
机器学习实战1sklearn-tensorflow
文章
11
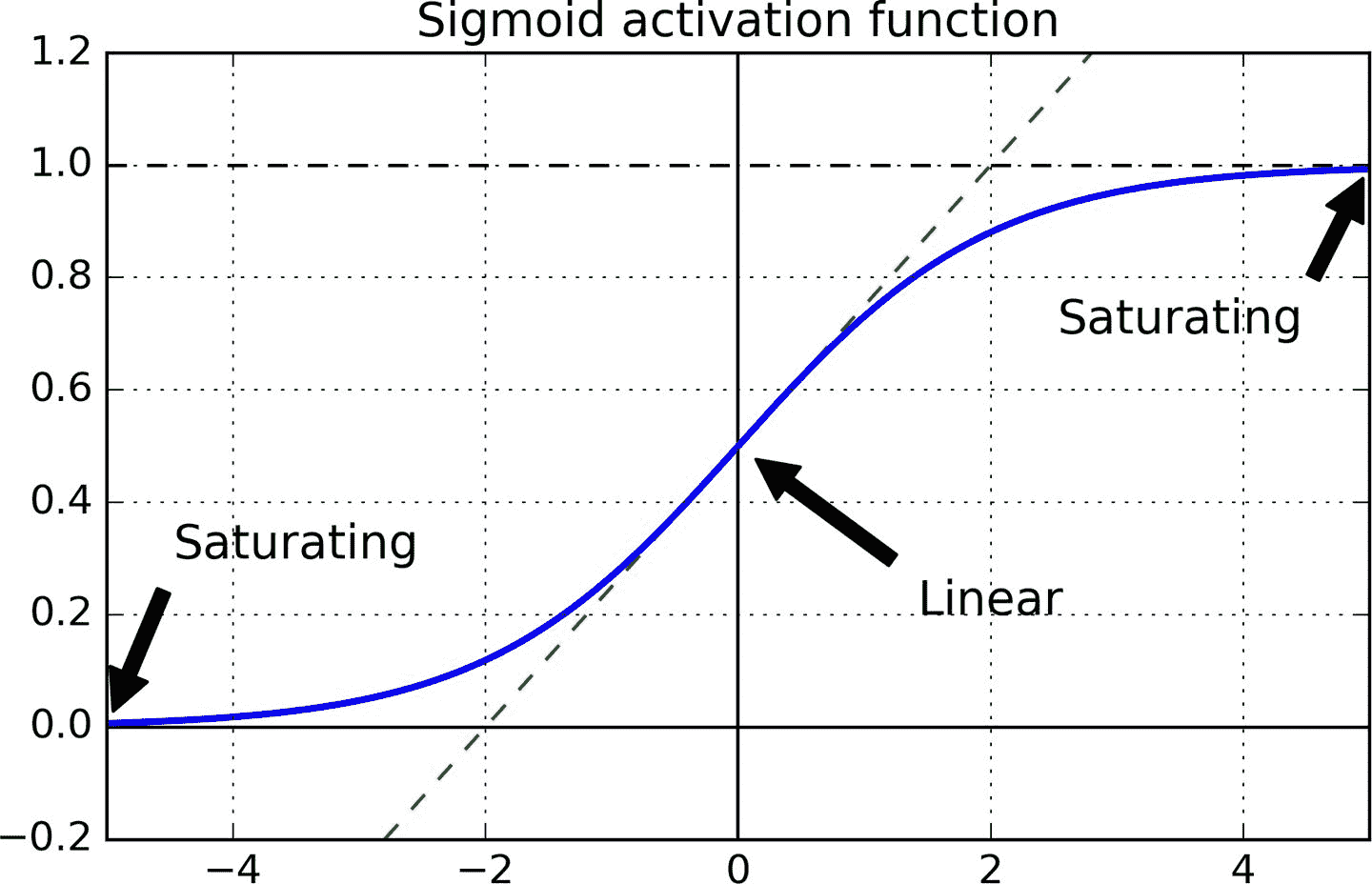
十一、训练深度神经网络 译者:@SeanCheney 第 10 章介绍了人工神经网络,并训练了第一个深度神经网络。 但它非常浅,只有两个隐藏层。 如果你需要解决非常复杂的问题,例如检测高分辨率图像中的数百种类型的对象,该怎么办? 你可能需要训练更深的 DNN,也许有 10 层或更多,每层包含数百个神经元,通过数十万个连接相连。 这可不像公园散步那么简单,可能碰到下面这些问题: 你将面临棘手的梯度消失问题(或相关的梯度爆炸问题):在反向传播过程中,梯度变得越来越小或越来越大。二者都会使较浅层难以训练; 要训练一个庞大的神经网络,但是数据量不足,或者标注成本很高; 训练可能非常慢; 具有数百万参数的模型将会有严重的过拟合训练集的风险,特别是在训练实例不多或存在噪音时。 在本章中,我们将依次讨论这些问题,并给出解决问题的方法。 我们将从梯度消失/爆炸问题开始,并探讨解决这个问题的一些最流行的解决方案。 接下来会介绍迁移学习和无监督预训练,这可以在即使标注数据不多的情况下,也能应对复杂问题。然后我们将看看各种优化器,可以加速大型模型的训练。 最后,我们将浏览一些流行的大型...
