
scrapy框架学习——Selector选择器
爬取网站最常见的任务是从HTML源代码中提取数据。常用的库有BeautifulSoup。lxml库,Xpath。
Selector 中Xpath和CSS的使用
标签是节点 ,可以有层级
属性使用@来调用
内容要用text()来调用
条件要在[ ]写明白,也可以是contains[]
//表示获得所有的某一个标签
./表示下一级的方法
可以使用正则表达式最原始的过滤。
response**.xpath(‘//a[contains(@href,
“image”)]/text()’).**re(r’Name:\s*(.*)’)
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐
2022-02-23
3 训练
1 图分类示例创建数据集1234567891011121314151617181920212223242526import torchfrom torch_geometric.datasets import TUDatasetdataset = TUDataset('/home/ykl/TUDataset', name = 'MUTAG')print()print(f'Dataset: {dataset}:')print('====================')print(f'Number of graphs: {len(dataset)}')print(f'Number of features: {dataset.num_features}')print(f'Number of classes: {dataset.num_classes}')data = ...
2021-03-12
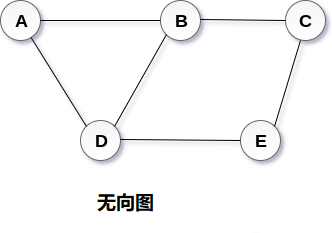
7 图
图1 简介概念 图可以定义为用于顶点和边的组合。 图可以看作是循环树,图中顶点(节点)维持它们之间的任何复杂关系,而不是简单的父子关系。 图G 可以定义为有序集G(V,E),其中V(G)表示顶点集,E(G)表示用于连接这些顶点的边集。 图G(V,E)有5个顶点(A,B,C,D,E)和6个边((A,B),(B,C),(C,E),(E,D), (D,B),(D,A))如下图所示。 术语 阶(Order) - 图 G 中点集 V 的大小称作图 G 的阶。 子图(Sub-Graph) - 当图 G’=(V’,E’)其中 V‘包含于 V,E’包含于 E,则 G’称作图 G=(V,E)的子图。每个图都是本身的子图。 生成子图(Spanning Sub-Graph) - 指满足条件 V(G’) = V(G)的 G 的子图 G’。 导出子图(Induced Subgraph) - 以图 G 的顶点集 V 的非空子集V1 为顶点集,以两端点均在 V1 中的全体边为边集的 G 的子图,称为 V1 导出的导出子图;以图 G 的边集 E 的非空子集 E1 为边集,以 E...

2020-09-27
9.树回归
第9章 树回归 树回归 概述我们本章介绍 CART(Classification And Regression Trees, 分类回归树) 的树构建算法。该算法既可以用于分类还可以用于回归。 树回归 场景我们在第 8 章中介绍了线性回归的一些强大的方法,但这些方法创建的模型需要拟合所有的样本点(局部加权线性回归除外)。当数据拥有众多特征并且特征之间关系十分复杂时,构建全局模型的想法就显得太难了,也略显笨拙。而且,实际生活中很多问题都是非线性的,不可能使用全局线性模型来拟合任何数据。 一种可行的方法是将数据集切分成很多份易建模的数据,然后利用我们的线性回归技术来建模。如果首次切分后仍然难以拟合线性模型就继续切分。在这种切分方式下,树回归和回归法就相当有用。 除了我们在 第3章 中介绍的 决策树算法,我们介绍一个新的叫做 CART(Classification And Regression Trees, 分类回归树) 的树构建算法。该算法既可以用于分类还可以用于回归。 1、树回归 原理1.1、树回归 原理概述为成功构建以分段常数为叶节点的树,需要度量出数据的一致性。第3章使用树进...

2021-03-08
TensorFlow-自定义IO
TensorFlow-自定义IO基本介绍架构 文件格式: 我们使用 Reader Op来从文件中读取一个 record (可以使任意字符串)。 记录格式: 我们使用解码器或者解析运算将一个字符串记录转换为TensorFlow可以使用的张量。 读取数据方法 本质上Dateset是一个封装好的上层接口,其本质上是调用Python中的数据读取底层接口,不择维护队列和栈。Python中的底层接口调用了C++中Core提供的核心方法。 现在需要根据一根成熟的代码编译完整的代码来阅读相关的函数调用过程。 调用栈core中的函数
2020-01-02
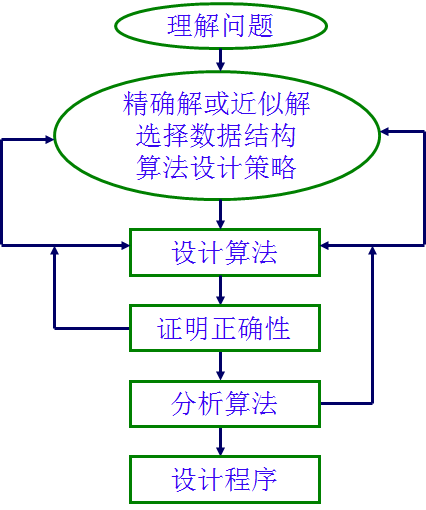
1 算法概述
算法概述 参考文献 八种算法思想 1 基本概念定义 算法是一系列解决问题的清晰指令,对于符合一定规范的输入,算法能够在有限时间内获得所要求的输出。算法是解决问题的一种方法或过程,它是由若干条指令组成的有穷序列。 算法本质上不是数学,而是逻辑。 特征 输入:有零或多个外部量作为算法的输入。 输出:算法产生至少一个量作为输出。 确定性:组成算法的每条指令清晰、无歧义。 有效性:算法中执行的任何计算步骤都是可以被分解为基本的可执行的操作步。 有限性:算法中每条指令的执行次数有限,执行每条指令的时间也有限。 算法的描述 算法的描述方式:自然语言、流程图、伪代码 算法的正确性证明方式:归纳法 算法分析:正确性分析、效率分析、复杂度分析 算法的终极目标 次序order:先做什么、后做什么。前边对后边有影响。 选择if-else:要做什么、不做什么。合并相同的类别,减少分类讨论的情况。 重复while-for:一直做什么。提取相同子结构、相同子操作,进行重复利用。可以通过递归实现重复。 整理说明 以算法结尾,代表的是某一系列或者某一类通用的算法。不依赖于具体的问题。通常可以解决很...

2021-03-26
6.9 字典树
字典树Trie 参考资料 字典树trie 数据结构算法10 1 Trie定义 Trie,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。 字典树设计的核心思想是空间换时间,所以数据结构本身比较消耗空间。但它利用了字符串的**共同前缀(Common Prefix)**作为存储依据,以此来节省存储空间,并加速搜索时间。Trie 的字符串搜索时间复杂度为 O(m),m为最长的字符串的长度,其查询性能与集合中的字符串的数量无关。其在搜索字符串时表现出的高效,使得特别适用于构建文本搜索和词频统计等应用。 2 Trie 的性质 根节点(Root)不包含字符,除根节点外的每一个节点都仅包含一个字符; 从根节点到某一节点路径上所经过的字符连接起来,即为该节点对应的字符串; 任意节点的所有子节点所包含的字符都不相同; ...




