
机器学习实战1numpy
文章
1.机器学习基础
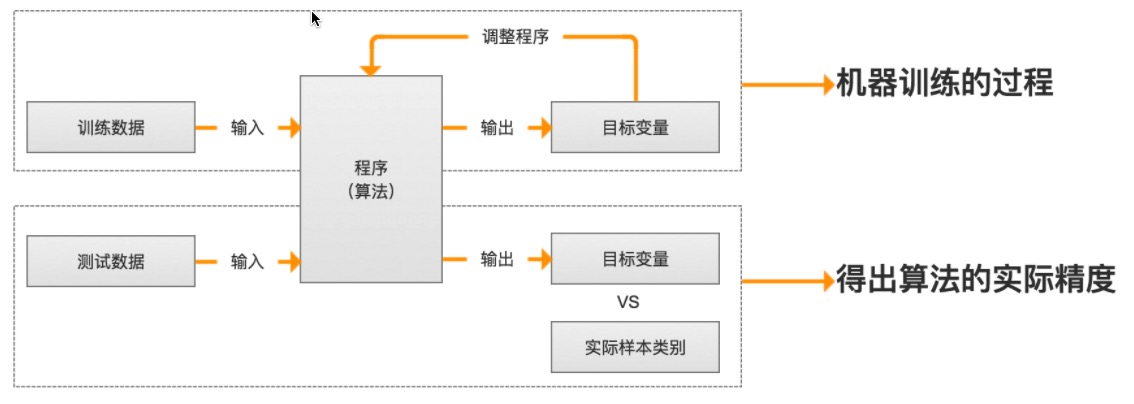
第1章 机器学习基础 参考文献 机器学习实战 ApacheCN机器学习实战笔记 1 机器学习 概述机器学习(Machine Learning,ML) 是使用计算机来彰显数据背后的真实含义,它为了把无序的数据转换成有用的信息。是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。 海量的数据 获取有用的信息 2 机器学习 研究意义机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能”。 “机器学习是对能通过经验自动改进的计算机算法的研究”。 “机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。” 一种经常引用的英文定义是: A computer program is said to learn from experience E with respect to s...
2.k-近邻算法
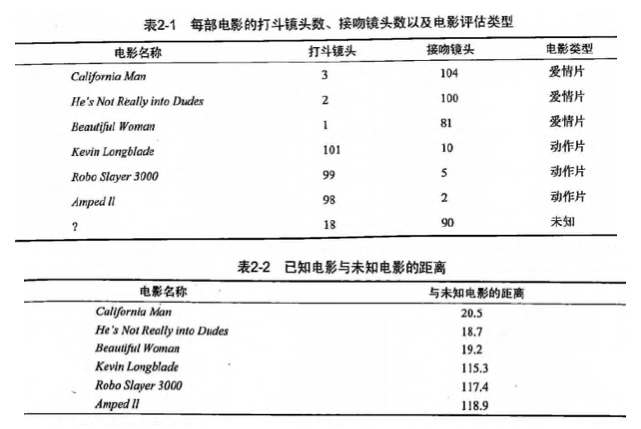
第2章 k-近邻算法1 KNN 概述k-近邻(kNN, k-NearestNeighbor)算法是一种基本分类与回归方法,我们这里只讨论分类问题中的 k-近邻算法。一句话总结: 近朱者赤近墨者黑! k 近邻算法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类。k 近邻算法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其 k 个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此,**k近邻算法不具有显式的学习过程**。 k 近邻算法实际上利用训练数据集对特征向量空间进行划分,并作为其分类的“模型”。 **k值的选择、距离度量以及分类决策规则**是k近邻算法的三个基本要素。 2 KNN 场景 电影可以按照题材分类,那么如何区分 动作片 和 爱情片 呢? 动作片: 打斗次数更多 爱情片: 亲吻次数更多 基于电影中的亲吻、打斗出现的次数,使用 k-近邻算法构造程序,就可以自动划分电影的题材类型。 现在根据上面我们得到的样本集中所有电影与未知电影的距离,按照距离递增排序,可以找到 k 个距离最近的电影。 假定 k=...
