
机器学习实战1sklearn-tensorflow
文章

0
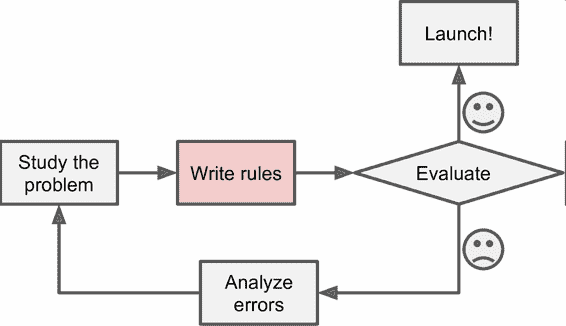
零、前言 译者:@小瑶 校对者:@小瑶 1、机器学习海啸2006 年,Geoffrey Hinton 等人发表了一篇论文,展示了如何训练能够识别具有最新精度(> 98%)的手写数字的深度神经网络。他们称这种技术为“Deep Learning”。当时,深度神经网络的训练被广泛认为是不可能的,并且大多数研究人员自 20 世纪 90 年代以来就放弃了这个想法。这篇论文重新激起了科学界的兴趣,不久之后,许多新发表的论文表明,深度学习不仅是可能的,而且能够取得其他的 Machine Learning 技术都难以匹配的令人兴奋的成就(借助巨大的计算能力和大量的数据)。这种热情很快扩展到机器学习的许多的其他领域。 Deep Learning 快速发展的 10 年间和机器学习已经征服了这个行业:它现在成为了当今高科技产品中的许多黑科技的核心,比如,为您的网络搜索结果排名,为智能手机的语音识别提供支持,为您推荐您喜欢的视频,在围棋游戏中击败世界冠军。在你知道之前,它都可能会驾驶您的汽车。 2、您项目中的机器学习现在你是不是对机器学习感到兴奋,并且很乐意加入到这个阵营中?也许你希望给自己制造...
1
一、机器学习概览 译者:@SeanCheney 校对者:@Lisanaaa、@飞龙、@yanmengk、@Liu Shangfeng 大多数人听到“机器学习”,往往会在脑海中勾勒出一个机器人:一个可靠的管家,或是一个可怕的终结者,这取决于你问的是谁。但是机器学习并不是未来的幻想,它已经来到我们身边了。事实上,一些特定领域已经应用机器学习几十年了,比如光学字符识别 (Optical Character Recognition,OCR)。但是直到 1990 年代,第一个影响了数亿人的机器学习应用才真正成熟,它就是垃圾邮件过滤器(spam filter)。虽然并不是一个有自我意识的天网系统(Skynet),垃圾邮件过滤器从技术上是符合机器学习的(它可以很好地进行学习,用户几乎不用再标记某个邮件为垃圾邮件)。后来出现了更多的数以百计的机器学习产品,支撑了更多你经常使用的产品和功能,从推荐系统到语音识别。 机器学习的起点和终点分别是什么呢?确切的讲,机器进行学习是什么意思?如果我下载了一份维基百科的拷贝,我的电脑就真的学会了什么吗?它马上就变聪明了吗?在本章中,我们首先会澄清机器学习到底...
