

5.0-chinese
第5章 C++内存模型和原子类型操作本章主要内容 C++11内存模型详解 标准库提供的原子类型 使用各种原子类型 原子操作实现线程同步功能 C++11标准中,有一个十分重要特性,常被程序员们所忽略。它不是一个新语法特性,也不是新工具,它就是多线程(感知)内存模型。内存模型没有明确的定义基本部件应该如何工作的话,之前介绍的那些工具就无法正常工作。那为什么大多数程序员都没有注意到它呢?当你使用互斥量保护你的数据和条件变量,或者是“期望”上的信号事件时,对于互斥量为什么能起到这样作用,大多数人不会去关心。只有当你试图去“接触硬件”,你才能详尽的了解到内存模型是如何起作用的。 C++是一个系统级别的编程语言,标准委员会的目标之一就是不需要比C++还要底层的高级语言。C++应该向程序员提供足够的灵活性,无障碍的去做他们想要做的事情;当需要的时候,可以让他们“接触硬件”。原子类型和原子操作就允许他们“接触硬件”,并提供底层级别的同步操作,通常会将常规指令数缩减到1~2个CPU指令。 本章,我们将讨论内存模型的基本知识,而后再了解一下原子类型和操作,最后了解与原子类型操作相关的各种同步。这...
5.1-chinese
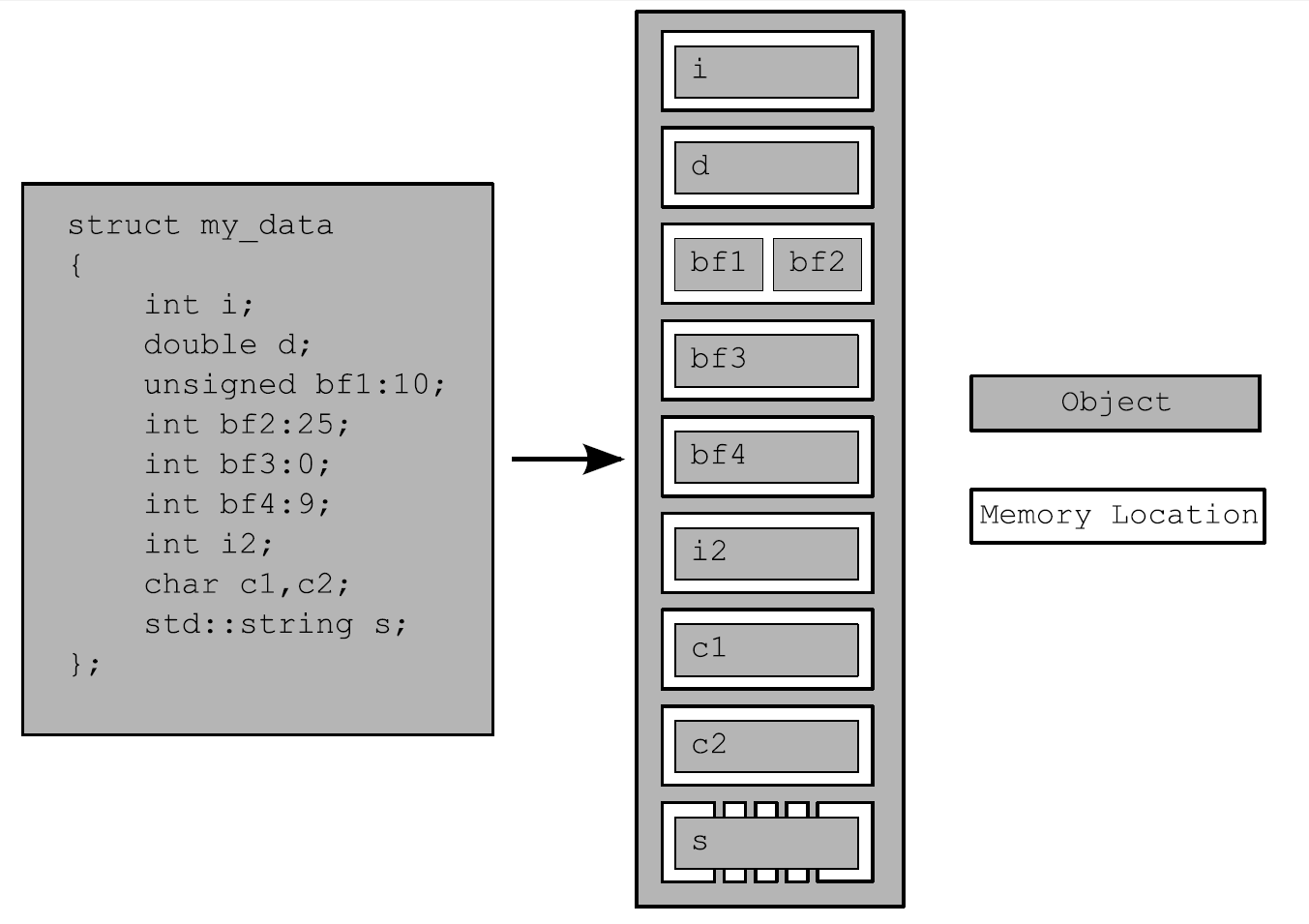
5.1 内存模型基础这里从两方面来讲内存模型:一方面是基本结构,这与事务在内存中是怎样布局的有关;另一方面就是并发。对于并发基本结构很重要,特别是在低层原子操作。所以我将会从基本结构讲起。C++中它与所有的对象和内存位置有关。 5.1.1 对象和内存位置在一个C++程序中的所有数据都是由对象(objects)构成。这不是说你可以创建一个int的衍生类,或者是基本类型中存在有成员函数,或是像在Smalltalk和Ruby语言下讨论程序那样——“一切都是对象”。