

6.10 差分数组
差分数组Sparse Array1 定义 定义:原数组为a,差分数组为d,那么有$$d[i] = a[i] - a[i - 1]$$ 其实差分数组是一个辅助数组,从侧面来表示给定某一数组的变化,一般用来对数组进行区间修改的操作 2 性质 a[i]等于d[i]的前缀和 $$a[i] = \sum_{0}^i d_i$$ d[i]等于a[i]两个临近元素的差$$d[i] = a[i] - a[i - 1]$$ 3 应用区间修改 当对一个区间进行增减某个值的时候,他的差分数组对应的区间左端点的值会同步变化,而他的右端点的后一个值则会相反地变化。他们的差分数组其实是不会变化的。 例如:将区间【1,4】的数值全部加上3 [l,r]区间内的数加k可以表示为如下形式: $$d[l]+k\d[r+1]-k$$ 元素求值 既然我们要对区间进行修改,那么差分数组的作用一定就是求多次进行区间修改后的数组。 直接反过来即得$$a[i]=a[i-1]+d[i]$$ 实例1 区间涂色问题描述 N个气球排成一排,从左到右依次编号为1,2,3…...

4.7 数组中的逆序对
1 数组中的逆序对问题描述在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。 问题分析策略选择 数据结构:线性数组 算法思想:变治法。将搜索查找问题修改为排序问题。归并排序 算法设计 归并排序」是分治思想的典型应用,它包含这样三个步骤: 分解: 待排序的区间为 [l, r],令 $m = \lfloor \frac{l + r}{2} \rfloor$,我们把 [l, r] 分成 [l,m] 和 [m+1,r] 解决: 使用归并排序递归地排序两个子序列 合并: 把两个已经排好序的子序列 [l, m][l,m] 和 [m + 1, r][m+1,r] 合并起来 在归并排序过程中。后边列表的数添加到前边之后。前边列表中数的量,就是本次排序逆序数的量。 算法分析 时间复杂度:同归并排序 O(nlogn)。 空间复杂度:同归并排序 O(n), 算法实现12345678910111213141516171819202122232425262728293031323334353637383940...

说明
参考文献 附加:sklearn分类的实验过程(以实战工程索引) cookbook入门教程(以流程索引) sklearn官方教程(以功能索引) sklearn API(以库名称索引) sklearn理解 按工作流程cookbook,数据加载、数据处理、分类、结果验证、模型使用 按官方文档doc,各种功能数据加载、特征选择、监督、无监督、评分 按api文档,各种类库
00 Pytorch 概述
学习 PyTorch 教程说明 0*是5套特殊的教程,一步步重构。 1*是pysyft相关的文章和教程 2*pytorch的基础教程。包含构建一个完整的神经网络的标准步骤。 过程 获取数据集 数据预处理 创建模型 定义模型:torch.nn.Model.__init__定义具有一些可学习参数(或权重)的神经网络 定义损失函数、训练算法、验证方法 训练模型 正向传播:torch.nn.Model.forward通过网络处理输入,进行正向传播 计算损失:torch.nn.loss输出正确的距离有多远 反向传播:torch.tensor.backward将梯度传播回网络参数 更新权重:troch.optim通常使用简单的更新规则来更新网络的权重:weight = weight - learning_rate * gradient 迭代循环:重复以上步骤直到(精确度满足要求 或者 迭代次数到达上限) 验证模型 术语 特征3*32*32 层:卷积层、池化层、全连接层 算子:卷积层使用的卷积算子。池化层的赤化算子3*3 激活函数:卷积层的的每个卷积算子计算完成后输出...

03 Pytorch 实例学习
通过示例学习 PyTorch 1 预热:NumPy 2 PyTorch:张量 3 Autograd 3.1 PyTorch:张量和 Autograd 3.2 PyTorch:定义新的 Autograd 函数 4 nn模块 4.1 PyTorch:nn 4.2 PyTorch:optim 4.3 PyTorch:自定义nn模块 4.4 PyTorch:控制流 + 权重共享 通过示例学习 PyTorchPyTorch 的核心是提供两个主要功能: n 维张量,类似于 NumPy,但可以在 GPU 上运行 用于构建和训练神经网络的自动微分 我们将使用将三阶多项式拟合y = sin(x)的问题作为运行示例。 该网络将具有四个参数,并且将通过使网络输出与实际输出之间的欧几里德距离最小化来进行梯度下降训练,以适应随机数据。 注意 您可以在本页浏览各个示例。 1 预热:NumPy在介绍 PyTorch 之前,我们将首先使用 numpy 实现网络。 Numpy 提供了一个 n 维数组对象,以及许多用于操纵这些数组的函数。 Numpy 是用于科学计算的通用框架。 它对计算图,深度学习或梯...
04 Pytorch nn本质
torch.nn到底是什么? 0 MNIST 数据集 1 从零开始的神经网络(没有torch.nn) 2 使用torch.nn.functional 3 使用nn.Module重构 4 使用nn.Linear重构 5 使用optim重构 6 使用Dataset重构 7 使用DataLoader重构 8 添加验证 8 创建fit()和get_data() 9 切换到 CNN nn.Sequential 9 包装DataLoader 10 使用您的 GPU 总结 torch.nn到底是什么?PyTorch 提供设计精美的模块和类torch.nn,torch.optim,Dataset和DataLoader神经网络。 为了充分利用它们的功能并针对您的问题对其进行自定义,您需要真正了解它们在做什么。 为了建立这种理解,我们将首先在 MNIST 数据集上训练基本神经网络,而无需使用这些模型的任何功能。 我们最初将仅使用最基本的 PyTorch 张量函数。 然后,我们将一次从torch.nn,torch.optim,Dataset或DataLoader中逐个添加一个函数,以准确显示每...
05 Pytorch 可视化
tensorboard 使用说明1 数据形式Tensorboard可以记录与展示以下数据形式: 标量Scalars 图片Images 音频Audio 计算图Graph 数据分布Distribution 直方图Histograms 嵌入向量Embeddings 2 操作流程tensorflow-tensorboardTensorboard的可视化过程 首先肯定是先建立一个graph,你想从这个graph中获取某些数据的信息 确定要在graph中的哪些节点放置summary operations以记录信息 1234使用tf.summary.scalar记录标量使用tf.summary.histogram记录数据的直方图使用tf.summary.distribution记录数据的分布图使用tf.summary.image记录图像数据 operations并不会去真的执行计算,除非你告诉他们需要去run,或者它被其他的需要run的operation所依赖。而我们上一步创建的这些summary operations其实并不被其他节点依赖,因此,我们需要特地去运行所有的summa...

