
kubeflow
文章
01 kubeflow
MLOps机器学习开发迭代3. 数据收集 a. 大数据量下的文件存储与读取 —— HDFS,NFS 等分布式文件存储系统; b. 非结构化数据 —— S3 等对象存储; c. 向量数据存储 —— milvus 等向量数据库; d. 数据的持续采集与入库 —— Kafka,RabbitMQ 等流式处理工具 ;4. 数据预处理 a. 清洗、格式化、规范化、脱敏 —— Python Pandas; b. 人工标记; c. 特征工程,“数据和特征决定了模型的上限,算法只是在帮忙逼近这个上限”5. 框架选择 a. 训练框架:PyTorch,TensorFlow,PaddlePaddle,……;6. 模型训练 a. 代码开发 —— Python IDE,Notebook; ⅰ. 开发阶段会采集小量的数据,经过小次数的迭代,用于正确性验证, Notebook 可以辅助验证; b. 训练 ⅰ. 本地/单节点/单机单卡/单机多卡/多机多卡 —— GPU 管理与调度 ⅱ. 任务调度/故障转移/check...

02 Notebook
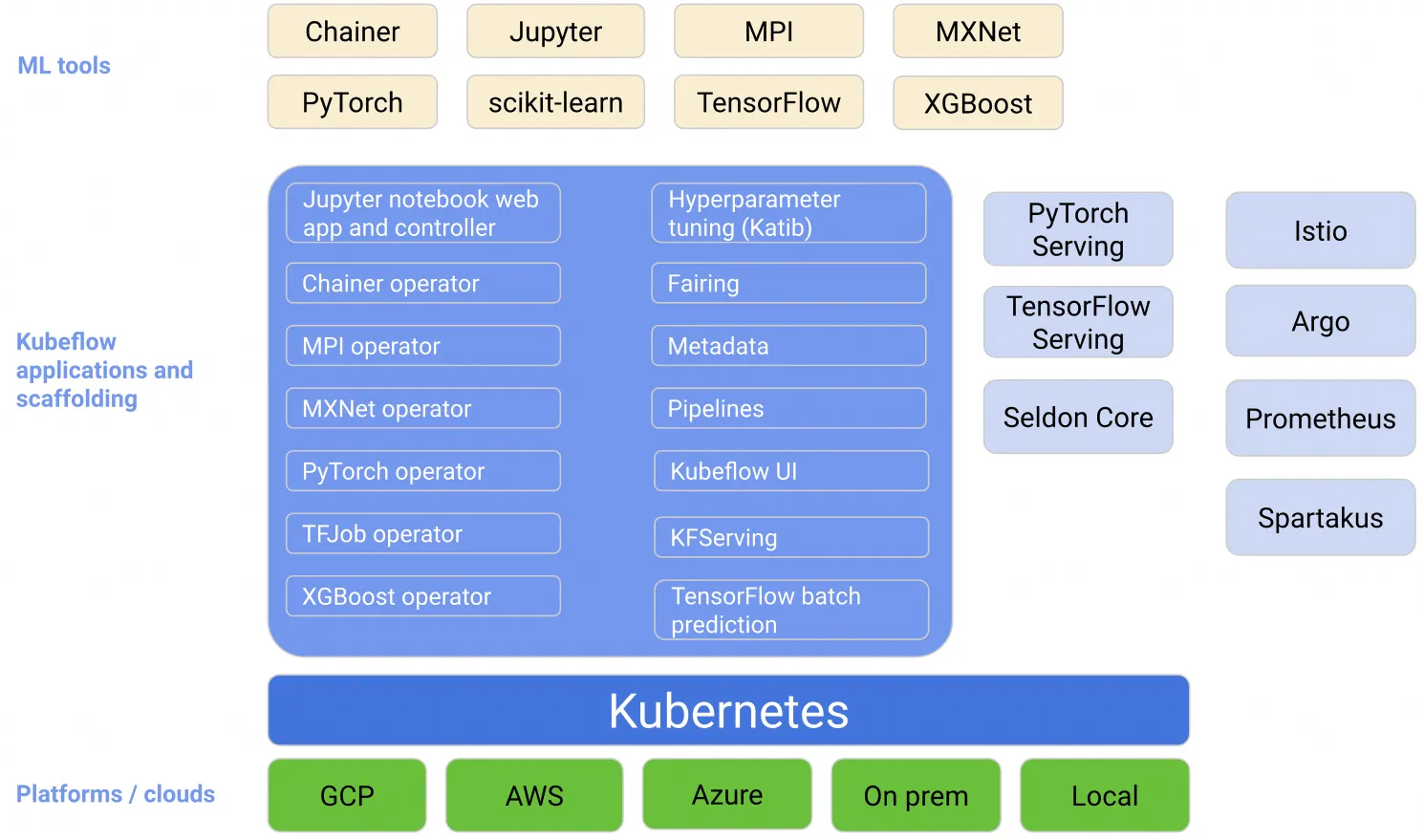
kubeflow 简介是什么Kubeflow 项目致力于使 Kubernetes 上的机器学习 (ML) 工作流程部署变得简单、可移植且可扩展。 组件架构
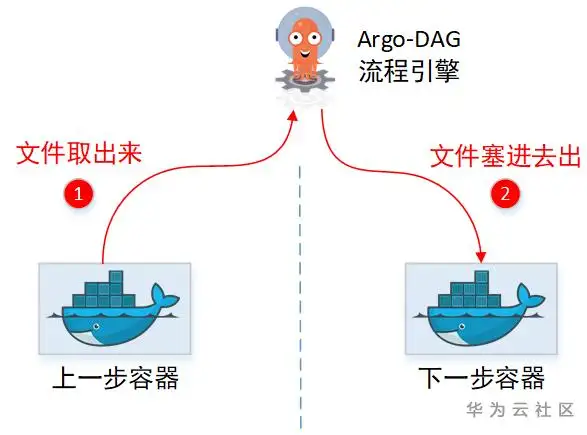
03 Pipelines原理
****## Kubeflow Pipelines 1 PipeLines介绍安装教程https://cloud.tencent.com/developer/article/1674948 使用教程https://juejin.cn/post/6844904195301064712 详细说明 https://blog.csdn.net/qq_45808700/article/details/132188234 1.1 Kubeflow Pipelines介绍kubeflow/kubeflow 是一个胶水项目,pipelines 是基于 kubeflow 实现的工作流系统,它的目标是借助 kubeflow 的底层支持,实现出一套工作流,支持数据准备,模型训练,模型部署,可以通过代码提交等等方式触发 Kubeflow 是一个基于云原生的Machine Learning Platform,它把诸多对机器学习的支持,比如模型训练,超参数训练,模型部署等等结合在了一起,部署了 kubeflow 用户就可以利用它进行不同的机器学习任务,旨于快速在kubernetes环境中构建一套开...

04 pipelines快速开始
1 如何创建一个pipelines部署pipelines安装pipelines sdk安装kfp的python组件 1$ pip install kfp --upgrade 导入kfp相关的包 12import kfpimport kfp.components as comp 创建管道 创建合并数据的业务组件 函数的参数用 kfp.components.InputPath和 kfp.components.OutputPath注释进行修饰。这些注释让 Kubeflow Pipelines 知道提供压缩 tar 文件的路径并创建函数存储合并的 CSV 文件的路径。 用于kfp.components.create_component_from_func 返回可用于创建管道步骤的工厂函数。此示例还指定了运行此函数的基础容器映像、保存组件规范的路径以及运行时需要在容器中安装的 PyPI 包的列表。 123456789101112131415161718def merge_csv(file_path: comp.InputPath('Tarball'), ...




