
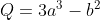
02 Pytorch 60分钟
一、PyTorch 60分钟 1 概述 什么是 PyTorch? 本次教程的目标: 2 模块 2.1 torch模块 2.2 torch.Tensor模块类 2.3 torch.sparse 2.4 torch.cuda 2.5 torch.nn.*模块 2.6 torch.nn.Functional函数模块 2.7 torch.nn.init模块 2.8 torch.optim模块 2.9 torch.autograd模块 2.10 torch.distributed模块 2.11 torch.distributions模块 2.12 torch.hub模块 2.13 torch.jit模块 2.14 torch.multiprocessing模块 2.15 torch.random模块 2.16 torch.onnx模块 2.17 torch.utils模块 1 torch.utils.bottleneck模块 2 torch.utils.checkpoint模块 3 torch.utils.cpp_extension模块 4 torch.utils.data模块 5 ...
10 Pysyft 概述
pysyft 对pytorch框架和TensorFlow框架的federated框架进行了研究。 tensorflow federated 框架只提供了本地的仿真。 pysyft 框架提供了websocket worker初步实现了基于websocket网络通信的多进程仿真,是当前最接近于实践的一种仿真方式,能够实现多个linux/python环境下的仿真与多个进程下的仿真。只在0.2.4中有,可以尝试在此基础进行改进和训练。 参考文献 A generic framework for privacy preserving deep learning FedAvg 的 Pytorch 实现 安全深度学习框架PySyft 1 论文阅读pysyft的特点PySyft是用于安全和隐私深度学习的Python库,它在主流深度学习框架(例如PyTorch和TensorFlow)中使用联邦学习,差分隐私和加密计算(例如多方计算(MPC)和同态加密(HE))将隐私数据与模型训练分离。 基于PyTorch,只支持深度学习建模,不支持LR、GBDT等传统方法? 支持联邦学习...
附录1 MySQL存储引擎
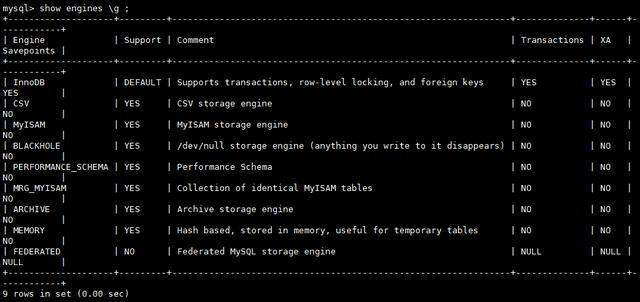
MySQL存储引擎1 概述MySQL架构存储引擎 MySQL中的数据用各种不同的技术存储在文件(或者内存)中。这些技术中的每一种技术都使用不同的存储机制、索引技巧、锁定水平并且最终提供广泛的不同的功能和能力。通过选择不同的技术,你能够获得额外的速度或者功能,从而改善你的应用的整体功能。 例如,如果你在研究大量的临时数据,你也许需要使用内存MySQL存储引擎。内存存储引擎能够在内存中存储所有的表格数据。又或者,你也许需要一个支持事务处理的数据库(以确保事务处理不成功时数据的回退能力)。 这些不同的技术以及配套的相关功能在 MySQL中被称作存储引擎(也称作表类型)。 MySQL默认配置了许多不同的存储引擎,可以预先设置或者在MySQL服务器中启用。你可以选择适用于服务器、数据库和表格的存储引擎,以便在选择如何存储你的信息、如何检索这些信息以及你需要你的数据结合什么性能和功能的时候为你提供最大的灵活性。 MySQL支持的存储引擎 存储引擎对比 功 能 MYISAM Memory InnoDB Archive 存储限制 256TB RAM 64TB None 支...