2
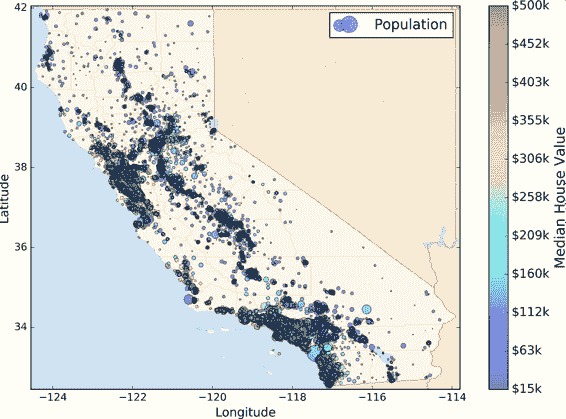
二、端到端的机器学习项目 译者:@SeanCheney 校对者:@Lisanaaa、@飞龙、@PeterHo、@ZhengqiJiang、@tabeworks 本章中,你会假装作为被一家地产公司刚刚雇佣的数据科学家,完整地学习一个案例项目。下面是主要步骤: 项目概述。 获取数据。 发现并可视化数据,发现规律。 为机器学习算法准备数据。 选择模型,进行训练。 微调模型。 给出解决方案。 部署、监控、维护系统。 使用真实数据学习机器学习时,最好使用真实数据,而不是人工数据集。幸运的是,有上千个开源数据集可以进行选择,涵盖多个领域。以下是一些可以查找的数据的地方: 流行的开源数据仓库: UC Irvine Machine Learning Repository Kaggle datasets Amazon’s AWS datasets 准入口(提供开源数据列表) http://dataportals.org/ http://opendatamonitor.eu/ http://quandl.com/ 其它列出流行开源数据仓库的网页: Wikipedia’...
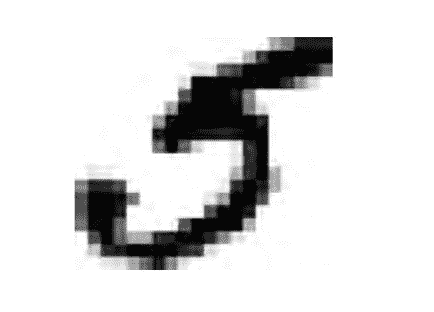
3
三、分类 译者:@时间魔术师 校对者:@Lisanaaa、@飞龙、@ZTFrom1994、@XinQiu、@tabeworks、@JasonLee、@howie.hu 在第一章我们提到过最常用的监督学习任务是回归(用于预测某个值)和分类(预测某个类别)。在第二章我们探索了一个回归任务:预测房价。我们使用了多种算法,诸如线性回归,决策树,和随机森林(这个将会在后面的章节更详细地讨论)。现在我们将我们的注意力转到分类任务上。 MNIST在本章当中,我们将会使用 MNIST 这个数据集,它有着 70000 张规格较小的手写数字图片,由美国的高中生和美国人口调查局的职员手写而成。这相当于机器学习当中的“Hello World”,人们无论什么时候提出一个新的分类算法,都想知道该算法在这个数据集上的表现如何。机器学习的初学者迟早也会处理 MNIST 这个数据集。 Scikit-Learn 提供了许多辅助函数,以便于下载流行的数据集。MNIST 是其中一个。下面的代码获取 MNIST 12345678910111213>>> from sklearn.datasets im...
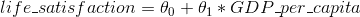
4
四、训练模型 译者:@C-PIG 校对者:@PeterHo、@飞龙、@YuWang、@AlecChen 在之前的描述中,我们通常把机器学习模型和训练算法当作黑箱子来处理。如果你实践过前几章的一些示例,你惊奇的发现你可以优化回归系统,改进数字图像的分类器,你甚至可以零基础搭建一个垃圾邮件的分类器,但是你却对它们内部的工作流程一无所知。事实上,许多场合你都不需要知道这些黑箱子的内部有什么,干了什么。 然而,如果你对其内部的工作流程有一定了解的话,当面对一个机器学习任务时候,这些理论可以帮助你快速的找到恰当的机器学习模型,合适的训练算法,以及一个好的假设集。同时,了解黑箱子内部的构成,有助于你更好地调试参数以及更有效的误差分析。本章讨论的大部分话题对于机器学习模型的理解,构建,以及神经网络(详细参考本书的第二部分)的训练都是非常重要的。 首先我们将以一个简单的线性回归模型为例,讨论两种不同的训练方法来得到模型的最优解: 直接使用封闭方程进行求根运算,得到模型在当前训练集上的最优参数(即在训练集上使损失函数达到最小值的模型参数) 使用迭代优化方法:梯度下降(GD),在训练集上,它可...
