

44 分布式RPC框架
分布式 RPC 框架入门 原文:https://pytorch.org/tutorials/intermediate/rpc_tutorial.html 作者:Shen Li 先决条件: PyTorch 分布式概述 RPC API 文档 本教程使用两个简单的示例来演示如何使用torch.distributed.rpc包构建分布式训练,该包首先在 PyTorch v1.4 中作为原型功能引入。 这两个示例的源代码可以在 PyTorch 示例中找到。 先前的教程分布式数据并行入门和使用 PyTorch 编写分布式应用,描述了DistributedDataParallel,该模型支持特定的训练范例,该模型可在多个进程之间复制,每个进程都处理输入数据的拆分。 有时,您可能会遇到需要不同训练范例的场景。 例如: 在强化学习中,从环境中获取训练数据可能相对昂贵,而模型本身可能很小。 在这种情况下,产生多个并行运行的观察者并共享一个智能体可能会很有用。 在这种情况下,智能体将在本地负责训练,但是应用仍将需要库在观察者和训练者之间发送和接收数据。 您的模型可能太大,无法容纳在一台计算机上...
43 Pytorch分布式应用
用 PyTorch 编写分布式应用 原文:https://pytorch.org/tutorials/intermediate/dist_tuto.html 作者:SébArnold 先决条件: PyTorch 分布式概述 在这个简短的教程中,我们将介绍 PyTorch 的分布式包。 我们将了解如何设置分布式设置,如何使用不同的交流策略以及如何查看包的一些内部内容。 设置PyTorch 中包含的分布式包(即torch.distributed)使研究人员和从业人员可以轻松地并行化他们在跨进程和机器集群的计算。 为此,它利用了传递消息的语义,从而允许每个进程将数据传递给任何其他进程。 与多处理包相反,进程可以使用不同的通信后端,而不仅限于在同一台计算机上执行。 为了开始,我们需要同时运行多个进程的能力。 如果您有权访问计算群集,则应咨询本地系统管理员或使用您喜欢的协调工具。 (例如 pdsh,clustershell 或其他)。出于本教程的目的,我们将使用以下模板使用一台计算机并分叉多个进程。 123456789101112131415161718192021222324252...

45 分布式RPC框架-参数服务器
使用分布式 RPC 框架实现参数服务器 原文:https://pytorch.org/tutorials/intermediate/rpc_param_server_tutorial.html 作者: Rohan Varma 先决条件: PyTorch 分布式概述 RPC API 文档 本教程介绍了一个简单的示例,该示例使用 PyTorch 的分布式 RPC 框架实现参数服务器。 参数服务器框架是一种范例,其中一组服务器存储参数(例如大型嵌入表),并且多个训练人员查询参数服务器以检索最新参数。 这些训练器可以在本地运行训练循环,并偶尔与参数服务器同步以获得最新参数。 有关参数服务器方法的更多信息,请查阅本文。 使用分布式 RPC 框架,我们将构建一个示例,其中多个训练器使用 RPC 与同一个参数服务器进行通信,并使用 RRef 访问远程参数服务器实例上的状态。 每位训练器将通过使用分布式 Autograd 跨多个节点拼接 Autograd 图,以分布式方式启动其专用的反向传递。 注意:本教程介绍了分布式 RPC 框架的用法,该方法可用于将模型拆分到多台计算机上,或用于实现参...
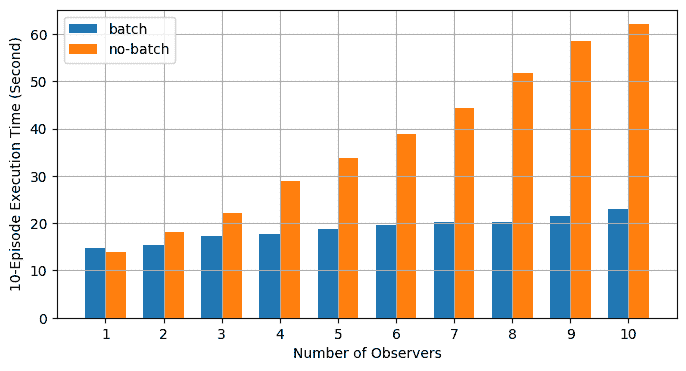
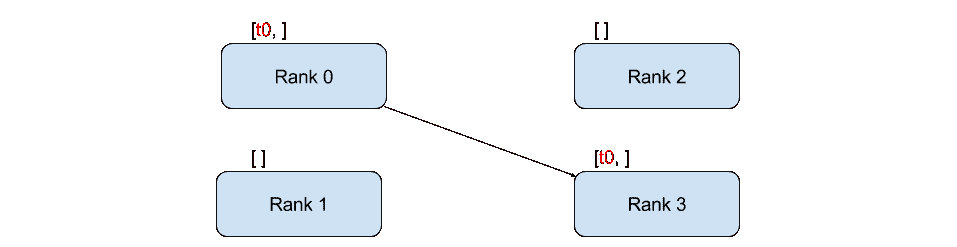
47 异步执行批量RPC处理
使用异步执行实现批量 RPC 处理 原文:https://pytorch.org/tutorials/intermediate/rpc_async_execution.html 作者:Shen Li 先决条件: PyTorch 分布式概述 分布式 RPC 框架入门 使用分布式 RPC 框架实现参数服务器 RPC 异步执行装饰器 本教程演示了如何使用@rpc.functions.async_execution装饰器来构建批量 RPC 应用,该装饰器通过减少阻止的 RPC 线程数和合并被调用方上的 CUDA 操作来帮助加快训练速度。 这使用 TorchServer 的相同想法进行批量推断。 注意 本教程需要 PyTorch v1.6.0 或更高版本。 基础知识先前的教程显示了使用torch.distributed.rpc构建分布式训练应用的步骤,但并未详细说明在处理 RPC 请求时被调用方发生的情况。 从 PyTorch v1.5 开始,每个 RPC 请求都会在被调用方上阻塞一个线程,以在该请求中执行该函数,直到该函数返回为止。 这适用于许多用例,但有一个警告。 如果用户函数例...

