
sklearn-cookbook-zh
文章
0 概述
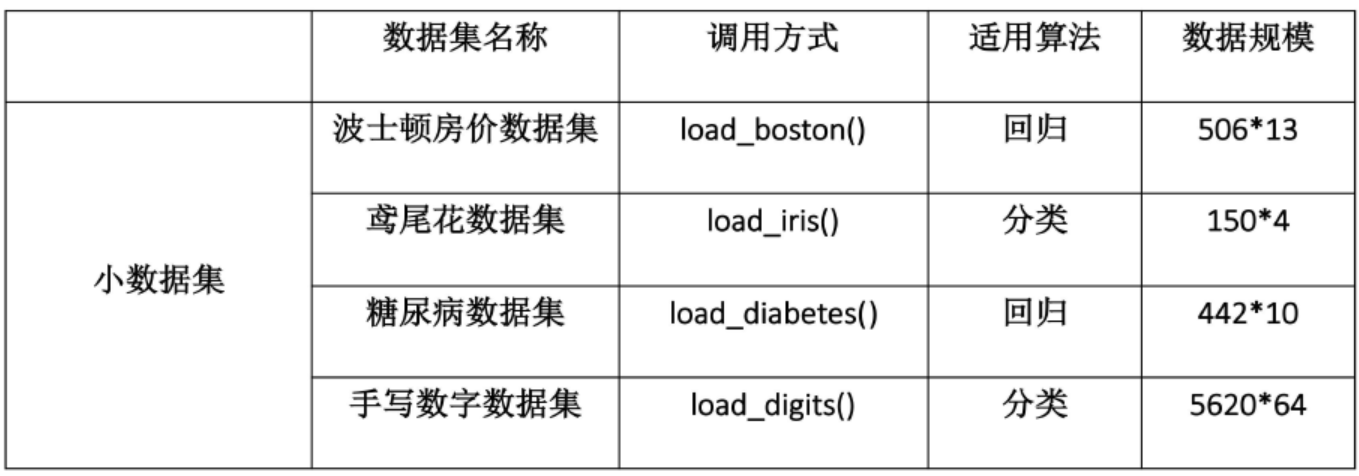
sklearn 概述参考文献 快速入门教程 python-sklearn使用教程 机器学习的一般流程 获取数据 sklearn.datasets 处理数据 feature_extraction feature_selection 训练模型 sklearn.model_selection 评估模型 estimator(score=[‘’])score参数 sklearn.metrics 使用模型 本文我们将依据传统机器学习的流程,看看在每一步流程中都有哪些常用的函数以及它们的用法是怎么样的。希望你看完这篇文章可以最为快速的开始你的学习任务。 1 获取数据1.1 导入sklearn数据集 sklearn中包含了大量的优质的数据集,在你学习机器学习的过程中,你可以通过使用这些数据集实现出不同的模型,从而提高你的动手实践能力,同时这个过程也可以加深你对理论知识的理解和把握。(这一步我也亟需加强,一起加油!^-^) 首先呢,要想使用sklearn中的数据集,必须导入datasets模块: 1from sklearn import datasets ...

0.1 fit&transform
fit&transform说明1 概述 fit和transform没有任何关系,仅仅是数据处理的两个不同环节,之所以出来fit_transform这个函数名,仅仅是为了写代码方便,会高效一点。 sklearn里的封装好的各种算法使用前都要fit,fit相对于整个代码而言,为后续API服务。fit之后,然后调用各种API方法,transform只是其中一个API方法,所以当你调用transform之外的方法,也必须要先fit。 fit原义指的是安装、使适合的意思,其实有点train的含义,但是和train不同的是,它并不是一个训练的过程,而是一个适配的过程,过程都是确定的,最后得到一个可用于转换的有价值的信息。 2 使用2.1 数据预处理中方法12fit(): Method calculates the parameters μ and σ and saves them as internal objects.解释:简单来说,就是求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性。 12transform(): Method using these c...