3.决策树
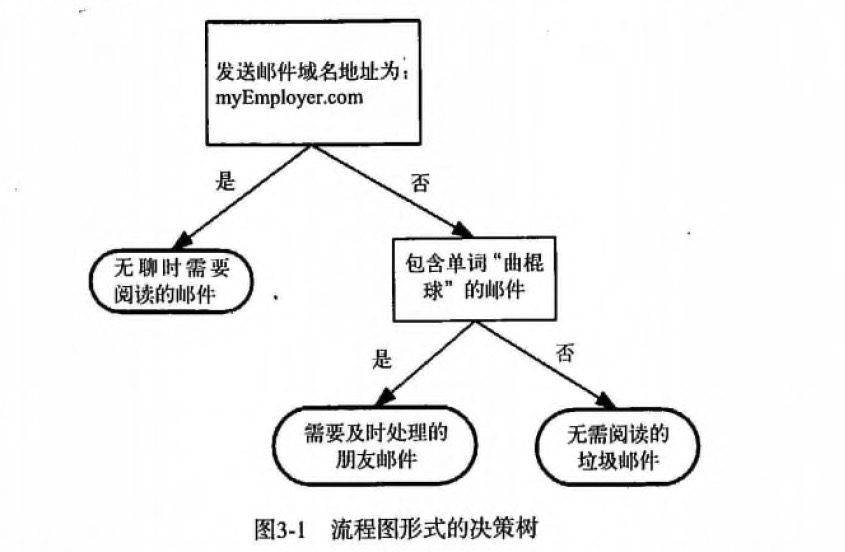
第3章 决策树1 决策树 概述决策树(Decision Tree)算法是一种基本的分类与回归方法,是最经常使用的数据挖掘算法之一。我们这章节只讨论用于分类的决策树。 决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是 if-then 规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。 决策树学习通常包括 3 个步骤: 特征选择、决策树的生成和决策树的修剪。 2 决策树 场景 一个叫做 “二十个问题” 的游戏,游戏的规则很简单: 参与游戏的一方在脑海中想某个事物,其他参与者向他提问,只允许提 20 个问题,问题的答案也只能用对或错回答。问问题的人通过推断分解,逐步缩小待猜测事物的范围,最后得到游戏的答案。 一个邮件分类系统,大致工作流程如下: 123首先检测发送邮件域名地址。如果地址为 myEmployer.com, 则将其放在分类 "无聊时需要阅读的邮件"中。如果邮件不是来自这个域名,则检测邮件内容里是否包含单词 "曲棍球" , 如果包含则将邮件归类到 "需要及时处理的朋友邮件...
4.朴素贝叶斯
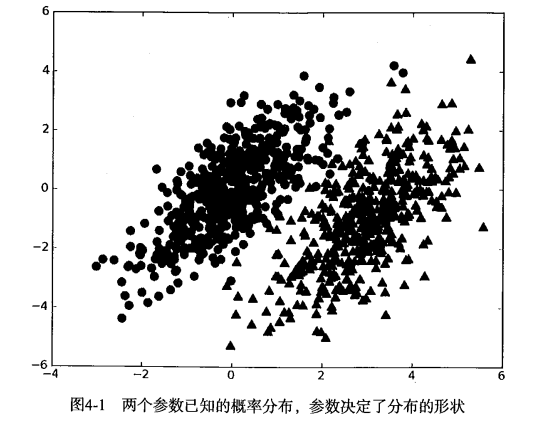
第4章 基于概率论的分类方法: 朴素贝叶斯1 朴素贝叶斯 概述贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。本章首先介绍贝叶斯分类算法的基础——贝叶斯定理。最后,我们通过实例来讨论贝叶斯分类的中最简单的一种: 朴素贝叶斯分类。 2 贝叶斯理论 & 条件概率贝叶斯理论 我们现在有一个数据集,它由两类数据组成,数据分布如下图所示: 我们现在用 p1(x,y) 表示数据点 (x,y) 属于类别 1(图中用圆点表示的类别)的概率,用 p2(x,y) 表示数据点 (x,y) 属于类别 2(图中三角形表示的类别)的概率,那么对于一个新数据点 (x,y),可以用下面的规则来判断它的类别: 如果 p1(x,y) > p2(x,y) ,那么类别为1 如果 p2(x,y) > p1(x,y) ,那么类别为2 也就是说,我们会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。 条件概率 有一个装了 7 块石头的罐子,其中 3 块是白色的,4 块是黑色的。如果从罐子中随机取出一块石头,那么是白色石头的...
