
机器学习实战1numpy
文章
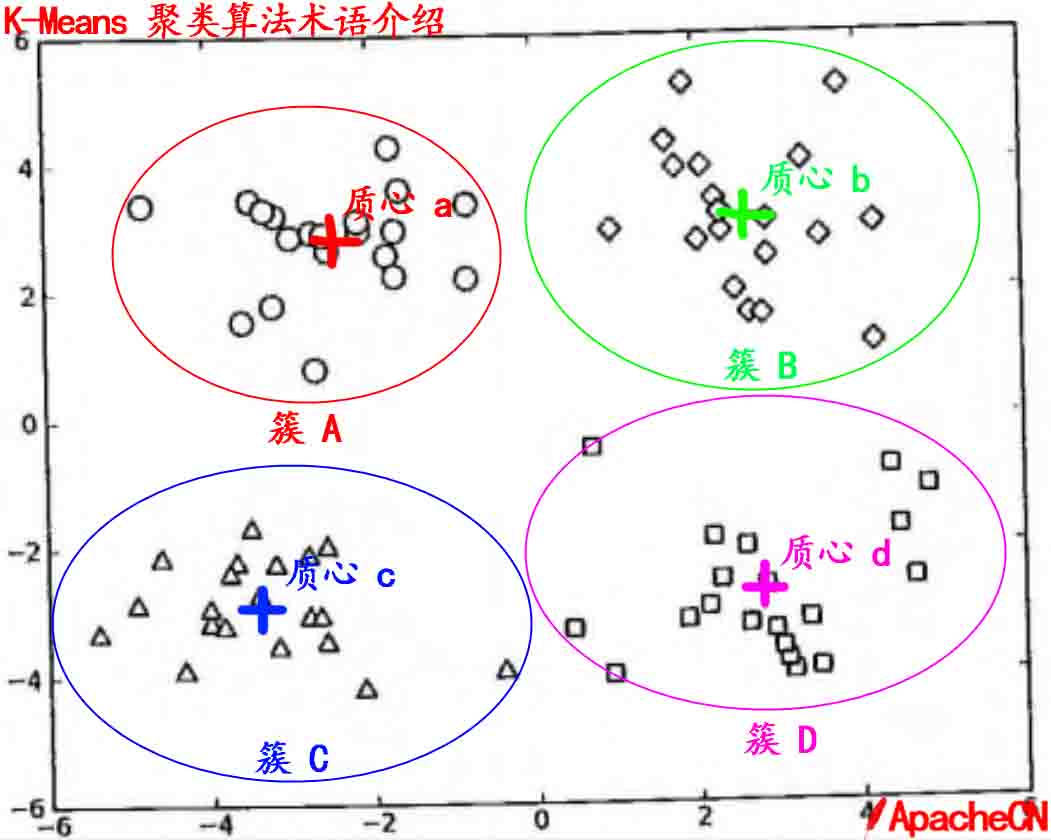
10.KMeans聚类
第 10 章 K-Means(K-均值)聚类算法聚类聚类,简单来说,就是将一个庞杂数据集中具有相似特征的数据自动归类到一起,称为一个簇,簇内的对象越相似,聚类的效果越好。它是一种无监督的学习(Unsupervised Learning)方法,不需要预先标注好的训练集。聚类与分类最大的区别就是分类的目标事先已知,例如猫狗识别,你在分类之前已经预先知道要将它分为猫、狗两个种类;而在你聚类之前,你对你的目标是未知的,同样以动物为例,对于一个动物集来说,你并不清楚这个数据集内部有多少种类的动物,你能做的只是利用聚类方法将它自动按照特征分为多类,然后人为给出这个聚类结果的定义(即簇识别)。例如,你将一个动物集分为了三簇(类),然后通过观察这三类动物的特征,你为每一个簇起一个名字,如大象、狗、猫等,这就是聚类的基本思想。 至于“相似”这一概念,是利用距离这个评价标准来衡量的,我们通过计算对象与对象之间的距离远近来判断它们是否属于同一类别,即是否是同一个簇。至于距离如何计算,科学家们提出了许多种距离的计算方法,其中欧式距离是最为简单和常用的,除此之外还有曼哈顿距离和余弦相似性距离等。...

