
6.6 B+树
B+树
参考文献
1 简介
概念
像是在建立额外的索引
- 有m个子树的中间节点包含有m个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引;
- 所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (而B 树的叶子节点并没有包括全部需要查找的信息);
- 所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息);
优点
B+树的磁盘读写代价更低
- B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了;
B+树查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当;
B+树便于范围查询(最重要的原因,范围查找是数据库的常态)
- B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低;不懂可以看看这篇解读-》范围查找
2 操作
基础操作
- 创建
- 遍历和搜索
- 插入
- 删除
- 分裂
- 合并
搜索
插入
- 第1步 :将新节点作为叶节点插入。
- 第2步 :如果叶子没有所需空间,则拆分节点并将中间节点复制到下一个索引节点。
- 第3步 :如果索引节点没有所需空间,则拆分节点并将中间元素复制到下一个索引节点
实例
- 将值195插入到下图所示的5阶B+树中。

- 在190之后,将在右子树120中插入195。将其插入所需位置。

- 该节点包含大于最大的元素数量,即4,因此将其拆分并将中间节点放置到父节点。

- 现在,索引节点包含6个子节点和5个键,违反B+树属性,因此需要将其拆分,如下所示。将108提为根节点。60,78左子节点,120,190右子节点。

删除
- 第1步:从叶子中删除键和数据。
- 第2步:如果叶节点包含少于最小数量的元素,则将节点与其兄弟节点合并,并删除它们之间的键。
- 第3步:如果索引节点包含少于最小数量的元素,则将节点与兄弟节点合并,并在它们之间向下移动键。
示例
- 从下图所示的B+树中删除键为200。