46 分布式RPC框架-管道并行化
使用 RPC 的分布式管道并行化 原文:https://pytorch.org/tutorials/intermediate/dist_pipeline_parallel_tutorial.html 作者:Shen Li 先决条件: PyTorch 分布式概述 单机模型并行最佳实践 分布式 RPC 框架入门 RRef 辅助函数: RRef.rpc_sync(), RRef.rpc_async()和 RRef.remote() 本教程使用 Resnet50 模型来演示如何使用torch.distributed.rpc API 实现分布式管道并行性。 可以将其视为单机模型并行最佳实践中讨论的多 GPU 管道并行性的分布式对应物。 注意 本教程需要 PyTorch v1.6.0 或更高版本。 注意 本教程的完整源代码可以在pytorch/examples中找到。 基础知识上一教程分布式 RPC 框架入门显示了如何使用torch.distributed.rpc为 RNN 模型实现分布式模型并行性。 该教程使用一个 GPU 来托管EmbeddingTable,并且提供的代码可以正常工...

48 分布式DataParallel与分布式RPC
将分布式DataParallel与分布式 RPC 框架相结合 原文:https://pytorch.org/tutorials/advanced/rpc_ddp_tutorial.html 作者: Pritam Damania 本教程使用一个简单的示例演示如何将DistributedDataParallel(DDP)与分布式 RPC 框架结合使用,以将分布式数据并行性与分布式模型并行性结合在一起,以训练简单模型。 该示例的源代码可以在中找到。 先前的教程分布式数据并行入门和分布式 RPC 框架入门分别描述了如何执行分布式数据并行训练和分布式模型并行训练。 虽然,有几种训练范例,您可能想将这两种技术结合起来。 例如: 如果我们的模型具有稀疏部分(较大的嵌入表)和密集部分(FC 层),则可能需要将嵌入表放在参数服务器上,并使用DistributedDataParallel。 分布式 RPC 框架可用于在参数服务器上执行嵌入查找。 如 PipeDream 论文中所述,启用混合并行性。 我们可以使用分布式 RPC 框架在多个工作程序之间流水线化模型的各个阶段,并使用Distribut...