40 Pytorch分布式概述
PyTorch 分布式概述 原文:https://pytorch.org/tutorials/beginner/dist_overview.html 作者:Shen Li 这是torch.distributed包的概述页面。 由于在不同位置添加了越来越多的文档,示例和教程,因此不清楚要针对特定问题咨询哪个文档或教程,或者阅读这些内容的最佳顺序是什么。 该页面的目的是通过将文档分类为不同的主题并简要描述每个主题来解决此问题。 如果这是您第一次使用 PyTorch 构建分布式训练应用,建议使用本文档导航至最适合您的用例的技术。 简介从 PyTorch v1.6.0 开始,torch.distributed中的功能可以分为三个主要组件: 分布式数据并行训练(DDP)是一种广泛采用的单程序多数据训练范例。 使用 DDP,可以在每个流程上复制模型,并且每个模型副本都将获得一组不同的输入数据样本。 DDP 负责梯度通信,以保持模型副本同步,并使其与梯度计算重叠,以加快训练速度。 基于 RPC 的分布式训练(RPC)开发来支持无法适应数据并行训练的常规训练结构,例如分布式管道并行性,参...

42 分布式数据并行
分布式数据并行入门 原文:https://pytorch.org/tutorials/intermediate/ddp_tutorial.html 作者:Shen Li 编辑:Joe Zhu 先决条件: PyTorch 分布式概述 DistributedDataParallel API 文档 DistributedDataParallel注意事项 DistributedDataParallel(DDP)在模块级别实现可在多台计算机上运行的数据并行性。 使用 DDP 的应用应产生多个进程,并为每个进程创建一个 DDP 实例。 DDP 在torch.distributed包中使用集体通信来同步梯度和缓冲区。 更具体地说,DDP 为model.parameters()给定的每个参数注册一个 Autograd 挂钩,当在后向传递中计算相应的梯度时,挂钩将触发。 然后,DDP 使用该信号触发跨进程的梯度同步。 有关更多详细信息,请参考 DDP 设计说明。 推荐的使用 DDP 的方法是为每个模型副本生成一个进程,其中一个模型副本可以跨越多个设备。 DDP 进程可以放在同一台计算机上,也...
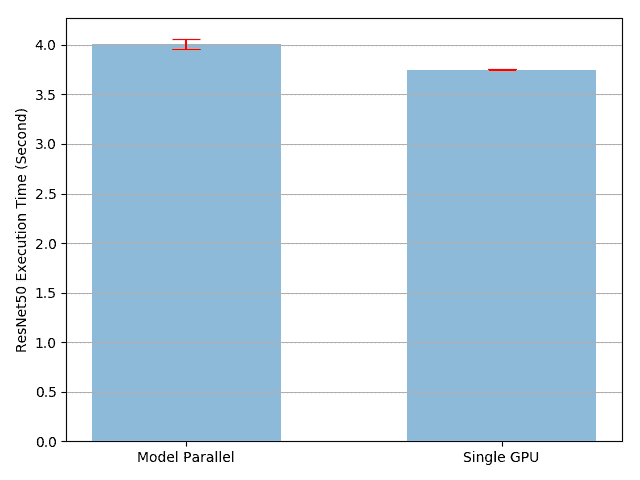
41 单机模型并行
单机模型并行最佳实践 原文:https://pytorch.org/tutorials/intermediate/model_parallel_tutorial.html 作者:Shen Li 模型并行在分布式训练技术中被广泛使用。 先前的帖子已经解释了如何使用DataParallel在多个 GPU 上训练神经网络; 此功能将相同的模型复制到所有 GPU,其中每个 GPU 消耗输入数据的不同分区。 尽管它可以极大地加快训练过程,但不适用于模型太大而无法容纳单个 GPU 的某些用例。 这篇文章展示了如何通过使用模型并行解决该问题,与DataParallel相比,该模型将单个模型拆分到不同的 GPU 上,而不是在每个 GPU 上复制整个模型(具体来说, 假设模型m包含 10 层:使用DataParallel时,每个 GPU 都具有这 10 层中的每一个的副本,而当在两个 GPU 上并行使用模型时,每个 GPU 可以承载 5 层。 模型并行化的高级思想是将模型的不同子网放置在不同的设备上,并相应地实现forward方法以在设备之间移动中间输出。 由于模型的一部分仅在任何单个设备上运行...