- 在195之后的190的右子树中存在200,删除它。

- 使用195,190,154和129合并两个节点。

- 现在,元素120是节点中存在的违反B+树属性的单个元素。 因此,需要使用60,78,108和120来合并它。现在,B+树的高度将减1。

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐
2021-03-12
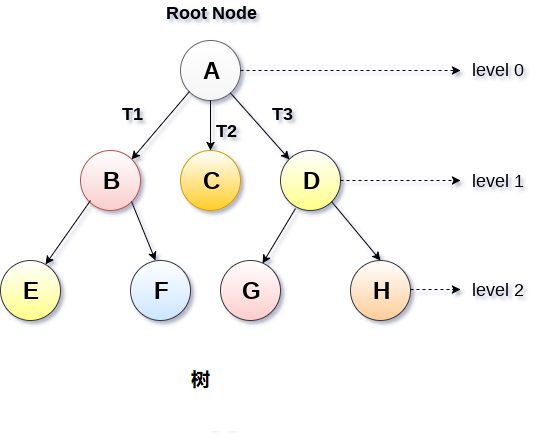
6 树
树 树 0 简介定义树是一种抽象数据类型或是实现这种抽象数据类型的数据结构,用来模拟具有树状结构性质的数据集合。它是由 n(n>0)个有限节点组成一个具有层次关系的集合。 树是一种递归数据结构,包含一个或多个数据节点的集合,其中一个节点被指定为树的根,而其余节点被称为根的子节点。 除根节点之外的节点被划分为非空集,其中每个节点将被称为子树。 树的节点要么保持它们之间的父子关系,要么它们是姐妹节点。 在通用树中,一个节点可以具有任意数量的子节点,但它只能有一个父节点。 特点 每个节点都只有有限个子节点或无子节点。 树有且仅有一个根节点。 根节点没有父节点;非根节点有且仅有一个父节点。 每个非根节点可以分为多个不相交的子树。 树里面没有环路。 术语 祖先节点: 节点的祖先是从根到该节点的路径上的任何前节点。根节点没有祖先节点。 父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 子节点:一个节点含有的子树的根节点称为该节点的子节点; 根节点: 根节点是树层次结构中的最顶层节点。 换句话说,根节点是没有任何父节点的节点. 叶子节点或终端节点:度为零的...
2020-10-13
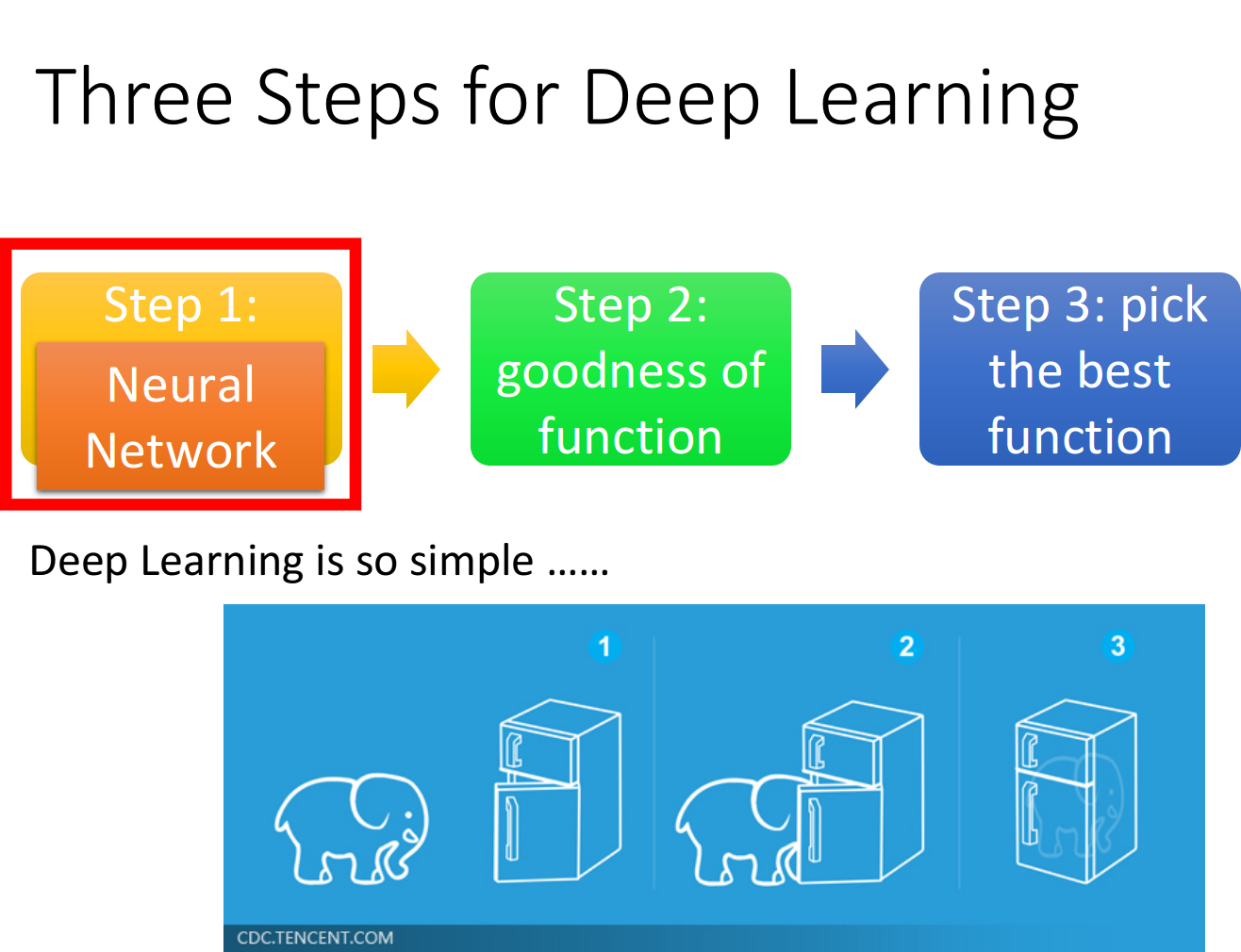
8_Deep Learning
Deep LearningUps and downs of Deep Learning 1958:Perceptron(linear model),感知机的提出 和Logistic Regression类似,只是少了sigmoid的部分 1969:Perceptron has limitation,from MIT 1980s:Multi-layer Perceptron,多层感知机 和今天的DNN很像 1986:Backpropagation,反向传播 Hinton propose的Backpropagation 存在problem:通常超过3个layer的neural network,就train不出好的结果 1989: 1 hidden layer is “good enough”,why deep? 有人提出一个理论:只要neural network有一个hidden layer,它就可以model出任何的function,所以根本没有必要叠加很多个hidden layer,所以Multi-layer Perceptron的方法又坏掉了,这段时间Multi-l...