附录2 MySql性能优化
性能调优 参考文献 https://www.jb51.net/article/70111.htm https://www.cnblogs.com/jiekzou/p/5371085.html 0 基础方法 数据库设计优化: 选择合适的存储引擎 设计合理的表结构(符合3NF) 添加适当索引(index) 普通索引、主键索引、唯一索引、全文索引、组合索引、覆盖索引。 查询语句优化: 遵守查询规范。 分析日志:通过show status命令了解各种SQL的执行频率。定位执行效率较低的SQL语句(重点select,记录慢查询) explain分析低效率的SQL语句 查询过程优化 从内存中读取数据 减少磁盘写入操作(更大的写缓存) 提高磁盘读取速度(硬件设备改善) 1.1 存储引擎 支持全文索引:MyISAM 支持外键:Innodb 支持缓存:Innodb 支持事务:Innodb 支持并发:MyISAM 只支持表级锁,而 InnoDB 还支持行级锁。 支持备份:InnoDB 支持在线热备份。 崩溃恢复:MyISAM 崩溃后发生损坏的概率比 InnoDB 高很多,而且恢复...

附录5 协程
协程1 概念协程,又称微线程,纤程,英文名Coroutine。协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。 例如: 12345678def A() :print '1'print '2'print '3'def B() :print 'x'print 'y'print 'z' 由协程运行结果可能是12x3yz。在执行A的过程中,可以随时中断,去执行B,B也可能在执行过程中中断再去执行A。但协程的特点在于是一个线程执行。 2 区别 那和多线程比,协程最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。 第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。 3 其他在协程上利用多核CPU呢...

22 new&delete
C++中的new、operator new与placement new 参考文献 https://www.cnblogs.com/luxiaoxun/archive/2012/08/10/2631812.html https://blog.csdn.net/linuxheik/article/details/80449059 new operator/delete operator就是new和delete操作符。而operator new/operator delete是全局函数。 1 C++中的new/deletenew operator就是new操作符,不能被重载,假如A是一个类,那么A * a=new A;实际上执行如下3个过程。 调用operator new分配内存,operator new (sizeof(A)) 调用构造函数生成类对象,A::A() 返回相应指针 2 operator new/operator delete三种形式operator new是函数,分为三种形式(前2种不调用构造函...

23 数组参数
数组参数三种形式void test1(int *s)void test2(int s[])void test3(int s[5]) 实例12345678910111213141516171819202122232425262728#include <iostream>#include <vector>using namespace std;// 测试字符串和字符数组的参数传递void test1(int *s){ cout<<*(s)<<endl; return;}void test2(int s[]){ cout<<*s<<endl; return;}void test3(int s[5]){ cout<<*s<<endl; return;}int main(){ int s1[]={1,2,3,4,5,6,7,8}; int s2[3]=
...

2.6 协程
协程 最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。 第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。 因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
2.全局变量和静态变量和static
全局变量和静态变量1 介绍主要从两个维度进行介绍: 静态函数和静态变量。用来修饰不同的类型。 在类中、在块中、在全局中修饰的区别。 主要影响的有两个过程 作用域范围。全局、文件中、块作用域内 存储类型。静态类型。 补充的基础情况 默认情况下,全局变量是静态变量和全局变量。 相关的关键字 static的用法 2 全局static 在函数体、块作用域之外声明的变量与函数是全局的。 对于全局函数和全局变量,static修改标识符的链接属性,由默认的external变为internal,作用域和存储类型不改变,这些符号只能在声明它们的源文件中访问。 2 代码块 static 对于代码块内部的变量。static修改标识符的存储类型,由自动变量改为静态变量,作用域和链接属性不变。这种变量在程序执行之前就创建,在程序执行的整个周期都存在。 对于代码块内的函数,其只能在定义它的源文件中使用,不能在其他源文件中被引用 3 类成员 static 类的静态成员:在类中,静态成员可以实现多个对象之间的数据共享,并且使用静态数据成员还不会破坏隐藏的原则,即保证了安全性。因此,静态成员是类的所有...



