

01 Redis概述
Redis概述1 概述Redis 是速度非常快的非关系型(NoSQL)内存键值数据库,可以存储键和五种不同类型的值之间的映射。 键的类型只能为字符串,值支持五种数据类型:字符串、列表、集合、散列表、有序集合。 Redis 支持很多特性,例如将内存中的数据持久化到硬盘中,使用复制来扩展读性能,使用分片来扩展写性能。 优势使用Redis有哪些好处? 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1) 支持丰富数据类型,支持string,list,set,sorted set,hash 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行(4) 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除 2 Redis 与 Memcached两者都是非关系型内存键值数据库,主要有以下不同: 数据类型。 Memcached 仅支持字符串类型, Redis 支持五种不同的数据类型,可以更灵活地解决问题。 数据持久化。 Redis 支持两种持久化策略:RDB 快照和 AOF 日志...
03 数据结构
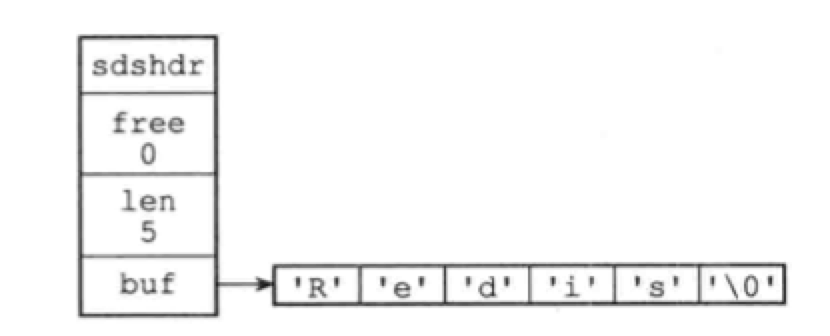
底层数据结构 参考文献 底层数据结构 底层数据结构 1 动态字符串SDS SDS 代码实现 SDS 特点(与C字符串的不同) SDS API 2 链表 双向链表 代码实现 链表 特点 链表 API 3 字典 字典的实现 哈希算法 解决键冲突 Rehash 哈希表的扩展与收缩 渐进式rehash 字典API 4 跳表 跳表 代码实现 跳表使用 跳跃表API 5 整数集合——特殊情况 整数集合的实现 升级 升级的好处 降级 整数集合API 6 压缩列表——特殊情况 压缩列表的构成 压缩列表节点的构成 连锁更新 压缩列表API 1 动态字符串SDSRedis构建了 简单动态字符串(simple dynamic string,SDS)来表示字符串值。 SDS还被用作缓冲区:AOF缓冲区,客户端状态中的输入缓冲区。 SDS 代码实现每个sds.h/sdshdr结构表示一个SDS值: 1234567891011struct sdshdr { // 记录buf数组中已使用字节的数量 // 等于SDS所保存字符串的长度 int le...

MARKDOWN
参考文档https://github.github.com/gfm/#precedence markdonw绘图时序图123A->B:因果关系B->A:返回值 流程图```flowst=>start: 第一步op=>operation: 第二步cond=>condition: Yes or No?e=>end st->op->condcond(yes)->econd(no)->op``` 右向图12345graph LRA[第一步<br/>第二行] -->B(第二步<br/>第二行) B --> C{决策} C -->|原因1| D[结果1<br/>第二行] C -->|原因2| E[结果2<br/>第二行] 扇形图12345pie title Pie Chart "原因一" : 9...
附录0 MySQL架构原理
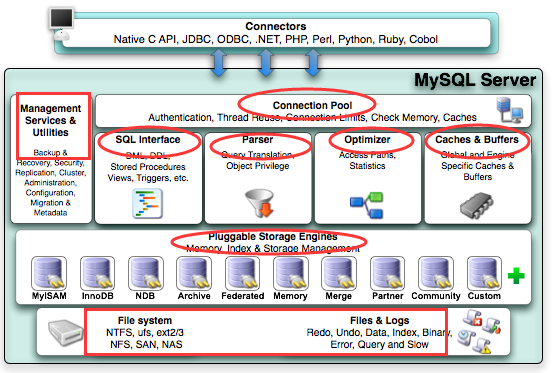
Mysql 架构原理 参考文献 Mysql 架构原理 1 概述分层结构概述 客户端:各种语言都提供了连接mysql数据库的方法,比如jdbc、php、go等,可根据选择 的后端开发语言选择相应的方法或框架连接mysql server层:包括连接器、查询缓存、分析器、优化器、执行器等,涵盖mysql的大多数核心服务功能,以及所有的内置函数(例如日期、世家、数 学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。 存储引擎层:负责数据的存储和提取,是真正与底层物理文件打交道的组件。 数据本质是存储在磁盘上的,通过特定的存储引擎对数据进行有组织的存放并根据业务需要对数据进行提取。存储引擎的架构模式是插件式的,支持Innodb,MyIASM、Memory等多个存储引擎。现在最常用的存储引擎是Innodb,它从mysql5.5.5版本开始成为了默认存储引擎。 物理文件层:存储数据库真正的表数据、日志等。物理文件包括:redolog、undolog、binlog、errorlog、querylog、slowlog、data、index等 连...

