
JDBC
文章
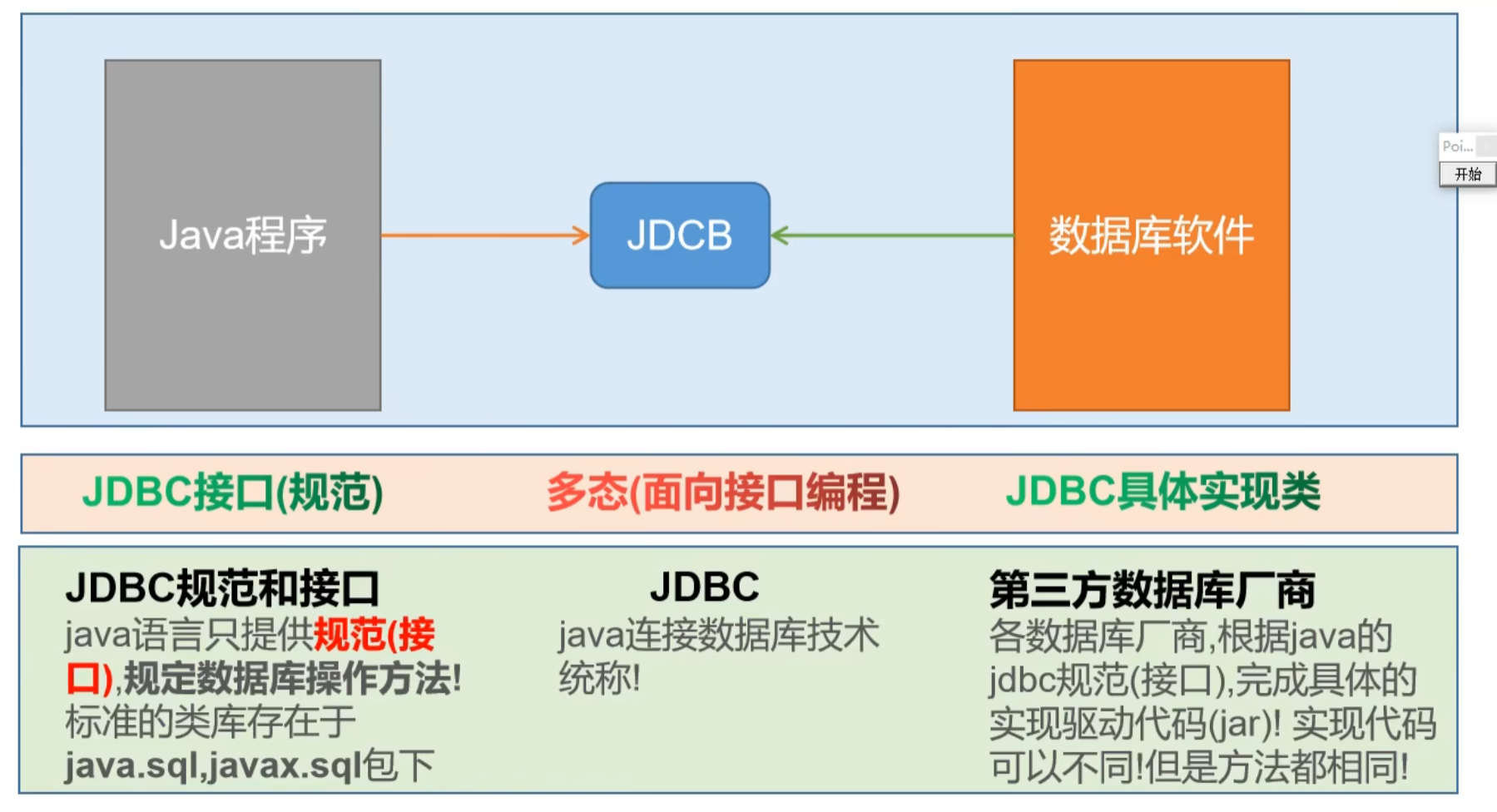
01 JDBC简介
1. 简介概述各个数据库厂商去实现这套接口,提供数据库驱动jar包我们可以使用这套接口(JDBC)编程,真正执行的代码是驱动jar包中的实现类 各数据库厂商使用相同的接口,Java代码不需要针对不同数据库分别开发。可随时替换底层数据库,访问数据库的Java代码基本不变。以后编写操作数据库的代码只需要面向JDBC(接口),操作哪儿个关系型数据库就需要导入该数据库的驱动包,如需要操作MySQL数据库,就需要再项目中导入MySQL数据库的驱动包。 jdbc的架构 数据库操作的层次 准备一个数据库:mysql JDBC数据库连接:JDBC定义了数据库操作的规范,数据库驱动实现了数据库操作的规范。 DataSource数据源/连接池。舔奶盖理论,当创建和销毁连接消耗了大量的性能,引进池化技术,创建连接池只释放连接、不销毁连接,实现对连接的复用。 数据库操作框架:SpringData、Mybatis。提供了对JDBC基本数据库操作的封装。 2. 核心类 DriverManager 将第三方尝试实现的驱动jar注册到程序中 可以根据数据库链接信息获取connection Co...