12
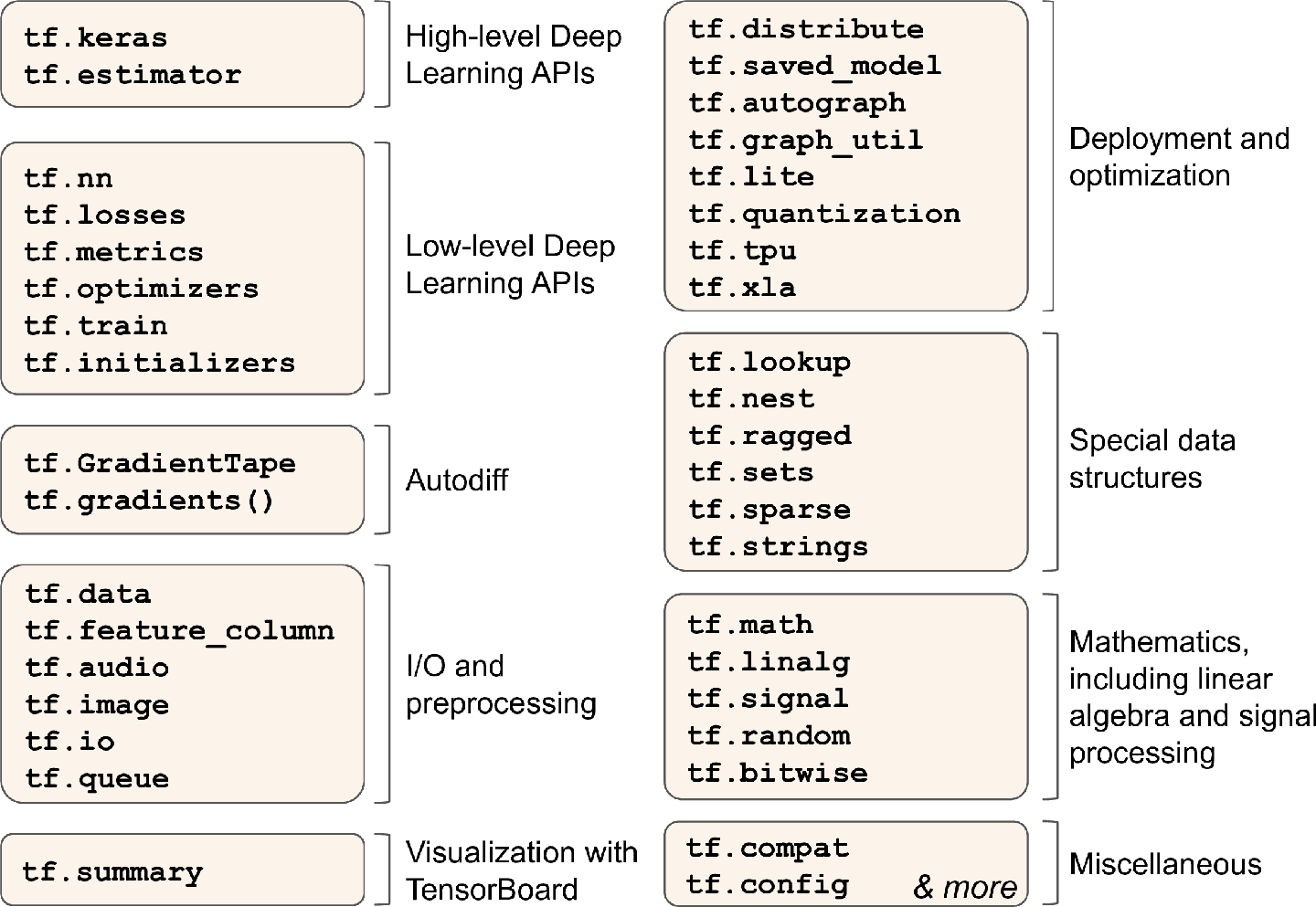
十二、使用 TensorFlow 自定义模型并训练 译者:@SeanCheney 目前为止,我们只是使用了 TensorFlow 的高级 API —— tf.keras,它的功能很强大:搭建了各种神经网络架构,包括回归、分类网络、Wide & Deep 网络、自归一化网络,使用了各种方法,包括批归一化、丢弃和学习率调度。事实上,你在实际案例中 95% 碰到的情况只需要tf.keras就足够了(和tf.data,见第 13 章)。现在来深入学习 TensorFlow 的低级 Python API。当你需要实现自定义损失函数、自定义标准、层、模型、初始化器、正则器、权重约束时,就需要低级 API 了。甚至有时需要全面控制训练过程,例如使用特殊变换或对约束梯度时。这一章就会讨论这些问题,还会学习如何使用 TensorFlow 的自动图生成特征提升自定义模型和训练算法。首先,先来快速学习下 TensorFlow。 笔记:TensorFlow 2.0(beta)是 2019 年六月发布的,相比前代更易使用。本书第一版使用的是 TF 1,这一版使用的是 TF 2。 Tensor...