“对象”仅仅是对C++数据构建块的一个声明。C++标准定义类对象为“存储区域”,但对象还是可以将自己的特性赋予其他对象,比如,其类型和生命周期。 像int或float这样的对象就是简单基本类型;当然,也有用户定义类的实例。一些对象(比如,数组,衍生类的实例,特殊(具有非静态数据成员)类的实例)拥有子对象,但是其他对象就没有。 无论对象是怎么样的一个类型,一个对象都会存储在一个或多个内存位置上。每一个内存位置不是一个标量类型的对象,就是一个标量类型的子对象,比如,unsigned short、my_class*或序列中的相邻位域...
5.3-chinese
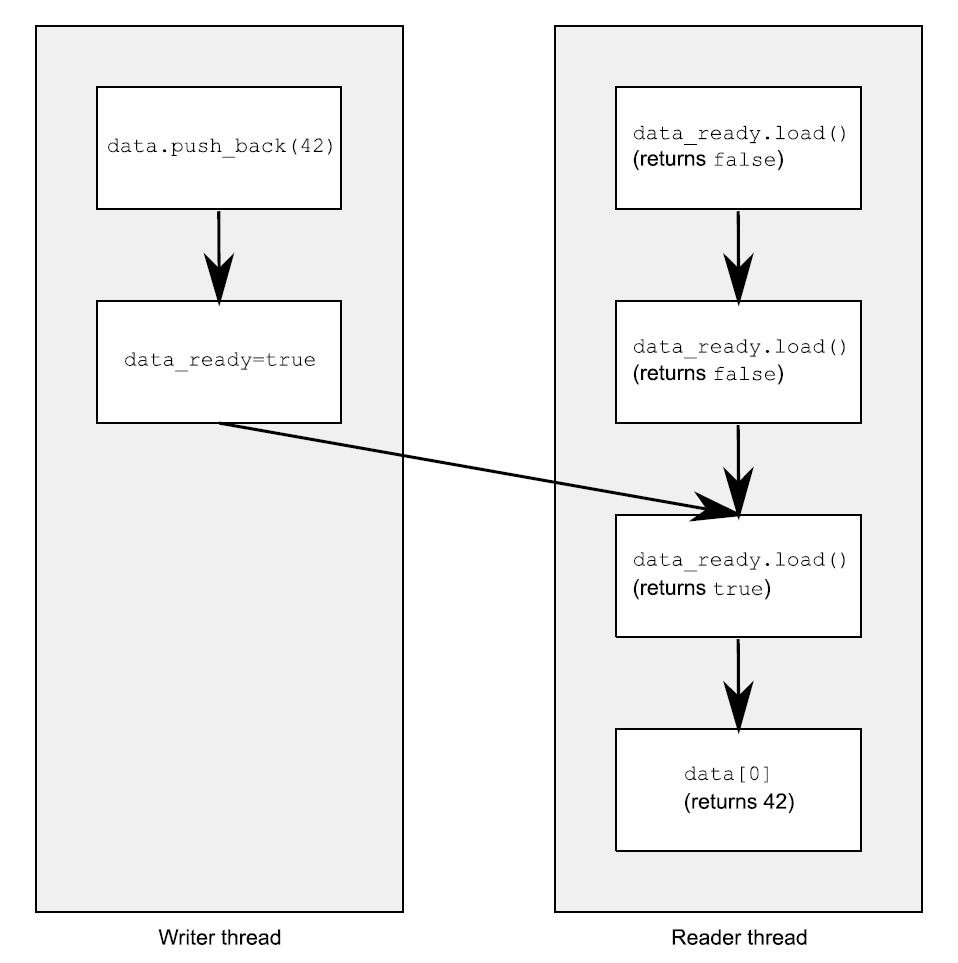
5.3 同步操作和强制排序假设你有两个线程,一个向数据结构中填充数据,另一个读取数据结构中的数据。为了避免恶性条件竞争,第一个线程设置一个标志,用来表明数据已经准备就绪,并且第二个线程在这个标志设置前不能读取数据。下面的程序清单就是这样的情况。 清单5.2 不同线程对数据的读写 1234567891011121314151617181920#include <vector>#include <atomic>#include <iostream>std::vector<int> data;std::atomic<bool> data_ready(false);void reader_thread(){ while(!data_ready.load()) // 1 { std::this_thread::sleep(std::milliseconds(1)); } std::cout<<"The answer="<<data[0]<...