5
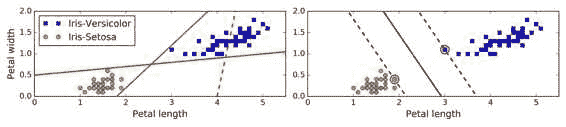
五、支持向量机 译者:@QiaoXie 校对者:@飞龙、@PeterHo、@yanmengk、@YuWang 支持向量机(SVM)是个非常强大并且有多种功能的机器学习模型,能够做线性或者非线性的分类,回归,甚至异常值检测。机器学习领域中最为流行的模型之一,是任何学习机器学习的人必备的工具。SVM 特别适合应用于复杂但中小规模数据集的分类问题。 本章节将阐述支持向量机的核心概念,怎么使用这个强大的模型,以及它是如何工作的。 线性支持向量机分类SVM 的基本思想能够用一些图片来解释得很好,图 5-1 展示了我们在第 4 章结尾处介绍的鸢尾花数据集的一部分。这两个种类能够被非常清晰,非常容易的用一条直线分开(即线性可分的)。左边的图显示了三种可能的线性分类器的判定边界。其中用虚线表示的线性模型判定边界很差,甚至不能正确地划分类别。另外两个线性模型在这个数据集表现的很好,但是它们的判定边界很靠近样本点,在新的数据上可能不会表现的很好。相比之下,右边图中 SVM 分类器的判定边界实线,不仅分开了两种类别,而且还尽可能地远离了最靠近的训练数据点。你可以认为 SVM 分类器在两种类别之间保持...
6
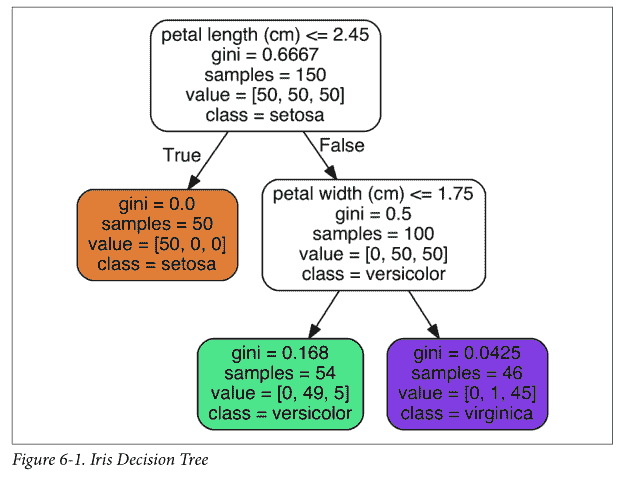
# 六、决策树 > 译者:[@Lisanaaa](https://github.com/Lisanaaa)、[@y3534365](https://github.com/y3534365) > > 校对者:[@飞龙](https://github.com/wizardforcel)、[@YuWang](https://github.com/bigeyex) 和支持向量机一样, 决策树是一种多功能机器学习算法, 即可以执行分类任务也可以执行回归任务, 甚至包括多输出(multioutput)任务. 它是一种功能很强大的算法,可以对很复杂的数据集进行拟合。例如,在第二章中我们对加利福尼亚住房数据集使用决策树回归模型进行训练,就很好的拟合了数据集(实际上是过拟合)。 决策树也是随机森林的基本组成部分(见第 7 章),而随机森林是当今最强大的机器学习算法之一。 在本章中,我们将首先讨论如何使用决策树进行训练,可视化和预测。 然后我们会学习在 Scikit-learn 上面使用 CART 算法,并且探讨如何调整决策树让它可以用于执行回归任务。 最后,我们当然也需要讨论一...