13
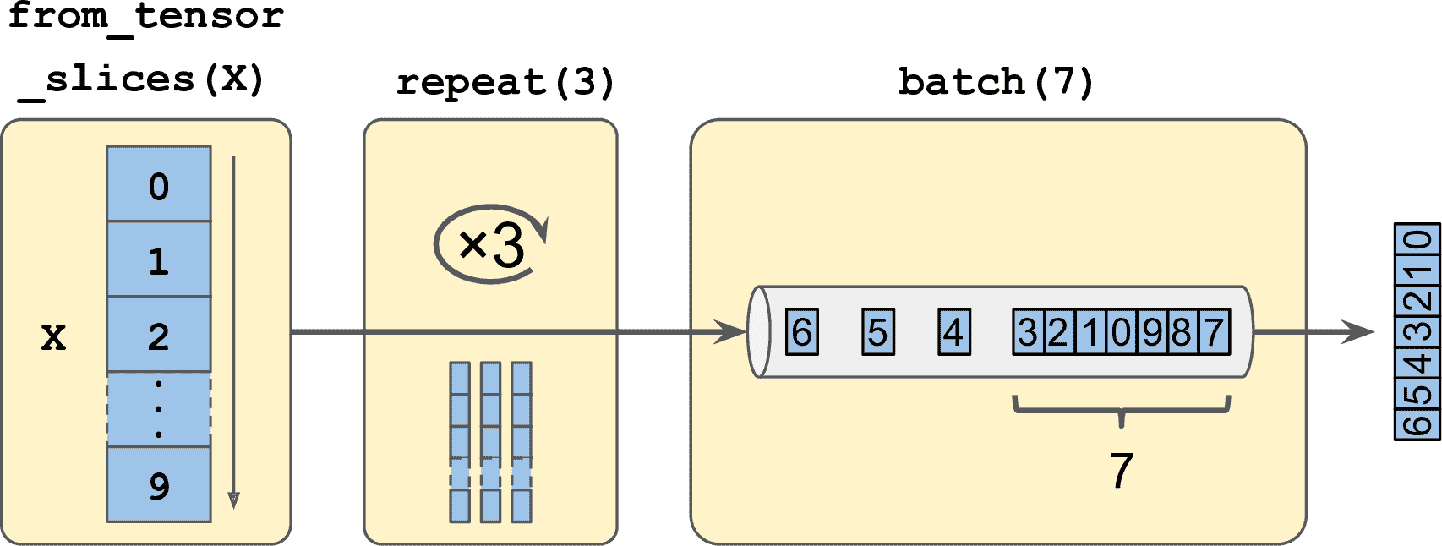
十三、使用 TensorFlow 加载和预处理数据 译者:@SeanCheney 目前为止,我们只是使用了存放在内存中的数据集,但深度学习系统经常需要在大数据集上训练,而内存放不下大数据集。其它的深度学习库通过对大数据集做预处理,绕过了内存限制,但 TensorFlow 通过 Data API,使一切都容易了:只需要创建一个数据集对象,告诉它去哪里拿数据,以及如何做转换就行。TensorFlow 负责所有的实现细节,比如多线程、队列、批次和预提取。另外,Data API 和tf.keras可以无缝配合! Data API 还可以从现成的文件(比如 CSV 文件)、固定大小的二进制文件、使用 TensorFlow 的 TFRecord 格式的文件(支持大小可变的记录)读取数据。TFRecord 是一个灵活高效的二进制格式,基于 Protocol Buffers(一个开源二进制格式)。Data API 还支持从 SQL 数据库读取数据。另外,许多开源插件也可以用来从各种数据源读取数据,包括谷歌的 BigQuery。 高效读取大数据集不是唯一的难点:数据还需要进行预处理,通常是归一化...