5.Logistic回归
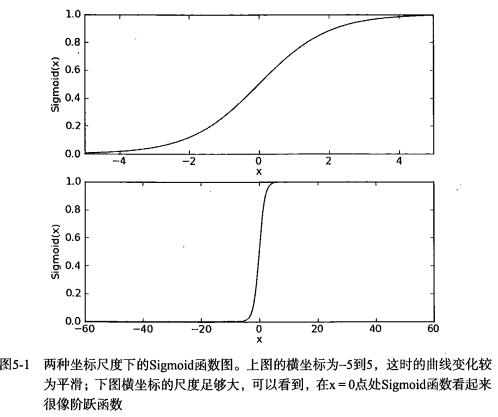
第5章 Logistic回归1 Logistic 回归 概述Logistic 回归 或者叫逻辑回归 虽然名字有回归,但是它是用来做分类的。其主要思想是: 根据现有数据对分类边界线(Decision Boundary)建立回归公式,以此进行分类。 2 须知概念Sigmoid 函数 回归 概念假设现在有一些数据点,我们用一条直线对这些点进行拟合(这条直线称为最佳拟合直线),这个拟合的过程就叫做回归。进而可以得到对这些点的拟合直线方程,那么我们根据这个回归方程,怎么进行分类呢?请看下面。 二值型输出分类函数我们想要的函数应该是: 能接受所有的输入然后预测出类别。例如,在两个类的情况下,上述函数输出 0 或 1.或许你之前接触过具有这种性质的函数,该函数称为 海维塞得阶跃函数(Heaviside step function),或者直接称为 单位阶跃函数。然而,海维塞得阶跃函数的问题在于: 该函数在跳跃点上从 0 瞬间跳跃到 1,这个瞬间跳跃过程有时很难处理。幸好,另一个函数也有类似的性质(可以输出 0 或者 1 的性质),且数学上更易处理,这就是 Sigmoid 函数。 Sigmoid...
6.1.支持向量机说明
SVM 网上资料参考链接 参考文献1 参考文献2 参考文献3 参考文献4 参考文献5 1 支持向量机 概述What’s the SVM? 首先,支持向量机不是一种机器,而是一种机器学习算法。 SVM - Support Vector Machine ,俗称支持向量机,是一种 supervised learning (监督学习)算法,属于 classification (分类)的范畴。 在数据挖掘的应用中,与 unsupervised learning (无监督学习)的 Clustering(聚类)相对应和区别。 广泛应用于 Machine Learning (机器学习),Computer Vision (计算机视觉,装逼一点说,就是 cv)和 Data Mining (数据挖掘)当中。 “ Machine (机)” 是什么? Classification Machine,是分类器,这个没什么好说的。也可以理解为算法,机器学习领域里面常常用 “机” 也就是 machine 这个字表示算法。 “支持向量” 又是什么? 通俗理解 support vector (支持向量)的...
6.支持向量机
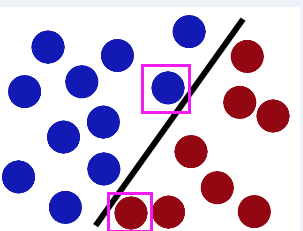
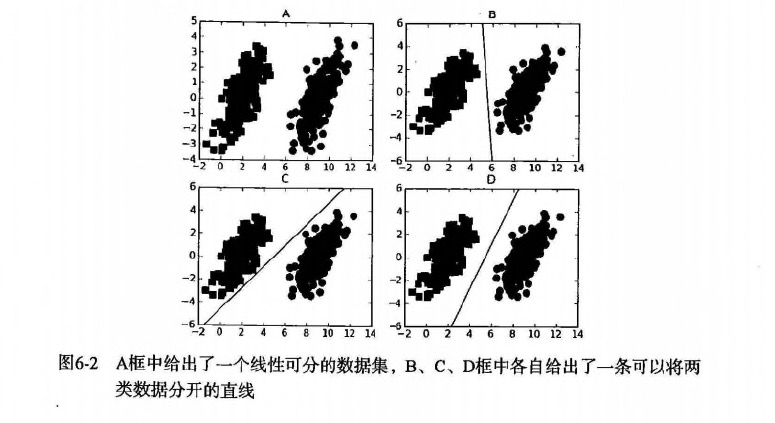
第6章 支持向量机1 支持向量机 概述支持向量机(Support Vector Machines, SVM): 是一种监督学习算法。 支持向量(Support Vector)就是离分隔超平面最近的那些点。 机(Machine)就是表示一种算法,而不是表示机器。 2 支持向量机 场景 要给左右两边的点进行分类 明显发现: 选择D会比B、C分隔的效果要好很多。 3 支持向量机 原理SVM 工作原理 对于上述的苹果和香蕉,我们想象为2种水果类型的炸弹。(保证距离最近的炸弹,距离它们最远) 寻找最大分类间距 转而通过拉格朗日函数求优化的问题 数据可以通过画一条直线就可以将它们完全分开,这组数据叫线性可分(linearly separable)数据,而这条分隔直线称为分隔超平面(separating hyperplane)。 如果数据集上升到1024维呢?那么需要1023维来分隔数据集,也就说需要N-1维的对象来分隔,这个对象叫做超平面(hyperlane),也就是分类的决策边界。 寻找最大间隔 点到超平面的距离 分隔超平面函数间距:$$y(x)=w^Tx+...