5.2-chinese
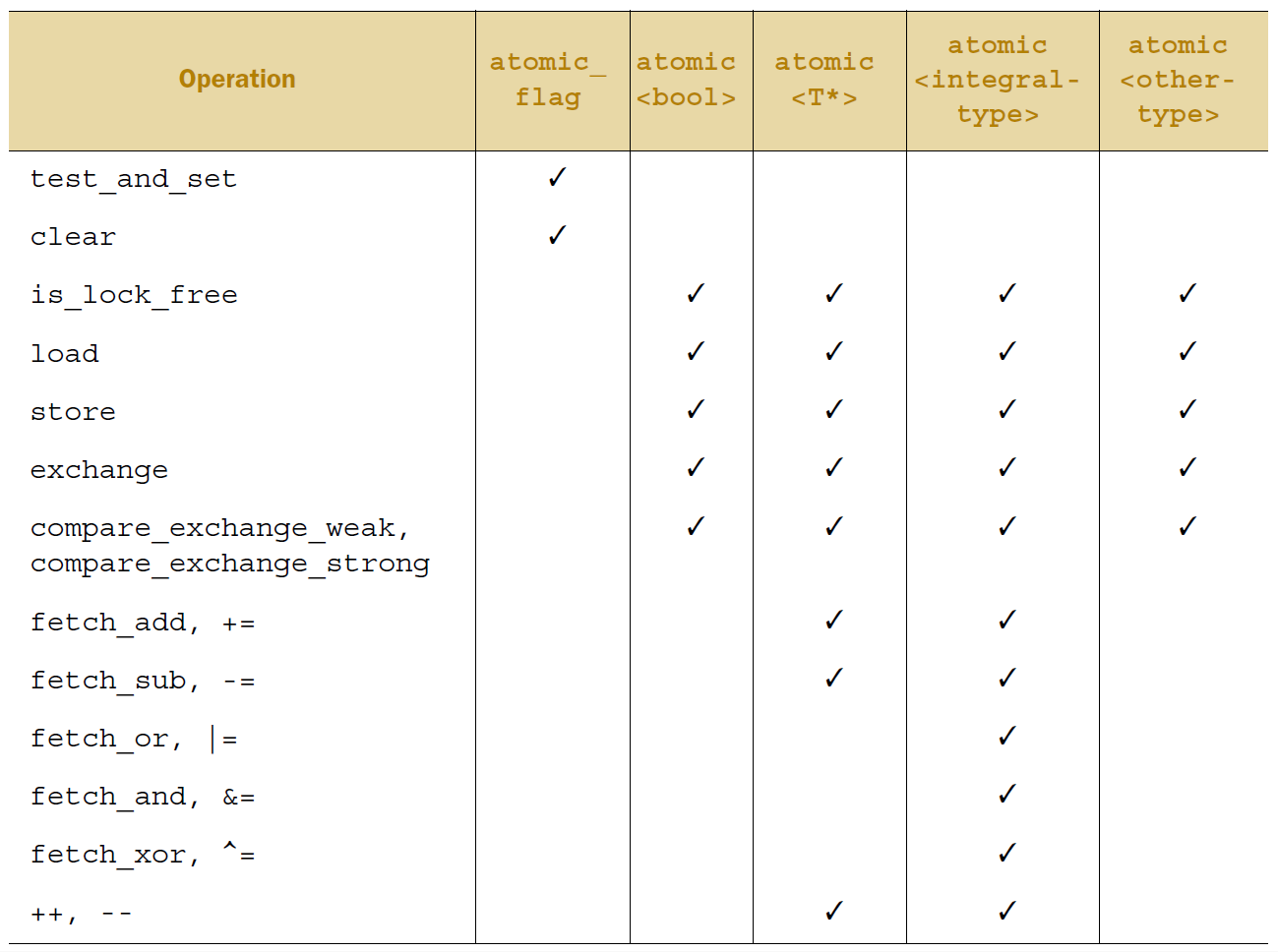
5.2 C++中的原子操作和原子类型原子操作 是个不可分割的操作。在系统的所有线程中,你是不可能观察到原子操作完成了一半这种情况的;它要么就是做了,要么就是没做,只有这两种可能。如果从对象读取值的加载操作是 原子 的,而且对这个对象的所有修改操作也是 原子 的,那么加载操作得到的值要么是对象的初始值,要么是某次修改操作存入的值。 另一方面,非原子操作可能会被另一个线程观察到只完成一半。如果这个操作是一个存储操作,那么其他线程看到的值,可能既不是存储前的值,也不是存储的值,而是别的什么值。如果这个非原子操作是一个加载操作,它可能先取到对象的一部分,然后值被另一个线程修改,然后它再取到剩余的部分,所以它取到的既不是第一个值,也不是第二个值,而是两个值的某种组合。正如第三章所讲的,这一下成了一个容易出问题的竞争冒险,但在这个层面上它可能就构成了 数据竞争 (见5.1节),就成了未定义行为。 在C++中,多数时候你需要一个原子类型来得到原子的操作,我们来看一下这些类型。 5.2.1 标准原子类型标准 原子类型 定义在头文件<atomic>中。这些类型上的所有操作都是原子的,在...

5.4-chinese
5.4 本章总结在本章中,已经对C++11内存模型的底层只是进行详尽的了解,并且了解了原子操作能在线程间提供基本的同步。这里包含基本的原子类型,由std::atomic<>类模板特化后提供;接口,以及对于这些类型的操作,还要有对内存序列选项的各种复杂细节,都由原始std::atomic<>类模板提供。 