14
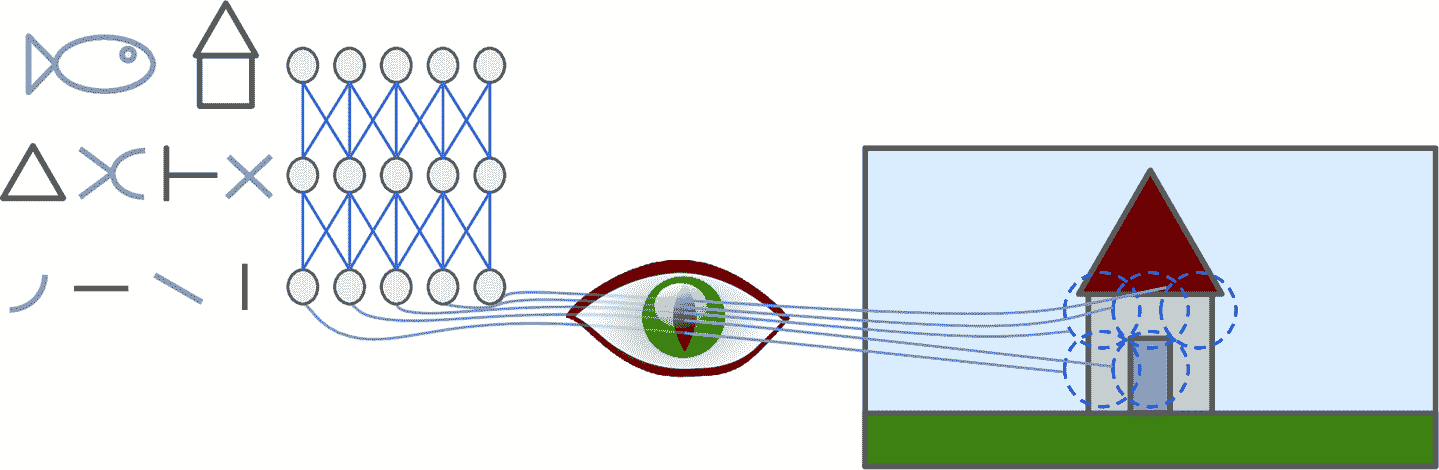
十四、使用卷积神经网络实现深度计算机视觉 译者:@SeanCheney 尽管 IBM 的深蓝超级计算机在 1996 年击败了国际象棋世界冠军加里·卡斯帕罗夫,但直到最近计算机才能从图片中认出小狗,或是识别出说话时的单词。为什么这些任务对人类反而毫不费力呢?原因在于,感知过程不属于人的自我意识,而是属于专业的视觉、听觉和其它大脑感官模块。当感官信息抵达意识时,信息已经具有高级特征了:例如,当你看一张小狗的图片时,不能选择不可能,也不能回避的小狗的可爱。你解释不了你是如何识别出来的:小狗就是在图片中。因此,我们不能相信主观经验:感知并不简单,要明白其中的原理,必须探究感官模块。 卷积神经网络(CNN)起源于人们对大脑视神经的研究,自从 1980 年代,CNN 就被用于图像识别了。最近几年,得益于算力提高、训练数据大增,以及第 11 章中介绍过的训练深度网络的技巧,CNN 在一些非常复杂的视觉任务上取得了超出人类表现的进步。CNN 支撑了图片搜索、无人驾驶汽车、自动视频分类,等等。另外,CNN 也不再限于视觉,比如:语音识别和自然语言处理,但这一章只介绍视觉应用。 本章会介绍 CNN...