7.集成方法-随机森林和AdaBoost
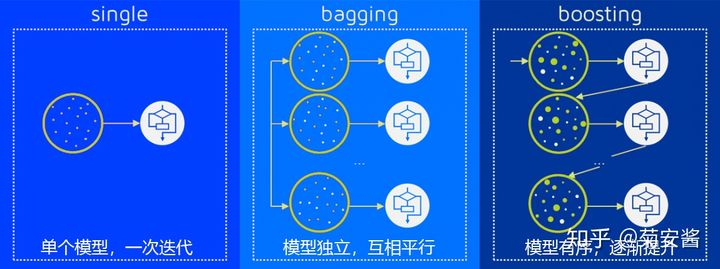
第7章 集成方法 ensemble method 参考文献 https://zhuanlan.zhihu.com/p/62993244 1 集成方法ensemble method/元算法: meta algorithm 概述 概念: 是对其他算法进行组合的一种形式。通俗来说: 当做重要决定时,大家可能都会考虑吸取多个专家而不只是一个人的意见.机器学习处理问题时又何尝不是如此? 这就是集成方法背后的思想。 集成方法: 投票选举bagging=自举汇聚法 bootstrap aggregating: 是基于数据随机重抽样分类器构造的方法。将某个学习算法分别作用于多个数据集就得到了S个分类器。当对新数据进行分类时,可以应用这S个分类器进行分类,选择分类器投票结果中最多的类别作为最后的分类结果。随机森林是比较常见的bagging方法。 再学习(boosting): 是基于所有分类器的加权求和的方法。boosting通过集中关注被已有分类器错分的那些数据来获得新的分类器。由于boosting分类的结果是基于所有分类器的加权求和结果的,因此boos...
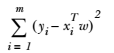
8.回归
第8章 预测数值型数据: 回归回归(Regression) 概述我们前边提到的分类的目标变量是标称型数据,而回归则是对连续型的数据做出处理,回归的目的是预测数值型数据的目标值。 回归 场景回归的目的是预测数值型的目标值。最直接的办法是依据输入写出一个目标值的计算公式。 假如你想要预测兰博基尼跑车的功率大小,可能会这样计算: HorsePower = 0.0015 * annualSalary - 0.99 * hoursListeningToPublicRadio 这就是所谓的 回归方程(regression equation),其中的 0.0015 和 -0.99 称作 回归系数(regression weights),求这些回归系数的过程就是回归。一旦有了这些回归系数,再给定输入,做预测就非常容易了。具体的做法是用回归系数乘以输入值,再将结果全部加在一起,就得到了预测值。我们这里所说的,回归系数是一个向量,输入也是向量,这些运算也就是求出二者的内积。 说到回归,一般都是指 线性回归(linear regression)。线性回归意味着可以将输入项分别乘以一些常量,再...

9.树回归
第9章 树回归 树回归 概述我们本章介绍 CART(Classification And Regression Trees, 分类回归树) 的树构建算法。该算法既可以用于分类还可以用于回归。 树回归 场景我们在第 8 章中介绍了线性回归的一些强大的方法,但这些方法创建的模型需要拟合所有的样本点(局部加权线性回归除外)。当数据拥有众多特征并且特征之间关系十分复杂时,构建全局模型的想法就显得太难了,也略显笨拙。而且,实际生活中很多问题都是非线性的,不可能使用全局线性模型来拟合任何数据。 一种可行的方法是将数据集切分成很多份易建模的数据,然后利用我们的线性回归技术来建模。如果首次切分后仍然难以拟合线性模型就继续切分。在这种切分方式下,树回归和回归法就相当有用。 除了我们在 第3章 中介绍的 决策树算法,我们介绍一个新的叫做 CART(Classification And Regression Trees, 分类回归树) 的树构建算法。该算法既可以用于分类还可以用于回归。 1、树回归 原理1.1、树回归 原理概述为成功构建以分段常数为叶节点的树,需要度量出数据的一致性。第3章使用树进...