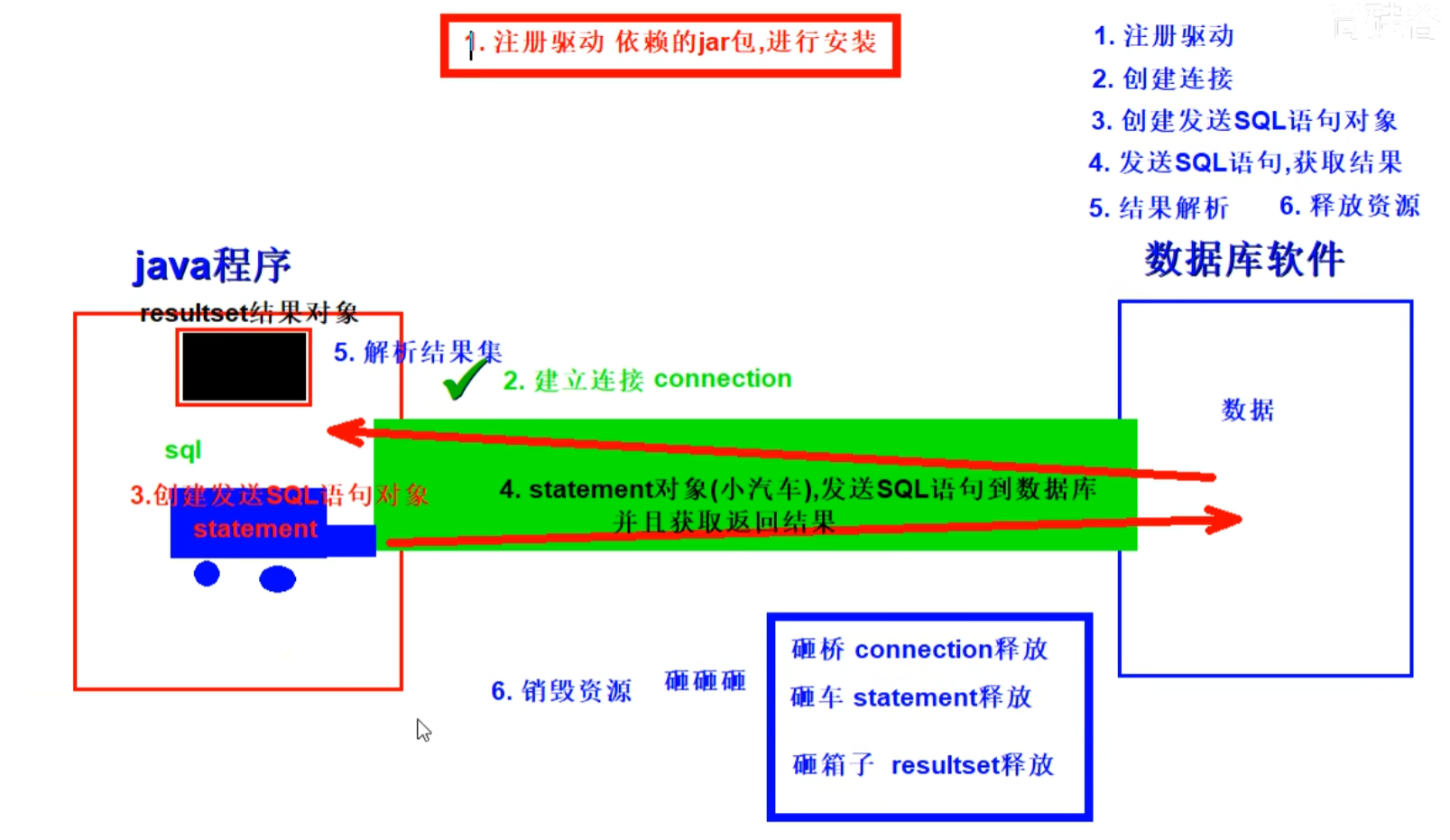
02 JDBC使用
基本步骤 1.注册驱动 准备数据库的建表语句 12345CREATE TABLE user ( id INT AUTO_INCREMENT, name VARCHAR(100), PRIMARY KEY(id)); 通过反射机制+静态代码块初始化数据库驱动。 通过反射的方式读取文件中的数据库驱动类路径,,方便外部化配置 使用静态代码块,在类加载的时候数据库初始化驱动只需要初始化一次,实现数据库驱动的初始化。 1234567891011121314151617181920//反射的方式try { Class.forName("com.mysql.jdbc.Driver"); } catch (ClassNotFoundException e) { e.printStackTrace();}//在无惨构造方法中通过静态代码块初始化了唯一的数据库驱动。public class Driver extends NonRegisteringDri...