15
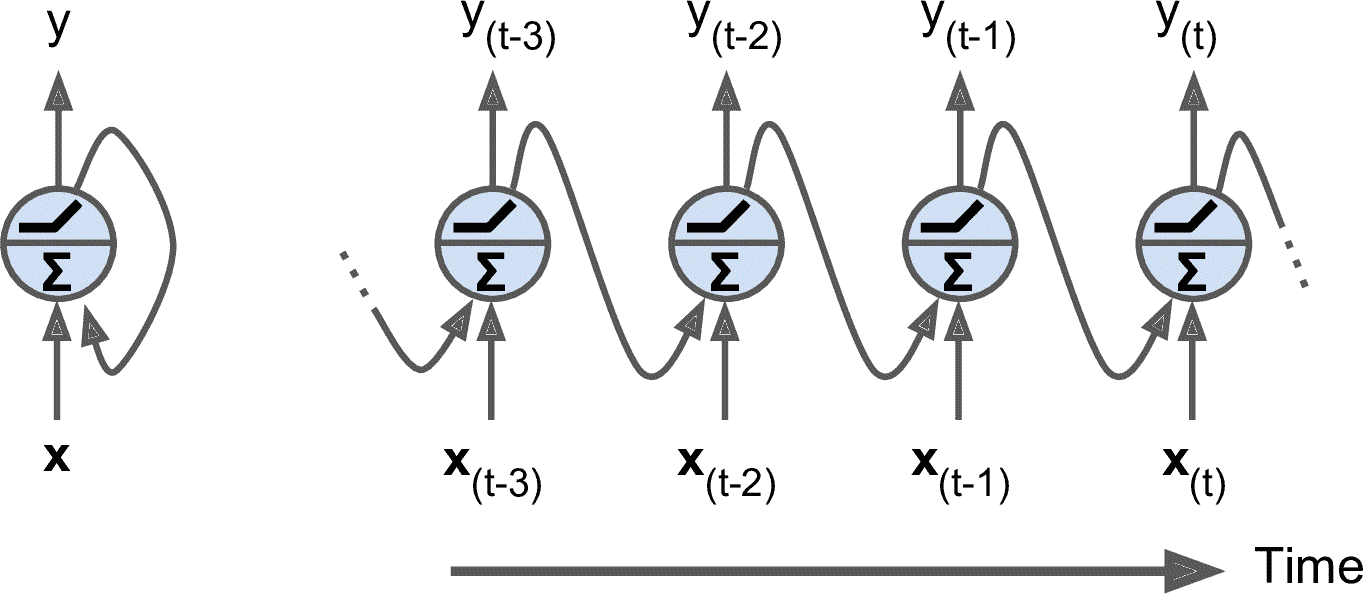
十五、使用 RNN 和 CNN 处理序列 译者:@SeanCheney 击球手击出垒球,外场手会立即开始奔跑,并预测球的轨迹。外场手追踪球,不断调整移动步伐,最终在观众的掌声中抓到它。无论是在听完朋友的话还是早餐时预测咖啡的味道,你时刻在做的事就是在预测未来。在本章中,我们将讨论循环神经网络,一类可以预测未来的网络(当然,是到某一点为止)。它们可以分析时间序列数据,比如股票价格,并告诉你什么时候买入和卖出。在自动驾驶系统中,他们可以预测行车轨迹,避免发生事故。更一般地说,它们可在任意长度的序列上工作,而不是截止目前我们讨论的只能在固定长度的输入上工作的网络。举个例子,它们可以将语句,文件,以及语音范本作为输入,应用在在自动翻译,语音到文本的自然语言处理应用中。 在本章中,我们将学习循环神经网络的基本概念,如何使用时间反向传播训练网络,然后用来预测时间序列。然后,会讨论 RNN 面对的两大难点: 不稳定梯度(换句话说,在第 11 章中讨论的梯度消失/爆炸),可以使用多种方法缓解,包括循环丢弃和循环层归一化。 有限的短期记忆,可以通过 LSTM 和 GRU 单元延长。...
16
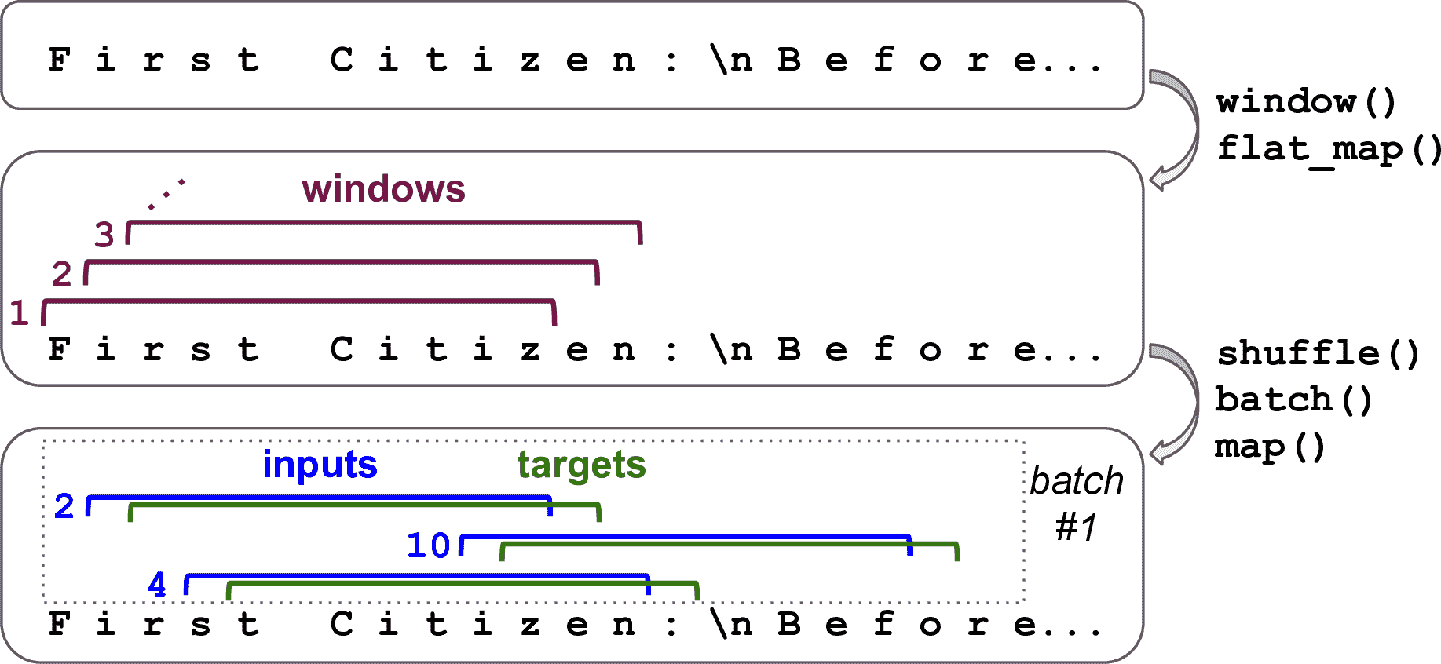
# 十六、使用 RNN 和注意力机制进行自然语言处理 > 译者:[@SeanCheney](https://www.jianshu.com/u/130f76596b02) 当阿兰·图灵在 1950 年设计[图灵机](https://links.jianshu.com/go?to=http%3A%2F%2Fcogprints.org%2F499%2F1%2Fturing.html)时,他的目标是用人的智商来衡量机器。