我们也了解了栅栏,了解其如何让执行序列中,对原子类型的操作同步成对。最后,我们回顾了本章开始的一些例子,了解了原子操作可以在不同线程上的非原子操作间,进行有序执行。 在下一章中,我们将看到如何使用高阶同步工具,以及原子操作并发访问的高效容器设计,还有我们将写一些并行处理数据的算法。

7.0-chinese
第7章 无锁并发数据结构设计本章主要内容 设计无锁并发数据结构 无锁结构中内存管理技术 对无锁数据结构设计的简单指导 上一章中,我们了解了在设计并发数据结构时会遇到的问题,根据指导意见指引,确定设计的安全性。对一些通用数据结构进行检查,并查看使用互斥锁对共享数据进行保护的实现例子。第一组例子就是使用单个互斥量来保护整个数据结构,但之后的例子就会使用多个锁来保护数据结构的不同部分,并且允许对数据结构进行更高级别的并发访问。 互斥量是一个强大的工具,其可以保证在多线程情况下可以安全的访问数据结构,并且不会有条件竞争或破坏不变量的情况存在。对于使用互斥量的代码,其原因也是很简单的:就是让互斥量来保护数据。不过,这并不会如你所想的那样;你可以回看一下第3章,回顾一下死锁形成的原因,再回顾一下基于锁的队列和查询表的例子,看一下细粒度锁是如何影响并发的。如果你能写出一个无锁并发安全的数据结构,那么就能避免这些问题。 在本章中,我们还会使用原子操作(第5章介绍)的“内存序”特性,并使用这个特性来构建无锁数据结构。设计这样的数据结构时,要格外的小心,因为这样的数据机构不是那么容易正确实现的,...