03 批量操作
1 使用方法批量执行SQL语句批量执行 SQL 语句当需要成批插入或者更新记录时,可以采用 Java 的 批量 更新 机制,这一机制允许多条语句一次性提交给数据库批量处理。通常情况下比单独提交处理更有效率 JDBC 的批量处理语句包括下面三个方法: addBatch(String):添加需要批量处理的 SQL 语句或是参数; executeBatch():执行批量处理语句; clearBatch(): 清空缓存的数据 通常我们会遇到两种批量执行 SQL 语句的情况: 多条 SQL 语句的批量处理; 一个 SQL 语句的批量传参; 使用实例向数据表中插入20000条数据 实现层次一:使用 Statement123456Connection conn = JDBCUtils.getConnection();Statement st = conn.createStatement();for(int i = 1;i <= 20000;i++){ String sql = "insert into goods(name) values('name...

04 事务操作
1 事务操作数据库事务介绍事务:一组逻辑操作单元,使数据从一种状态变换到另一种状态。 事务处理(事务操作): 保证所有事务都作为一个工作单元来执行,即使出现了故障,都不能改变这种执行方式。当在一个事务中执行多个操作时,要么所有的事务都 被提交(commit),那么这些修改就永久地保存下来;要么数据库管理系统将放弃所作的所有修改,整个事务 回滚(rollback) 到最初状态。 为确保数据库中数据的一致性,数据的操纵应当是离散的成组的逻辑单元:当它全部完成时,数据的一致性可以保持,而当这个单元中的一部分操作失败,整个事务应全部视为错误,所有从起始点以后的操作应全部回退到开始状态。 JDBC 事务处理数据一旦提交,就不可回滚。 数据什么时候意味着提交? 当一个连接对象被创建时,默认情况下是自动提交事务:每次执行一个 SQL 语句时,如果执行成功,就会向数据库自动提交,而不能回滚。关闭数据库连接,数据就会自动的提交。 如果多个操作,每个操作使用的是自己单独的连接,则无法保证事务。即同一个事务的多个操作必须在同一个连接下。JDBC 程序中为了让多个 SQL 语句作为一个事务执行: 调用 ...

05 连接池
1 简介JDBC数据库连接池的必要性在使用开发基于数据库的 web 程序时,传统的模式基本是按以下步骤: 在主程序(如 servlet、beans )中建立数据库连接 进行 sql 操作 断开数据库连接 这种模式开发,存在的问题: 普通的 JDBC 数据库连接使用 DriverManager 来获取,每次向数据库建立连接的时候都要将 Connection 加载到内存中,再验证用户名和密码(得花费0.05s~1s的时间)。需要数据库连接的时候,就向数据库要求一个,执行完成后再断开连接。这样的方式将会消耗大量的资源和时间。数据库的连接资源并没有得到很好的重复利用。 若同时有几百人甚至几千人在线,频繁的进行数据库连接操作将占用很多的系统资源,严重的甚至会造成服务器的崩溃。 对于每一次数据库连接,使用完后都得断开。 否则,如果程序出现异常而未能关闭,将会导致数据库系统中的内存泄漏,最终将导致重启数据库。(回忆:何为 Java 的内存泄漏?)这种开发不能控制被创建的连接对象数,系统资源会被毫无顾及的分配出去,如连接过多,也可能导致内存泄漏,服务器崩溃。 数据库连接池技术为解决传统开发中...

06 操作封装
1 泛型方法封装JDBCUtil反射+线程变量实现数据库连接和事务控制 单例化datasource。无需重复创建 使用property从配置文件中加载配置 创建druid线程池复用连接,提升查询效率。 利用线程变量获取连接信息,确保一个线程中的多个方法可以获取同一个connection 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253package org.example.dao;import com.alibaba.druid.pool.DruidDataSourceFactory;import javax.sql.DataSource;import java.io.IOException;import java.io.InputStream;import java.sql.Connection;import java.sql.SQLException;import java.util.Properties;public class...