他本可以用其它方法来测试,比如看图识猫、下棋、作曲或逃离迷宫,但图灵选择了一个语言任务。更具体的,他设计了一个聊天机器人,试图迷惑对话者将其当做真人。这个测试有明显的缺陷:一套硬编码的规则可以愚弄粗心人(比如,机器可以针对一些关键词,做出预先定义的模糊响应;机器人可以假装开玩笑或喝醉;或者可以通过反问侥幸过关),忽略了人类的多方面的智力(比如非语言交流,比如面部表情,或是学习动手任务)。但图灵测试强调了一个事实,语言能力是智人最重要的认知能力。我们能创建一台可以读写自然语言的机器吗? 自然语言处理的常用方法是循环神经网络。所以接下来会从字符 RNN 开始(...
17
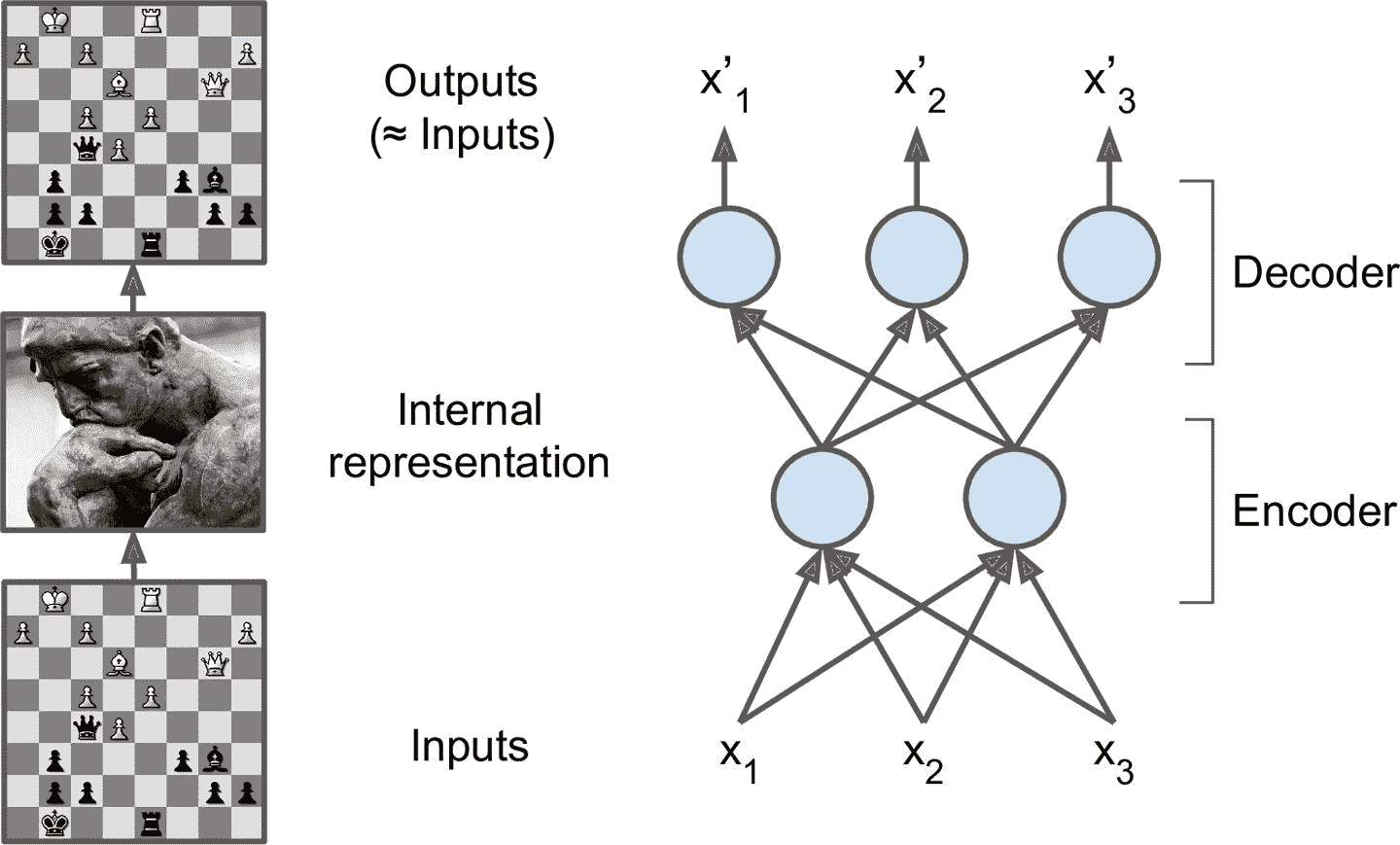
十七、使用自编码器和 GAN 做表征学习和生成式学习 译者:@SeanCheney 自编码器是能够在无监督(即,训练集是未标记)的情况下学习输入数据的紧密表征(叫做潜在表征或编码)的人工神经网络。这些编码通常具有比输入数据低得多的维度,使得自编码器对降维有用(参见第 8 章)。自编码器还可以作为强大的特征检测器,它们可以用于无监督的深度神经网络预训练(正如我们在第 11 章中讨论过的)。最后,一些自编码器是生成式模型:他们能够随机生成与训练数据非常相似的新数据。例如,您可以在脸图片上训练自编码器,然后可以生成新脸。但是生成出来的图片通常是模糊且不够真实。 