

zfore
zfore强制为gzip格式的压缩文件添加.gz后缀 补充说明zfore命令 强制为gzip格式的压缩文件添加“.gz”后缀。 语法1zfore(参数) 参数文件列表:指定要添加“.gz”后缀的gzip压缩文件。

zcat
zcat显示压缩包中文件的内容 补充说明zcat命令 用于不真正解压缩文件,就能显示压缩包中文件的内容的场合。 语法1zcat(选项)(参数) 选项1234567891011-S:指定gzip格式的压缩包的后缀。当后缀不是标准压缩包后缀时使用此选项;-c:将文件内容写到标注输出;-d:执行解压缩操作;-l:显示压缩包中文件的列表;-L:显示软件许可信息;-q:禁用警告信息;-r:在目录上执行递归操作;-t:测试压缩文件的完整性;-V:显示指令的版本信息;-l:更快的压缩速度;-9:更高的压缩比。 参数文件:指定要显示其中文件内容的压缩包。

zipinfo
zipinfo用来列出压缩文件信息 补充说明zipinfo命令 用来列出压缩文件信息。执行zipinfo指令可得知zip压缩文件的详细信息。 语法1zipinfo(选项)(参数) 选项123456789101112-1:只列出文件名称;-2:此参数的效果和指定“-1”参数类似,但可搭配“-h”,“-t”和“-z”参数使用;-h:只列出压缩文件的文件名称;-l:此参数的效果和指定“-m”参数类似,但会列出原始文件的大小而非每个文件的压缩率;-m:此参数的效果和指定“-s”参数类似,但多会列出每个文件的压缩率;-M:若信息内容超过一个画面,则采用类似more指令的方式列出信息;-s:用类似执行“ls-l”指令的效果列出压缩文件内容;-t:只列出压缩文件内所包含的文件数目,压缩前后的文件大小及压缩率;-T:将压缩文件内每个文件的日期时间用年,月,日,时,分,秒的顺序列出;-v:详细显示压缩文件内每一个文件的信息;-x<范本样式>:不列出符合条件的文件的信息;-z:如果压缩文件内含有注释,就将注释显示出来。 参数文件:指定zip格式的压缩包。

zipsplit
zipsplit将较大的zip压缩包分割成各个较小的压缩包 补充说明zipsplit命令 用于将较大的“zip”压缩包分割成各个较小的“zip”压缩包。 语法1zipsplit(选项)(参数) 选项123-n:指定分割后每个zip文件的大小;-t:报告将要产生的较小的zip文件的大小;-b:指定分割后的zip文件的存放位置。 参数文件:指定要分割的zip压缩包。

