
MySQL
文章

附录4 MySQL事务管理
MySQL事务管理 参考文献 Mysql并发控制 本章主要讲了MySQL的事务管理,即MySQL的并发控制,MySQL在并发过程中如何进行同步,即MySQL保证事物的原子性、隔离性、一致性、持久性的方法。也属于并发机制的一部分。 4 多级锁协议封锁粒度MySQL 各存储引擎使用了三种类型(级别)的锁定机制:表级锁定,行级锁定和页级锁定。 表级锁定(table-level)表级别的锁定是 MySQL 各存储引擎中最大颗粒度的锁定机制。该锁定机制最大的特点是实现逻辑非常简单,带来的系统负面影响最小。所以获取锁和释放锁的速度很快。由于表级锁一次会将整个表锁定,所以可以很好的避免困扰我们的死锁问题。当然,锁定颗粒度大所带来最大的负面影响就是出现锁定资源争用的概率也会最高,致使并发度大打折扣。使用表级锁定的主要是 MyISAM,MEMORY,CSV等一些非事务性存储引擎。 行级锁定(row-level)行级锁定最大的特点就是锁定对象的颗粒度很小,也是目前各大数据库管理软件所实现的锁定颗粒度最小的。由于锁定颗粒度很小,所以发生锁定资源争用的概率也最小,能够给予应用程序尽可能大的并...

附录5 MySQL连接查询
5 JOIN连接查询 参考文献 MySQL的JOIN用法 数据库实例 1234567891011121314151617181920212223242526272829303132333435 1 CREATE TABLE t_blog( 2 id INT PRIMARY KEY AUTO_INCREMENT, 3 title VARCHAR(50), 4 typeId INT 5 ); 6 SELECT * FROM t_blog; 7 +----+-------+--------+ 8 | id | title | typeId | 9 +----+-------+--------+10 | 1 | aaa | 1 |11 | 2 | bbb | 2 |12 | 3 | ccc | 3 |13 | 4 | ddd | 4 |14 | 5 | eee | 4 ...
附录6 MySQL分库分表
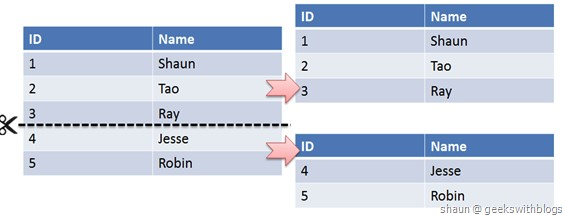
MySQL分库分表和主从分离1 概述分库分表的原因当一张表的数据达到几千万时,查询一次所花的时间会变多,如果有联合查询的话,有可能会死在那儿了。分表的目的就在于此,减小数据库的负担,缩短查询时间。 用户请求量太大。因为单服务器TPS,内存,IO都是有限的。解决方法:分散请求到多个服务器上; 其实用户请求和执行一个sql查询是本质是一样的,都是请求一个资源,只是用户请求还会经过网关,路由,http服务器等。 单库太大。单个数据库处理能力有限;单库所在服务器上磁盘空间不足;单库上操作的IO瓶颈 解决方法:切分成更多更小的库 单表太大。CRUD都成问题;索引膨胀,查询超时。解决方法:切分成多个数据集更小的表。 分库分表的形式 单库单表。单库单表是最常见的数据库设计,例如,有一张用户(user)表放在数据库db中,所有的用户都可以在db库中的user表中查到。 单库多表。随着用户数量的增加,user表的数据量会越来越大,当数据量达到一定程度的时候对user表的查询会渐渐的变慢,从而影响整个DB的性能。如果使用mysql, 还有一个更严重的问题是,当需要添加一列的时候,mysq...

附录7 MySQL并发机制
1 并发机制 什么是并发,并发与多线程有什么关系? 先从广义上来说,或者从实际场景上来说. 高并发通常是海量用户同时访问(比如:12306买票、淘宝的双十一抢购),如果把一个用户看做一个线程的话那么并发可以理解成多线程同时访问,高并发即海量线程同时访问。(ps:我们在这里模拟高并发可以for循环多个线程即可) 从代码或数据的层次上来说。多个线程同时在一条相同的数据上执行多个数据库操作。 2 如何避免并发冲突 参考文献 锁与并发 积极并发(乐观锁)积极并发(乐观并发、乐观锁):无论何时从数据库请求数据,数据都会被读取并保存到应用内存中。数据库级别没有放置任何显式锁。数据操作会按照数据层接收到的先后顺序来执行。 积极并发本质就是允许冲突发生,然后在代码本身采取一种合理的方式去解决这个并发冲突,常见的方式有: 忽略冲突强制更新:数据库会保存最后一次更新操作(以更新为例),会损失很多用户的更新操作。 部分更新:允许所有的更改,但是不允许更新完整的行,只有特定用户拥有的列更新了。这就意味着,如果两个用户更新相同的记录但却不同的列,那么这两个更新都会成功,而且来自这两个用...
附录8 MySQL一致哈希
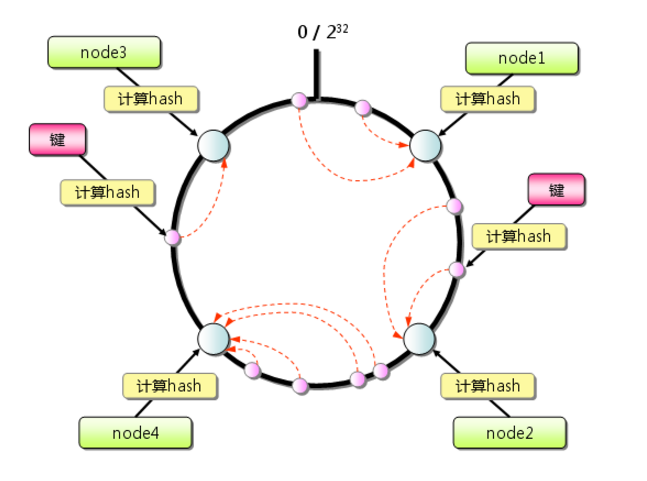
一致性哈希算法一致性Hash算法背景一致性哈希算法在1997年由麻省理工学院的Karger等人在解决分布式Cache中提出的,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得DHT可以在P2P环境中真正得到应用。 但现在一致性hash算法在分布式系统中也得到了广泛应用,研究过memcached缓存数据库的人都知道,memcached服务器端本身不提供分布式cache的一致性,而是由客户端来提供,具体在计算一致性hash时采用如下步骤: 首先求出memcached服务器(节点)的哈希值,并将其配置到0~232的圆(continuum)上。然后采用同样的方法求出存储数据的键的哈希值,并映射到相同的圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232仍然找不到服务器,就会保存到第一台memcached服务器上。 从上图的状态中添加一台memcached服务器。余数分布式算法由于保存键的服务器会发生巨大变化而影响缓存的命中率,但Consistent Has...