7
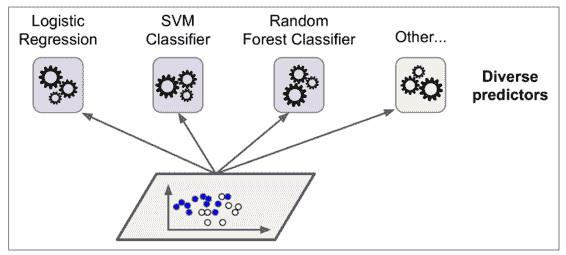
七、集成学习和随机森林 译者:@friedhelm739 校对者:@飞龙、@PeterHo、@yanmengk、@XinQiu、@YuWang 假设你去随机问很多人一个很复杂的问题,然后把它们的答案合并起来。通常情况下你会发现这个合并的答案比一个专家的答案要好。这就叫做群体智慧。同样的,如果你合并了一组分类器的预测(像分类或者回归),你也会得到一个比单一分类器更好的预测结果。这一组分类器就叫做集成;因此,这个技术就叫做集成学习,一个集成学习算法就叫做集成方法。 例如,你可以训练一组决策树分类器,每一个都在一个随机的训练集上。为了去做预测,你必须得到所有单一树的预测值,然后通过投票(例如第六章的练习)来预测类别。例如一种决策树的集成就叫做随机森林,它除了简单之外也是现今存在的最强大的机器学习算法之一。 向我们在第二章讨论的一样,我们会在一个项目快结束的时候使用集成算法,一旦你建立了一些好的分类器,就把他们合并为一个更好的分类器。事实上,在机器学习竞赛中获得胜利的算法经常会包含一些集成方法。 在本章中我们会讨论一下特别著名的集成方法,包括 bagging, boosting, s...
8
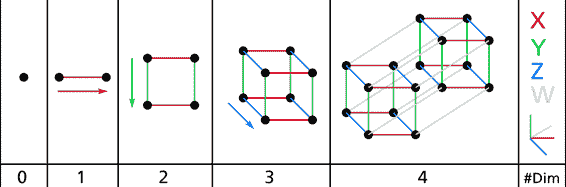
八、降维 译者:@loveSnowBest 校对者:@飞龙、@PeterHo、@yanmengk、@XinQiu、@Lisanaaa 很多机器学习的问题都会涉及到有着几千甚至数百万维的特征的训练实例。这不仅让训练过程变得非常缓慢,同时还很难找到一个很好的解,我们接下来就会遇到这种情况。这种问题通常被称为维数灾难(curse of dimentionality)。 幸运的是,在现实生活中我们经常可以极大的降低特征维度,将一个十分棘手的问题转变成一个可以较为容易解决的问题。