11.使用Apriori算法进行关联分析
第 11 章 使用 Apriori 算法进行关联分析关联分析关联分析是一种在大规模数据集中寻找有趣关系的任务。这些关系可以有两种形式: 频繁项集(frequent item sets): 经常出现在一块的物品的集合。 关联规则(associational rules): 暗示两种物品之间可能存在很强的关系。 相关术语 关联分析(关联规则学习): 从大规模数据集中寻找物品间的隐含关系被称作 关联分析(associati analysis) 或者 关联规则学习(association rule learning) 。下面是用一个 杂货店 例子来说明这两个概念,如下图所示: 频繁项集: {葡萄酒, 尿布, 豆奶} 就是一个频繁项集的例子。 关联规则: 尿布 -> 葡萄酒 就是一个关联规则。这意味着如果顾客买了尿布,那么他很可能会买葡萄酒。 那么 频繁 的定义是什么呢?怎么样才算频繁呢?度量它们的方法有很多种,这里我们来简单的介绍下支持度和可信度。 支持度: 数据集中包含该项集的记录所占的比例。例如上图中,{豆奶} 的支持度为 4/5。{豆奶, 尿布} 的...
12.使用FP-growth算法来高效发现频繁项集
第12章 使用FP-growth算法来高效发现频繁项集前言在 第11章 时我们已经介绍了用 Apriori 算法发现 频繁项集 与 关联规则。本章将继续关注发现 频繁项集 这一任务,并使用 FP-growth 算法更有效的挖掘 频繁项集。 FP-growth 算法简介 一种非常好的发现频繁项集算法。 基于Apriori算法构建,但是数据结构不同,使用叫做 FP树 的数据结构结构来存储集合。下面我们会介绍这种数据结构。 FP-growth 算法步骤 基于数据构建FP树 从FP树种挖掘频繁项集 FP树 介绍 FP树的节点结构如下: 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748class treeNode: def __init__(self, nameValue, numOccur, parentNode): self.name = nameValue # 节点名称 self.count = numOc...
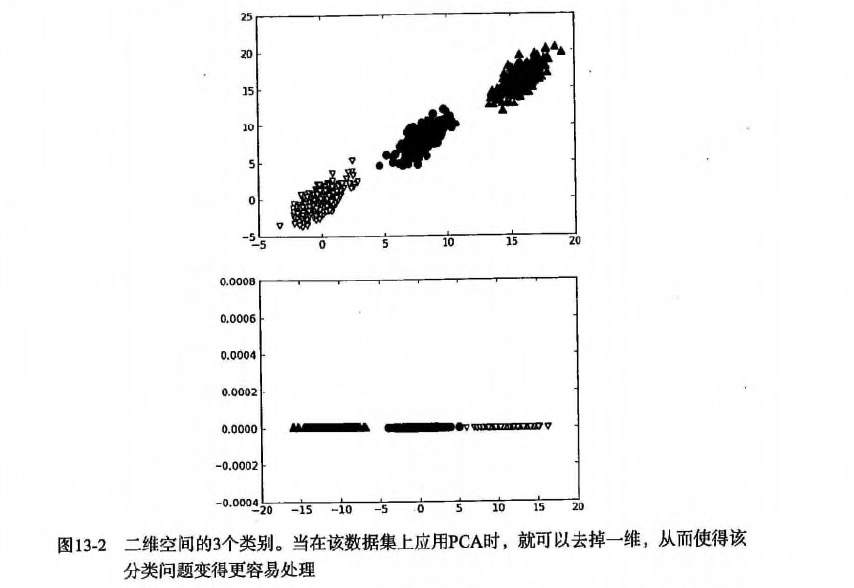
13.利用PCA来简化数据
第13章 利用 PCA 来简化数据降维技术 场景 我们正通过电视观看体育比赛,在电视的显示器上有一个球。 显示器大概包含了100万像素点,而球则可能是由较少的像素点组成,例如说一千个像素点。 人们实时的将显示器上的百万像素转换成为一个三维图像,该图像就给出运动场上球的位置。 在这个过程中,人们已经将百万像素点的数据,降至为三维。这个过程就称为降维(dimensionality reduction) 数据显示 并非大规模特征下的唯一难题,对数据进行简化还有如下一系列的原因: 使得数据集更容易使用 降低很多算法的计算开销 去除噪音 使得结果易懂 适用范围: 在已标注与未标注的数据上都有降维技术。 这里我们将主要关注未标注数据上的降维技术,将技术同样也可以应用于已标注的数据。 在以下3种降维技术中, PCA的应用目前最为广泛,因此本章主要关注PCA。 主成分分析(Principal Component Analysis, PCA) 通俗理解: 就是找出一个最主要的特征,然后进行分析。 例如: 考察一个人的智力情况,就直接看...