znew
znew将.Z压缩包重新转化为gzip命令压缩的.gz压缩包 补充说明znew命令 用于将使用compress命令压缩的“.Z”压缩包重新转化为使用gzip命令压缩的“.gz”压缩包。 语法1znew(选项)(参数) 选项123456-f:# 强制执行转换操作,即是目标“.gz”已经存在;-t:# 删除原文件前测试新文件;-v:# 显示文件名和每个文件的压缩比;-9:# 食用油花的压缩比,速度较慢;-P:# 使用管道完成转换操作,以降低磁盘空间使用;-K:# 当“.Z”文件比“.gz”文件小时,保留“.Z”文件。 参数文件:指定compress指令压缩生成的“.Z”压缩包。
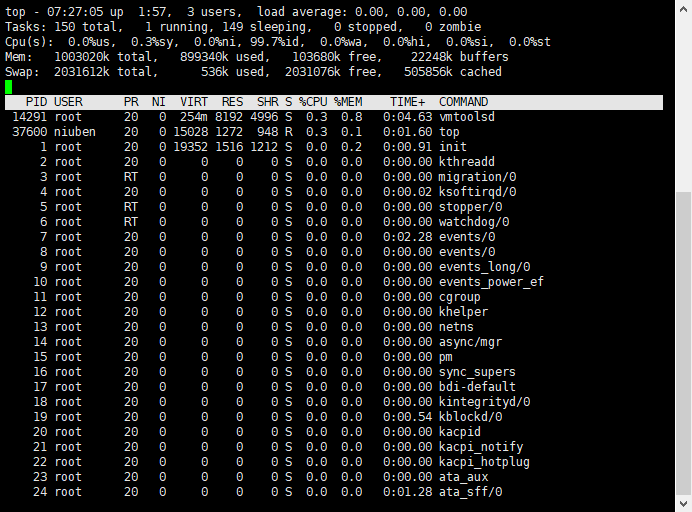
top系统状态
top查看系统状态 参考文献 https://www.cnblogs.com/niuben/p/12017242.html 1 说明第一行,任务队列信息,同 uptime 命令的执行结果 系统时间:07:27:05 运行时间:up 1:57 min, 当前登录用户: 3 user 负载均衡(uptime) load average: 0.00, 0.00, 0.00 average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。 load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了 第二行,Tasks — 任务(进程) 总进程:150 total, 运行:1 running, 休眠:149 sleeping, 停止: 0 stopped, 僵尸进程: 0 zombie 第三行,cpu状态信息 0.0%us【user space】— 用户空间占用CPU的百分比。 0.3%sy【sysctl】— 内核空间占用CPU的百分比。 0.0%ni【】— 改变过...
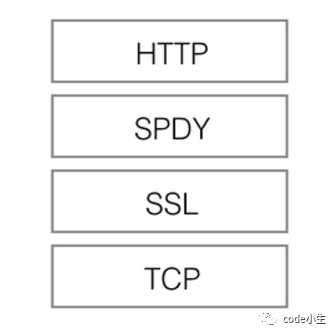
2.7 应用层-HTTP2.0
0 概述HTTP 2.0是在SPDY(An experimental protocol for a faster web, The Chromium Projects)基础上形成的下一代互联网通信协议。HTTP/2 的目的是通过支持请求与响应的多路复用来较少延迟,通过压缩HTTPS首部字段将协议开销降低,同时增加请求优先级和服务器端推送的支持。 2012年google如一声惊雷提出了SPDY的方案,优化了HTTP1.X的请求延迟,解决了HTTP1.X的安全性,具体如下: 降低延迟,针对HTTP高延迟的问题,SPDY优雅的采取了多路复用(multiplexing)。多路复用通过多个请求stream共享一个tcp连接的方式,解决了HOL blocking的问题,降低了延迟同时提高了带宽的利用率。 请求优先级(request prioritization)。多路复用带来一个新的问题是,在连接共享的基础之上有可能会导致关键请求被阻塞。SPDY允许给每个request设置优先级,这样重要的请求就会优先得到响应。比如浏览器加载首页,首页的html内容应该优先展示,之后才是各种静态...
一次HTTP请求的过程
过程概览 对www.baidu.com这个网址进行DNS域名解析,得到对应的IP地址 根据这个IP,找到对应的服务器,发起TCP的三次握手 建立TCP连接后发起HTTP请求 服务器响应HTTP请求,浏览器得到html代码 浏览器解析html代码,并请求html代码中的资源(如js、css图片等)(先得到html代码,才能去找这些资源) 浏览器对页面进行渲染呈现给用户 注:1.DNS域名解析采用的是递归查询的方式,过程是,先去找DNS缓存->缓存找不到就去找根域名服务器->根域名又会去找下一级,这样递归查找之后,找到了,给我们的web浏览器2.为什么HTTP协议要基于TCP来实现? TCP是一个端到端的可靠的面相连接的协议,HTTP基于传输层TCP协议不用担心数据传输的各种问题(当发生错误时,会重传)3.最后一步浏览器是如何对页面进行渲染的? a)解析html文件构成 DOM树,b)解析CSS文件构成渲染树, c)边解析,边渲染 , d)JS 单线程运行,JS有可能修改DOM结构,意味着JS执行完成前,后续所有资源的下载是没有必要的,所以JS是单线程,会阻塞...
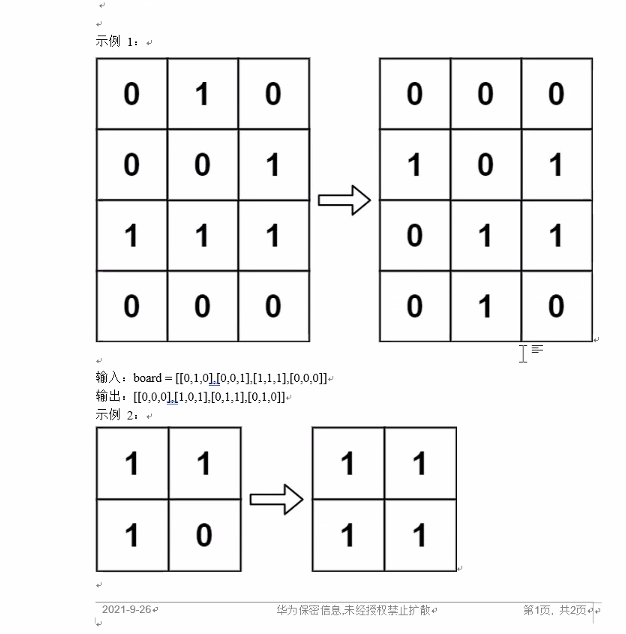
huawei
给定一个包含 m × n 个格子的面板,每一个格子都可以看成是一个细胞。每个细胞都具有一个初始状态:1 即为活细胞(live),或 0 即为死细胞(dead)。每个细胞与其八个相邻位置(水平,垂直,对角线)的细胞都遵循以下四条生存定律: 如果活细胞周围八个位置的活细胞数少于两个,则该位置活细胞死亡;如果活细胞周围八个位置有两个或三个活细胞,则该位置活细胞仍然存活;如果活细胞周围八个位置有超过三个活细胞,则该位置活细胞死亡;如果死细胞周围正好有三个活细胞,则该位置死细胞复活;下一个状态是通过将上述规则同时应用于当前状态下的每个细胞所形成的,其中细胞的出生和死亡是同时发生的。给你 m x n 网格面板 board 的当前状态,返回下一个状态。 示例 1: 输入:board = [[0,1,0],[0,0,1],[1,1,1],[0,0,0]]输出:[[0,0,0],[1,0,1],[0,1,1],[0,1,0]]示例 2: 输入:board = [[1,1],[1,0]]输出:[[1,1],[1,1]] 提示: m == board.leng...

huawei2
给你一个字符串 s 和一个字符串数组 dictionary 作为字典,找出并返回字典中最长的字符串,该字符串可以通过删除 s 中的某些字符得到。 如果答案不止一个,返回长度最长且字典序最小的字符串。如果答案不存在,则返回空字符串。 示例 1: 输入:s = “abpcplea”, dictionary = [“ale”,”apple”,”monkey”,”plea”]输出:”apple”示例 2: 输入:s = “abpcplea”, dictionary = [“a”,”b”,”c”]输出:”a” 提示: 1 <= s.length <= 10001 <= dictionary.length <= 10001 <= dictionary[i].length <= 1000s 和 dictionary[i] 仅由小写英文字母组成 class Solution { public String findLongestWord(String s,...




