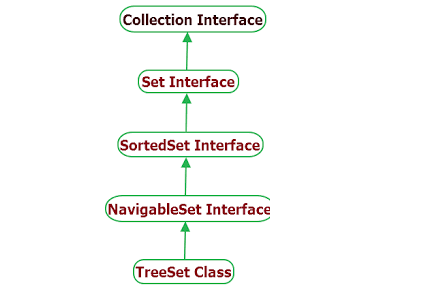
- 它扩展了AbstractSet类,该类扩展了AbstractCollection类。
- 它实现了NavigableSet接口,该接口扩展了SortedSet接口。
- TreeSet中不允许重复的值。
- 在TreeSet中不允许NULL。
- 它是一个ordered collection ,按排序顺序存储元素。
- 与HashSet一样,此类为基本操作(添加,删除,包含和调整大小)提供恒定的时间性能。
- TreeSet不允许插入异构对象,因为它必须比较对象以确定排序顺序。
- TreeSet不synchronized 。 如果多个线程同时访问哈希集,并且至少有一个线程修改了哈希集,则必须在外部对其进行同步。
- 使用Collections.synchronizedSortedSet(new TreeSet())方法获取同步的TreeSet。
使用方法
1 | boolean add(E e) :将指定的元素添加到Set中(如果尚不存在)。 |