2022-02-23
1 数据
1 图数据结构图说起来也很简单,就是两个核心点,一个是图节点(nodes/vertics),一个是边(edges/links)表示节点之间的连接关系 总体而言,图可以是不规整的(irregular),对比而言,平时我们看到的图片都是规整的(regular),可以表示成矩阵或者向量。问题在于设计数据结构如何储存图,一般有两种方案 矩阵表示又细分成两种 用邻接矩阵(adjacency matrix),度矩阵(degree matrix), 拉普拉斯矩阵(Laplacian matrix)去表示, 衍生出各种对拉普拉斯矩阵的操作,比如图傅里叶变换(graph fourier transform), 也有稀疏邻接矩阵 用关联矩阵(incidence matrix)表示,行表示节点,列表示边, 和这个相关的例如:超图(hypergraph) 这(两)种方式的缺点在于使用内存大, 矩阵维度和节点数目N挂钩。但是图的连接常常是稀疏的(sparse),也就是邻接矩阵中很多元素都是0(两个node没有连接关系),这些0元素会占据大量存储空间,使效率很低下。尤其是大型网络...
2021-03-22
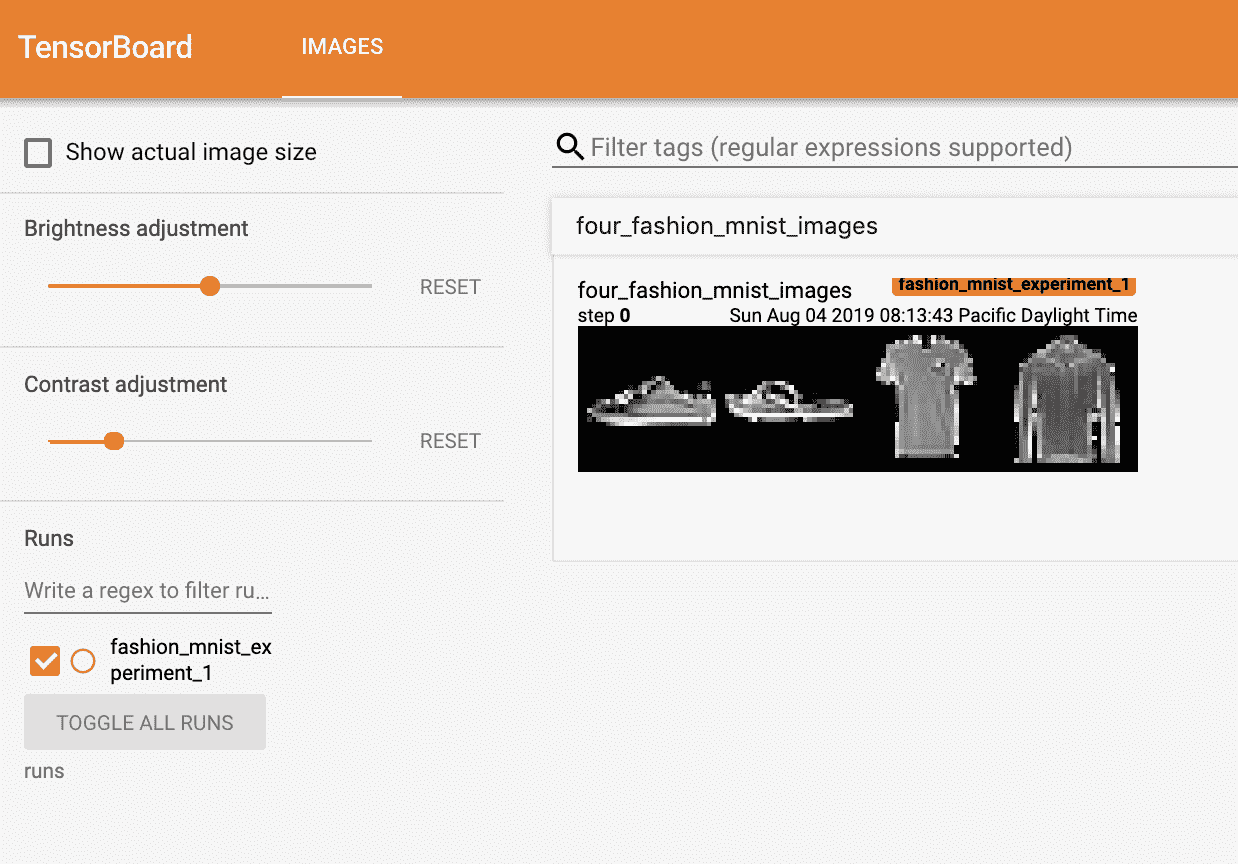
05 Pytorch 可视化
tensorboard 使用说明1 数据形式Tensorboard可以记录与展示以下数据形式: 标量Scalars 图片Images 音频Audio 计算图Graph 数据分布Distribution 直方图Histograms 嵌入向量Embeddings 2 操作流程tensorflow-tensorboardTensorboard的可视化过程 首先肯定是先建立一个graph,你想从这个graph中获取某些数据的信息 确定要在graph中的哪些节点放置summary operations以记录信息 1234使用tf.summary.scalar记录标量使用tf.summary.histogram记录数据的直方图使用tf.summary.distribution记录数据的分布图使用tf.summary.image记录图像数据 operations并不会去真的执行计算,除非你告诉他们需要去run,或者它被其他的需要run的operation所依赖。而我们上一步创建的这些summary operations其实并不被其他节点依赖,因此,我们需要特地去运行所有的summa...