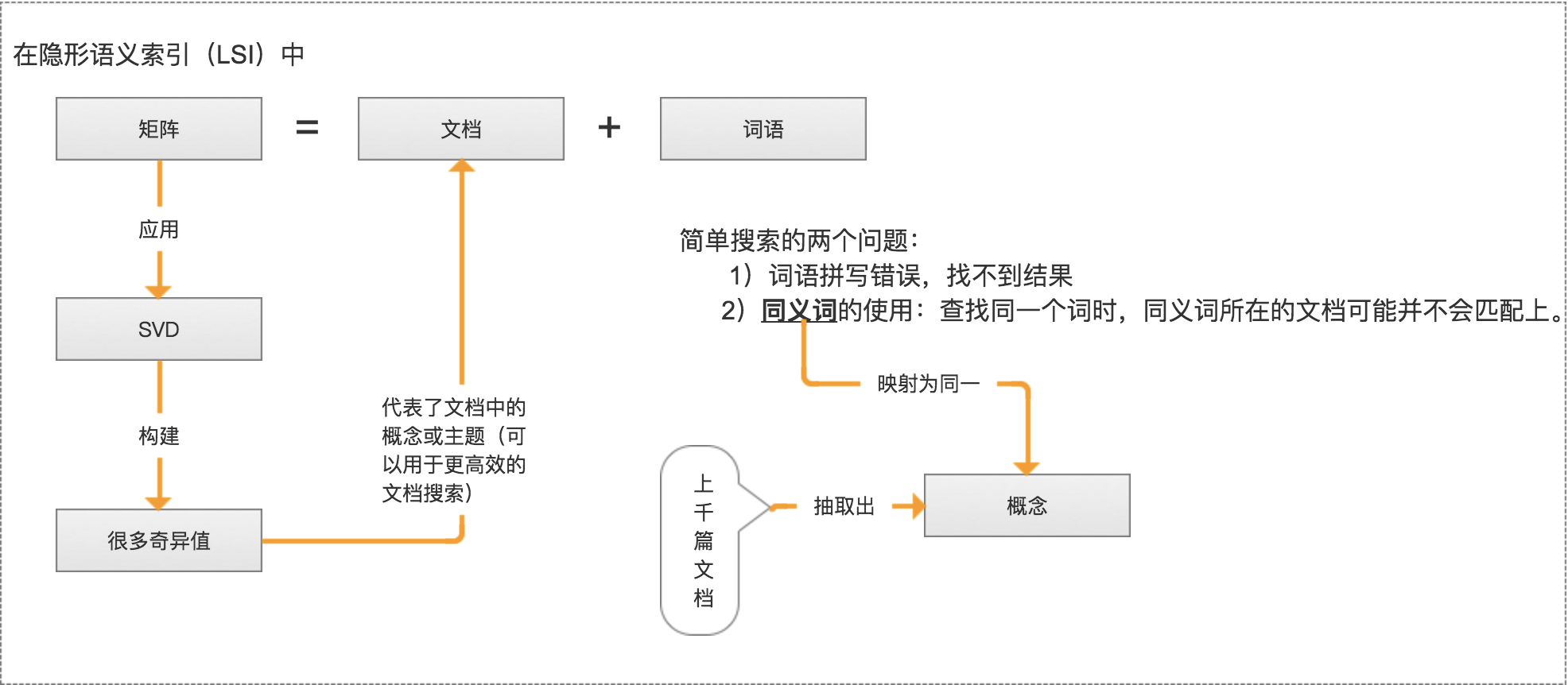
14.利用SVD简化数据
第14章 利用SVD简化数据SVD 概述12奇异值分解(SVD, Singular Value Decomposition): 提取信息的一种方法,可以把 SVD 看成是从噪声数据中抽取相关特征。从生物信息学到金融学,SVD 是提取信息的强大工具。 SVD 场景 信息检索-隐性语义检索(Latent Semantic Indexing, LSI)或 隐形语义分析(Latent Semantic Analysis, LSA) 隐性语义索引: 矩阵 = 文档 + 词语 是最早的 SVD 应用之一,我们称利用 SVD 的方法为隐性语义索引(LSI)或隐性语义分析(LSA)。 推荐系统 利用 SVD 从数据中构建一个主题空间。 再在该空间下计算其相似度。(从高维-低维空间的转化,在低维空间来计算相似度,SVD 提升了推荐系统的效率。) 上图右边标注的为一组共同特征,表示美式 BBQ 空间;另一组在上图右边未标注的为日式食品 空间。 图像压缩 例如: 32*32=1024 => 32*2+2*1+32*2=130(2*1表示去掉了除对角线的...