例如,对于 MNIST 图片集(第 3 章中提到):图片四周边缘部分的像素几乎总是白的,因此你完全可以将这些像素从你的训练集中扔掉而不会丢失太多信息。图 7-6 向我们证实了这些像素的确对我们的分类任务是完全不重要的。同时,两个相邻的像素往往是高度相关的:如果你想要将他们合并成一个像素(比如取这两个像素点的平均值)你并不会丢失很多信息。 警告:降维肯定会丢失一些信息(这就好比将一个图片压缩成 JPEG 的格式会降低图像的质量),因此即使这种方法可以加快训练的速度,同时也会让你的系统表现的稍微差一点。降维...
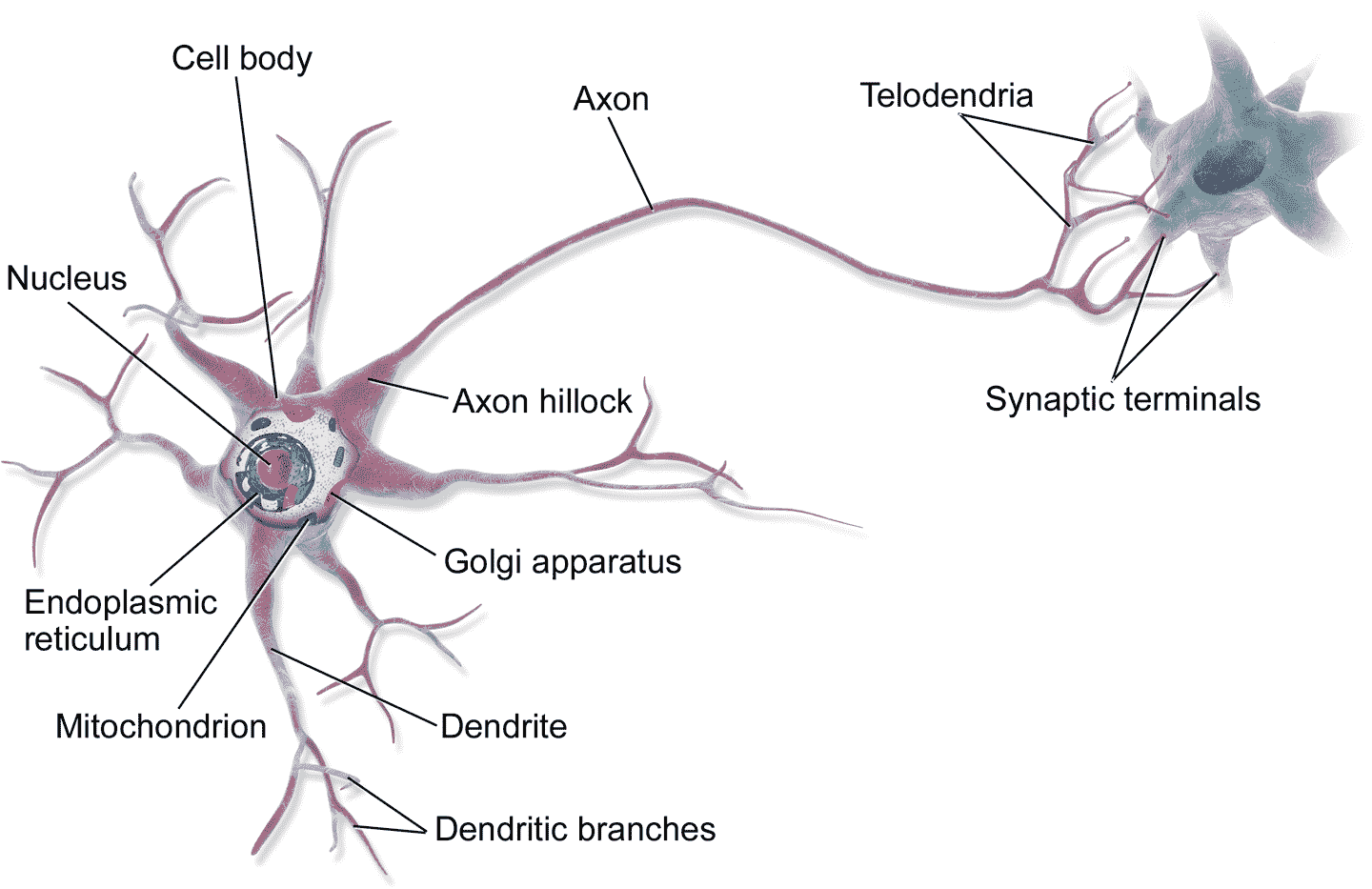
10
十、使用 Keras 搭建人工神经网络 译者:@SeanCheney 鸟类启发人类飞翔,东洋参启发了魔术贴的发明,大自然启发人类实现了无数发明创造。通过研究大脑来制造智能机器,也符合这个逻辑。人工神经网络(ANN)就是沿着这条逻辑诞生的:人工神经网络是受大脑中的生物神经元启发而来的机器学习模型。但是,虽然飞机是受鸟儿启发而来的,飞机却不用挥动翅膀。相似的,人工神经网络和生物神经元网络也是具有不同点的。一些研究者甚至认为,应该彻底摒弃这种生物学类比:例如,用“单元”取代“神经元”,以免人们将创造力局限于生物学系统的合理性上。 人工神经网络是深度学习的核心,它不仅样式多样、功能强大,还具有可伸缩性,这让人工神经网络适宜处理庞大且复杂的机器学习任务,例如对数十亿张图片分类(谷歌图片)、语音识别(苹果 Siri)、向数亿用户每天推荐视频(Youtube)、或者通过学习几百围棋世界冠军(DeepMind 的 AlphaGo)。 本章的第一部分会介绍人工神经网络,从一个简单的 ANN 架构开始,然后过渡到多层感知机(MLP),后者的应用非常广泛(后面的章节会介绍其他的架构)。第二部分会介绍...