1 模型预处理
# 第一章 模型预处理 > 作者:Trent Hauck > 译者:[muxuezi](https://muxuezi.github.io/posts/1-premodel-workflow.html) > 协议:[CC BY-NC-SA 4.0](http://creativecommons.org/licenses/by-nc-sa/4.0/) 本章包括以下主题: 1. [从外部源获取样本数据](getting-sample-data-from-external-sources.html) 1. [创建试验样本数据](creating-sample-data-for-toy-analysis.html) 1. [把数据调整为标准正态分布](scaling-data-to-the-standard-normal.html) 1. [用阈值创建二元特征](creating-binary-features-through-thresholding.html) 1. [分类变量处理](working-with-categorical-variables.html) 1....
2 处理线性模型
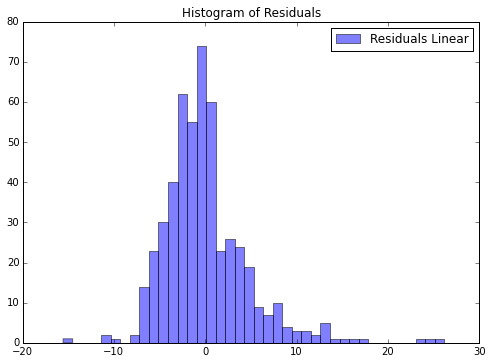
第二章 处理线性模型 作者:Trent Hauck 译者:muxuezi 协议:CC BY-NC-SA 4.0 本章包括以下主题: 线性回归模型 评估线性回归模型 用岭回归弥补线性回归的不足 优化岭回归参数 LASSO正则化 LARS正则化 用线性方法处理分类问题——逻辑回归 贝叶斯岭回归 用梯度提升回归从误差中学习 简介线性模型是统计学和机器学习的基础。很多方法都利用变量的线性组合描述数据之间的关系。通常都要花费很大精力做各种变换,目的就是为了让数据可以描述成一种线性组合形式。 本章,我们将从最简单的数据直线拟合模型到分类模型,最后介绍贝叶斯岭回归。 2.1 线性回归模型现在,我们来做一些建模!我们从最简单的线性回归(Linear regression)开始。线性回归是最早的也是最基本的模型——把数据拟合成一条直线。 Getting readyboston数据集很适合用来演示线性回归。boston数据集包含了波士顿地区的房屋价格中位数。还有一些可能会影响房价的因素,比如犯罪率(crime rate)。 首先,让我们加载数据: 12from sklearn ...
3 使用距离向量构建模型
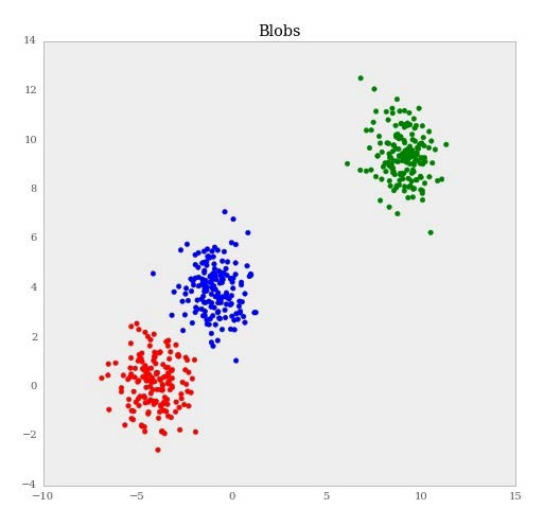
第三章 使用距离向量构建模型 作者:Trent Hauck 译者:飞龙 协议:CC BY-NC-SA 4.0 这一章中,我们会涉及到聚类。聚类通常和非监督技巧组合到一起。这些技巧假设我们不知道结果变量。这会使结果模糊,以及实践客观。但是,聚类十分有用。我们会看到,我们可以使用聚类,将我们的估计在监督设置中“本地化”。这可能就是聚类非常高效的原因。它可以处理很大范围的情况,通常,结果也不怎么正常。 这一章中我们会浏览大量应用,从图像处理到回归以及离群点检测。通过这些应用,我们会看到聚类通常可以通过概率或者优化结构来观察。不同的解释会导致不同的权衡。我们会看到,如何训练模型,以便让工具尝试不同模型,在面对聚类问题的时候。 3.1 使用 KMeans 对数据聚类聚类是个非常实用的技巧。通常,我们在采取行动时需要分治。考虑公司的潜在客户列表。公司可能需要将客户按类型分组,之后为这些分组划分职责。聚类可以使这个过程变得容易。 KMeans 可能是最知名的聚类算法之一,并且也是最知名的无监督学习技巧之一。 准备首先,让我们看一个非常简单的聚类,之后我们再讨论 KMeans 如何工作...