7.1-chinese
7.1 定义和意义使用互斥量、条件变量,以及“期望”来同步阻塞数据的算法和数据结构。应用调用库函数,将会挂起一个执行线程,直到其他线程完成某个特定的动作。库函数将调用阻塞操作来对线程进行阻塞,在阻塞移除前,线程无法继续自己的任务。通常,操作系统会完全挂起一个阻塞线程(并将其时间片交给其他线程),直到其被其他线程“解阻塞”;“解阻塞”的方式很多,比如解锁一个互斥锁、通知条件变量达成,或让“期望”就绪。 不使用阻塞库的数据结构和算法,被称为无阻塞结构。不过,无阻塞的数据结构并非都是无锁的,那么就让我们见识一下各种各样的无阻塞数据结构吧! 7.1.1 非阻塞数据结构在第5章中,我们使用std::atomic_flag实现了一个简单的自旋锁。一起回顾一下这段代码。 清单7.1 使用std::atomic_flag实现了一个简单的自旋锁 12345678910111213141516class spinlock_mutex{ std::atomic_flag flag;public: spinlock_mutex(): flag(ATOMIC_FLAG_INIT) &...

7.2-chinese
7.2 无锁数据结构的例子为了演示一些在设计无锁数据结构中所使用到的技术,我们将看到一些无锁实现的简单数据结构。这里不仅要在每个例子中描述一个有用的数据结构实现,还将使用这些例子的某些特别之处来阐述对于无锁数据结构的设计。 如之前所提到的,无锁结构依赖与原子操作和内存序及相关保证,以确保多线程以正确的顺序访问数据结构。最初,所有原子操作默认使用的是memory_order_seq_cst内存序;因为简单,所以使用(所有memory_order_seq_cst都遵循一种顺序)。不过,在后面的例子中,我们将会降低内存序的要求,使用memory_order_acquire, memory_order_release, 甚至memory_order_relaxed。虽然这个例子中没有直接的使用锁,但需要注意的是对std::atomic_flag的使用。一些平台上的无锁结构实现(实际上在C++的标准库的实现中),使用了内部锁(详见第5章)。另一些平台上,基于锁的简单数据结构可能会更适合;当然,还有很多平台不能一一说明;在选择一种实现前,需要明确需求,并且配置各种选项以满足要求。 那么,回到...

7.3-chinese
7.3 对于设计无锁数据结构的指导建议本章中的例子中,看到了一些复杂的代码可让无锁结构工作正常。如果要设计自己的数据结构,一些指导建议可以帮助你找到设计重点。第6章中关于并发通用指导建议还适用,不过这里需要更多的建议。我从例子中抽取了几个实用的指导建议,在你设计无锁结构数据的时候就可以直接引用。 7.3.1 指导建议:使用std::memory_order_seq_cst的原型std::memory_order_seq_cst比起其他内存序要简单的多,因为所有操作都将其作为总序。本章的所有例子,都是从std::memory_order_seq_cst开始,只有当基本操作正常工作的时候,才放宽内存序的选择。在这种情况下,使用其他内存序就是进行优化(早起可以不用这样做)。通常,当你看整套代码对数据结构的操作后,才能决定是否要放宽该操作的内存序选择。所以,尝试放宽选择,可能会让你轻松一些。在测试后的时候,工作的代码可能会很复杂(不过,不能完全保证内存序正确)。除非你有一个算法检查器,可以系统的测试,线程能看到的所有可能性组合,这样就能保证指定内存序的正确性(这样的测试的确存在),仅是执...

7.4-chinese
7.4 本章总结从第6章中的基于锁的数据结构起,本章简要的描述了一些无锁数据结构的实现(通过实现栈和队列)。在这个过程中,需要小心使用原子操作的内存序,为了保证无数据竞争,以及让每个线程看到一个预制相关的数据结构。也能了解到,在无锁结构中对内存的管理是越来越难。还有,如何通过帮助线程的方式,来避免忙等待循环。 设计无锁数据结构是一项很困难的任务,并且很容易犯错;不过,这样的数据结构在某些重要情况下可对其性能进行扩展。但愿,通过本章的的一些例子,以及一些指导意见,可以帮助你设计出自己的无锁数据结构,或是实现一份研究报告中的数据结构,或用以发现离职同事代码中的bug。 不管在线程间共享怎么样的数据,你需要考虑数据结构如何使用,并且怎么样在线程间同步数据。通过设计并发访问的数据结构,就能对数据结构的功能进行封装,其他部分的代码就着重于对数据的执行,而非数据的同步。你将会在第8章中看到类似的行为:将并发数据结构转为一般的并发代码。并行算法是使用多线程的方式提高性能,因为算法需要工作线程共享它们的数据,所以对并发数据结构的选择就很关键了。