附录4 MySQL事务管理
MySQL事务管理 参考文献 Mysql并发控制 本章主要讲了MySQL的事务管理,即MySQL的并发控制,MySQL在并发过程中如何进行同步,即MySQL保证事物的原子性、隔离性、一致性、持久性的方法。也属于并发机制的一部分。 4 多级锁协议封锁粒度MySQL 各存储引擎使用了三种类型(级别)的锁定机制:表级锁定,行级锁定和页级锁定。 表级锁定(table-level)表级别的锁定是 MySQL 各存储引擎中最大颗粒度的锁定机制。该锁定机制最大的特点是实现逻辑非常简单,带来的系统负面影响最小。所以获取锁和释放锁的速度很快。由于表级锁一次会将整个表锁定,所以可以很好的避免困扰我们的死锁问题。当然,锁定颗粒度大所带来最大的负面影响就是出现锁定资源争用的概率也会最高,致使并发度大打折扣。使用表级锁定的主要是 MyISAM,MEMORY,CSV等一些非事务性存储引擎。 行级锁定(row-level)行级锁定最大的特点就是锁定对象的颗粒度很小,也是目前各大数据库管理软件所实现的锁定颗粒度最小的。由于锁定颗粒度很小,所以发生锁定资源争用的概率也最小,能够给予应用程序尽可能大的并...

附录5 MySQL连接查询
5 JOIN连接查询 参考文献 MySQL的JOIN用法 数据库实例 1234567891011121314151617181920212223242526272829303132333435 1 CREATE TABLE t_blog( 2 id INT PRIMARY KEY AUTO_INCREMENT, 3 title VARCHAR(50), 4 typeId INT 5 ); 6 SELECT * FROM t_blog; 7 +----+-------+--------+ 8 | id | title | typeId | 9 +----+-------+--------+10 | 1 | aaa | 1 |11 | 2 | bbb | 2 |12 | 3 | ccc | 3 |13 | 4 | ddd | 4 |14 | 5 | eee | 4 ...

附录3 MySQL索引类型
Mysql索引 参考文献 MySQL索引类型 1 索引类型——应用索引定义 普通索引 唯一索引 主键索引 组合索引 全文索引 12CREATE TABLE table_name[col_name data type][unique|fulltext][index|key][index_name](col_name[length])[asc|desc] unique|fulltext为可选参数,分别表示唯一索引、全文索引 index和key为同义词,两者作用相同,用来指定创建索引 col_name为需要创建索引的字段列,该列必须从数据表中该定义的多个列中选择 index_name指定索引的名称,为可选参数,如果不指定,默认col_name为索引值 length为可选参数,表示索引的长度,只有字符串类型的字段才能指定索引长度 asc或desc指定升序或降序的索引值存储 普通索引1.普通索引是最基本的索引,它没有任何限制。它有以下几种创建方式: (1)直接创建索引 1CREATE INDEX index_name ON table(column(length)) (2)修...


面试总结
创建型单例模式:某个类只能有一个实例,提供一个全局的访问点。 简单工厂:一个工厂类根据传入的参量决定创建出那一种产品类的实例。 工厂方法:定义一个创建对象的接口,让子类决定实例化那个类。 抽象工厂:创建相关或依赖对象的家族,而无需明确指定具体类。 生成器模式:封装一个复杂对象的构建过程,并可以按步骤构造。 原型模式:通过复制现有的实例来创建新的实例。 结构型 这几个都很相似,实现方法基本一致。但是功能略微有区别,应用场景不太一样。 适配器模式:将一个类的方法接口转换成客户希望的另外一个接口。 为了适应某些接口。依赖当前对象,生成新的接口。 桥接模式:将抽象部分和它的实现部分分离,使它们都可以独立的变化。 与策略模式完全一致。接口与实现分离。 组合模式:将对象组合成树形结构以表示“”部分-整体“”的层次结构。 树节点的典型表示。但每个节点可以有自己不同的属性,可以是不同的子类。 装饰模式:动态的给对象添加新的功能。 动态添加功能。原来的接口不变。Python中的derector。想在工程中使用这个功能的。但是通过桥接模式、适配器模式两层结构也解决了问题。在服务提供端...

Modern C++
主要用来记录 effectiveC++ 和more effective c++中涉及到的基础知识和高级特性。还有modern C++中的内容。主要包括C++11 17 20中新添加的特性。