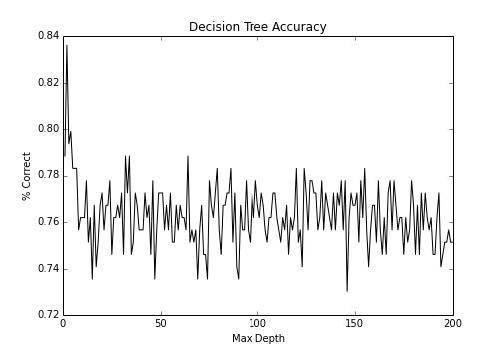
4 使用 scikit-learn 对数据分类
第四章 使用 scikit-learn 对数据分类 作者:Trent Hauck 译者:飞龙 协议:CC BY-NC-SA 4.0 分类在大量语境下都非常重要。例如,如果我们打算自动化一些决策过程,我们可以利用分类。在我们需要研究诈骗的情况下,有大量的事务,人去检查它们是不实际的。所以,我们可以使用分类都自动化这种决策。 4.1 使用决策树实现基本的分类这个秘籍中,我们使用决策树执行基本的分类。它们是非常不错的模型,因为它们很易于理解,并且一旦训练完成,评估就很容易。通常可以使用 SQL 语句,这意味着结果可以由许多人使用。 准备这个秘籍中,我们会看一看决策树。我喜欢将决策树看做基类,大量的模型从中派生。它是个非常简单的想法,但是适用于大量的情况。 首先,让我们获取一些分类数据,我们可以使用它来练习: 123>>> from sklearn import datasets >>> X, y = datasets.make_classification(n_samples=1000, n_features=3, ...
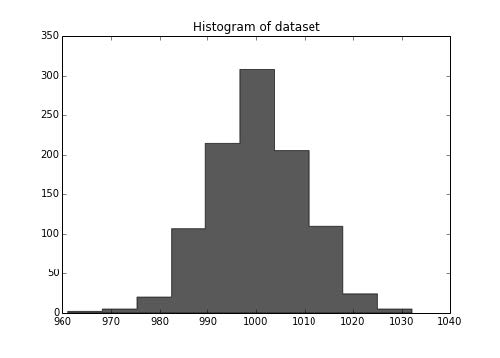
5 模型后处理
第五章 模型后处理 作者:Trent Hauck 译者:飞龙 协议:CC BY-NC-SA 4.0 5.1 K-fold 交叉验证这个秘籍中,我们会创建交叉验证,它可能是最重要的模型后处理验证练习。我们会在这个秘籍中讨论 k-fold 交叉验证。有几种交叉验证的种类,每个都有不同的随机化模式。K-fold 可能是一种最熟知的随机化模式。 准备我们会创建一些数据集,之后在不同的在不同的折叠上面训练分类器。值得注意的是,如果你可以保留一部分数据,那是最好的。例如,我们拥有N = 1000的数据集,如果我们保留 200 个数据点,之后使用其他 800 个数据点之间的交叉验证,来判断最佳参数。 工作原理首先,我们会创建一些伪造数据,之后测试参数,最后,我们会看看结果数据集的大小。 1234>>> N = 1000 >>> holdout = 200>>> from sklearn.datasets import make_regression >>> X, y = make_regression(1000...

SUMMARY
Scikit-learn 秘籍 第一章 模型预处理 第二章 处理线性模型 第三章 使用距离向量构建模型 第四章 使用 scikit-learn 对数据分类 第五章 模型后处理