相反,用对抗生成网络(GAN)生成的人脸可以非常逼真,甚至让人认为他们是真实存在的人。你可以去这个网址,这是用 StyleGAN 生成的人脸,自己判断一下(还可以去这里,看看 GAN 生成的卧室图片),GAN 现在广泛用于超清图片涂色,图片编辑,将草图变为照片,增强数据集,生成其它类型的数据(比如文本、音频、时间序列),找出其它模型的缺点并强化,等等。 自编码器和 GAN 都是无监督的,都可以学习紧密表征,都可以用作生成模型,...

18
十八、强化学习 译者:@SeanCheney 强化学习(RL)如今是机器学习的一大令人激动的领域,也是最老的领域之一。自从 1950 年被发明出来后,它被用于一些有趣的应用,尤其是在游戏(例如 TD-Gammon,一个西洋双陆棋程序)和机器控制领域,但是从未弄出什么大新闻。直到 2013 年一个革命性的发展:来自英国的研究者发起了 Deepmind 项目,这个项目可以学习去玩任何从头开始的 Atari 游戏,在多数游戏中,比人类玩的还好,它仅使用像素作为输入而没有使用游戏规则的任何先验知识。这是一系列令人惊叹的壮举中的第一个,并在 2016 年 3 月以他们的系统 AlphaGo 战胜了世界围棋冠军李世石而告终。从未有程序能勉强打败这个游戏的大师,更不用说世界冠军了。今天,RL 的整个领域正在沸腾着新的想法,其都具有广泛的应用范围。DeepMind 在 2014 被谷歌以超过 5 亿美元收购。 DeepMind 是怎么做到的呢?事后看来,原理似乎相当简单:他们将深度学习运用到强化学习领域,结果却超越了他们最疯狂的设想。在本章中,我们将首先解释强化学习是什么,以及它擅长于什么,然...