2021-03-12
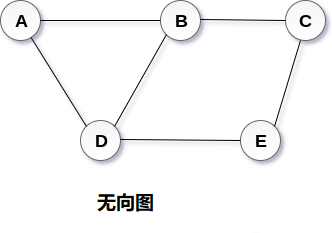
7 图
图1 简介概念 图可以定义为用于顶点和边的组合。 图可以看作是循环树,图中顶点(节点)维持它们之间的任何复杂关系,而不是简单的父子关系。 图G 可以定义为有序集G(V,E),其中V(G)表示顶点集,E(G)表示用于连接这些顶点的边集。 图G(V,E)有5个顶点(A,B,C,D,E)和6个边((A,B),(B,C),(C,E),(E,D), (D,B),(D,A))如下图所示。 术语 阶(Order) - 图 G 中点集 V 的大小称作图 G 的阶。 子图(Sub-Graph) - 当图 G’=(V’,E’)其中 V‘包含于 V,E’包含于 E,则 G’称作图 G=(V,E)的子图。每个图都是本身的子图。 生成子图(Spanning Sub-Graph) - 指满足条件 V(G’) = V(G)的 G 的子图 G’。 导出子图(Induced Subgraph) - 以图 G 的顶点集 V 的非空子集V1 为顶点集,以两端点均在 V1 中的全体边为边集的 G 的子图,称为 V1 导出的导出子图;以图 G 的边集 E 的非空子集 E1 为边集,以 E...

2021-12-24
finger
finger用于查找并显示用户信息 补充说明finger命令 用于查找并显示用户信息。包括本地与远端主机的用户皆可,帐号名称没有大小写的差别。单独执行finger指令,它会显示本地主机现在所有的用户的登陆信息,包括帐号名称,真实姓名,登入终端机,闲置时间,登入时间以及地址和电话。 语法1finger(选项)(参数) 选项1234-l:列出该用户的帐号名称,真实姓名,用户专属目录,登入所用的Shell,登入时间,转信地址,电子邮件状态,还有计划文件和方案文件内容;-m:排除查找用户的真实姓名;-s:列出该用户的帐号名称,真实姓名,登入终端机,闲置时间,登入时间以及地址和电话;-p:列出该用户的帐号名称,真实姓名,用户专属目录,登入所用的Shell,登入时间,转信地址,电子邮件状态,但不显示该用户的计划文件和方案文件内容。 不指定finger的选项如果提供操作者的话,缺省设为-l输出风格,否则为-s风格,注意在两种格式中,如果信息不足,都有一些域可能丢失,如果没有指定参数finger会为当前登录的每个用户打印一个条目。 参数用户名:指定要查询信息的用户。 实例在计算机上使用fin...