15.大数据与MapReduce
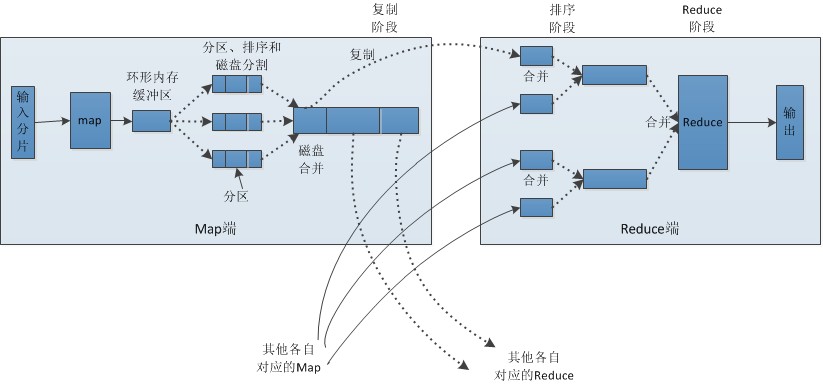
第15章 大数据与MapReduce大数据 概述大数据: 收集到的数据已经远远超出了我们的处理能力。 大数据 场景1234假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则随意浏览后就离开。对于你来说,可能很想识别那些有购物意愿的用户。那么问题就来了,数据集可能会非常大,在单机上训练要运行好几天。接下来: 我们讲讲 MapRedece 如何来解决这样的问题 MapRedeceHadoop 概述12Hadoop 是 MapRedece 框架的一个免费开源实现。MapReduce: 分布式的计算框架,可以将单个计算作业分配给多台计算机执行。 MapRedece 原理 MapRedece 工作原理 主节点控制 MapReduce 的作业流程 MapReduce 的作业可以分成map任务和reduce任务 map 任务之间不做数据交流,reduce 任务也一样 在 map 和 reduce 阶段中间,有一个 sort 和 combine 阶段 数据被重复存放在不同的机器上,以防止某个机器失效 mapper 和 reducer 传输的数据形式为 ke...
16.推荐系统
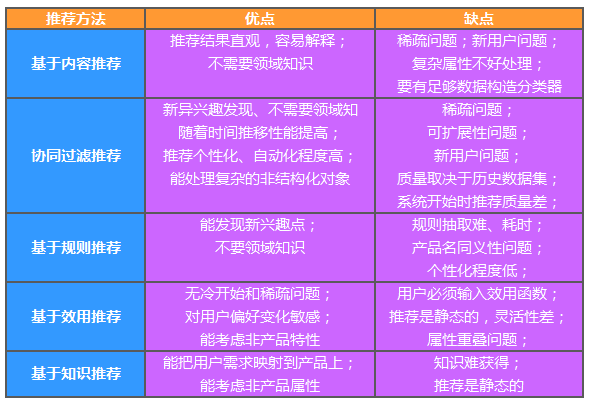
第16章 推荐系统背景与挖掘目标随着互联网的快速发展,用户很难快速从海量信息中寻找到自己感兴趣的信息。因此诞生了: 搜索引擎+推荐系统 本章节-推荐系统: 帮助用户发现其感兴趣和可能感兴趣的信息。 让网站价值信息脱颖而出,得到广大用户的认可。 提高用户对网站的忠诚度和关注度,建立稳固用户群体。 分析方法与过程本案例的目标是对用户进行推荐,即以一定的方式将用户与物品(本次指网页)之间建立联系。 由于用户访问网站的数据记录很多,如果不对数据进行分类处理,对所有的记录直接采用推荐系统进行推荐,这样会存在一下问题。 数据量太大意味着物品数与用户数很多,在模型构建用户与物品稀疏矩阵时,出现设备内存空间不够的情况,并且模型计算需要消耗大量的时间。 用户区别很大,不同的用户关注的信息不一样,因此,即使能够得到推荐结果,其效果也会不好。 为了避免出现上述问题,需要进行分类处理与分析。 正常的情况下,需要对用户的兴趣爱好以及需求进行分类。因为在用户访问记录中,没有记录用户访问页面时间的长短,因此不容易判断用户兴趣爱好。因此,本文根据用户浏览的网页信息进行分析处理,主要采用以下方法处理: ...