19
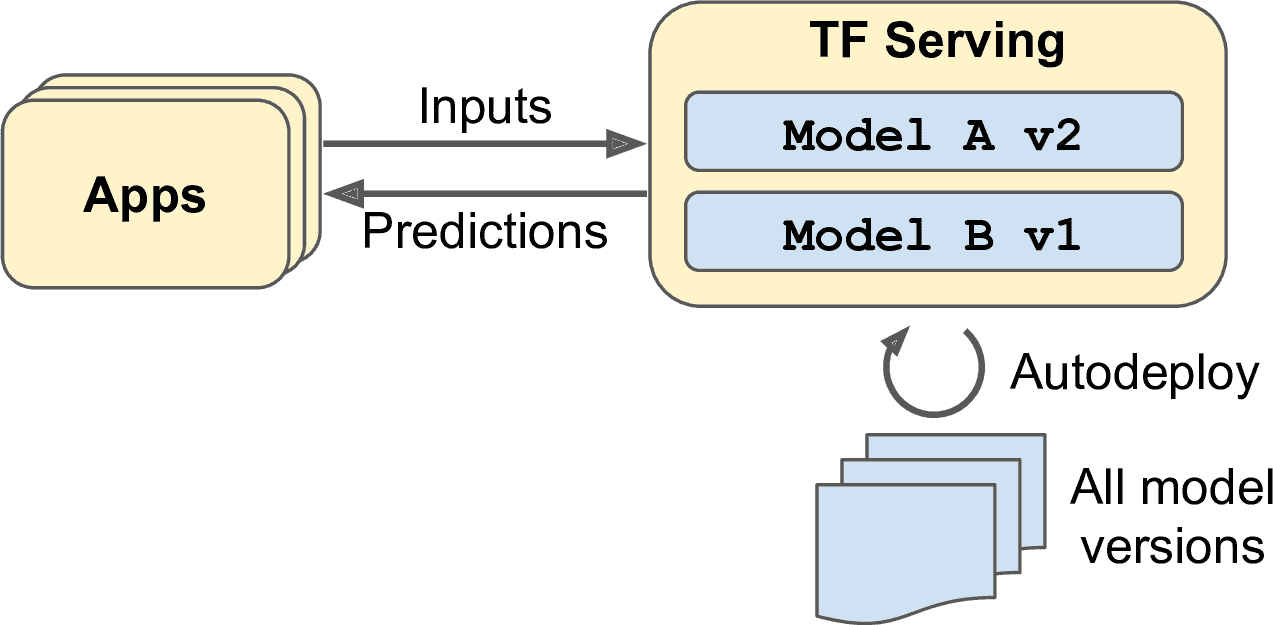
十九、规模化训练和部署 TensorFlow 模型 译者:@SeanCheney 有了能做出惊人预测的模型之后,要做什么呢?当然是部署生产了。这只要用模型运行一批数据就成,可能需要写一个脚本让模型每夜都跑着。但是,现实通常会更复杂。系统基础组件都可能需要这个模型用于实时数据,这种情况需要将模型包装成网络服务:这样的话,任何组件都可以通过 REST API 询问模型。随着时间的推移,你需要用新数据重新训练模型,更新生产版本。必须处理好模型版本,平稳地过渡到新版本,碰到问题的话需要回滚,也许要并行运行多个版本做 AB 测试。如果产品很成功,你的服务可能每秒会有大量查询,系统必须提升负载能力。提升负载能力的方法之一,是使用 TF Serving,通过自己的硬件或通过云服务,比如 Google Cloud API 平台。TF Serving 能高效服务化模型,优雅处理模型过渡,等等。如果使用云平台,还能获得其它功能,比如强大的监督工具。 另外,如果有很多训练数据和计算密集型模型,则训练时间可能很长。如果产品需要快速迭代,这么长的训练时间是不可接受的(例如,新闻推荐系统总是推荐上个星期的...

SUMMARY
Sklearn 与 TensorFlow 机器学习实用指南第二版 零、前言 一、机器学习概览 二、端到端的机器学习项目 三、分类 四、训练模型 五、支持向量机 六、决策树 七、集成学习和随机森林 八、降维 十、使用 Keras 搭建人工神经网络 十一、训练深度神经网络 十二、使用 TensorFlow 自定义模型并训练 十三、使用 TensorFlow 加载和预处理数据 十四、使用卷积神经网络实现深度计算机视觉 十五、使用 RNN 和 CNN 处理序列 十六、使用 RNN 和注意力机制进行自然语言处理 十七、使用自编码器和 GAN 做表征学习和生成式学习 十八、强化学习 十九、规模化训练和部署 TensorFlow 模型