0.1 fit&transform
fit&transform说明1 概述 fit和transform没有任何关系,仅仅是数据处理的两个不同环节,之所以出来fit_transform这个函数名,仅仅是为了写代码方便,会高效一点。 sklearn里的封装好的各种算法使用前都要fit,fit相对于整个代码而言,为后续API服务。fit之后,然后调用各种API方法,transform只是其中一个API方法,所以当你调用transform之外的方法,也必须要先fit。 fit原义指的是安装、使适合的意思,其实有点train的含义,但是和train不同的是,它并不是一个训练的过程,而是一个适配的过程,过程都是确定的,最后得到一个可用于转换的有价值的信息。 2 使用2.1 数据预处理中方法12fit(): Method calculates the parameters μ and σ and saves them as internal objects.解释:简单来说,就是求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性。 12transform(): Method using these c...
0 概述
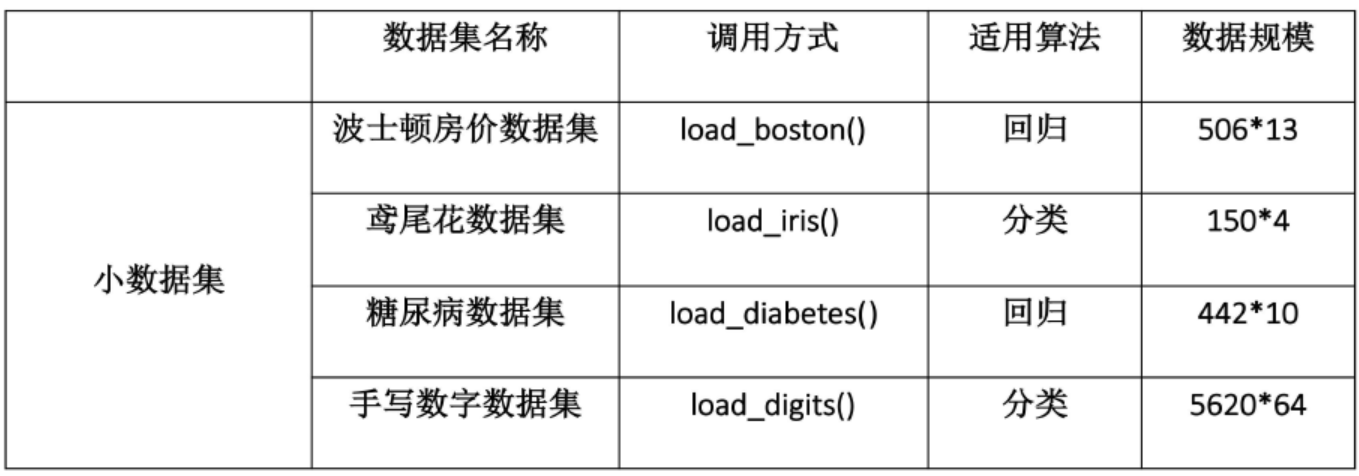
sklearn 概述参考文献 快速入门教程 python-sklearn使用教程 机器学习的一般流程 获取数据 sklearn.datasets 处理数据 feature_extraction feature_selection 训练模型 sklearn.model_selection 评估模型 estimator(score=[‘’])score参数 sklearn.metrics 使用模型 本文我们将依据传统机器学习的流程,看看在每一步流程中都有哪些常用的函数以及它们的用法是怎么样的。希望你看完这篇文章可以最为快速的开始你的学习任务。 1 获取数据1.1 导入sklearn数据集 sklearn中包含了大量的优质的数据集,在你学习机器学习的过程中,你可以通过使用这些数据集实现出不同的模型,从而提高你的动手实践能力,同时这个过程也可以加深你对理论知识的理解和把握。(这一步我也亟需加强,一起加油!^-^) 首先呢,要想使用sklearn中的数据集,必须导入datasets模块: 1from sklearn import datasets ...

0
零、前言 译者:@小瑶 校对者:@小瑶 1、机器学习海啸2006 年,Geoffrey Hinton 等人发表了一篇论文,展示了如何训练能够识别具有最新精度(> 98%)的手写数字的深度神经网络。他们称这种技术为“Deep Learning”。当时,深度神经网络的训练被广泛认为是不可能的,并且大多数研究人员自 20 世纪 90 年代以来就放弃了这个想法。这篇论文重新激起了科学界的兴趣,不久之后,许多新发表的论文表明,深度学习不仅是可能的,而且能够取得其他的 Machine Learning 技术都难以匹配的令人兴奋的成就(借助巨大的计算能力和大量的数据)。这种热情很快扩展到机器学习的许多的其他领域。 Deep Learning 快速发展的 10 年间和机器学习已经征服了这个行业:它现在成为了当今高科技产品中的许多黑科技的核心,比如,为您的网络搜索结果排名,为智能手机的语音识别提供支持,为您推荐您喜欢的视频,在围棋游戏中击败世界冠军。在你知道之前,它都可能会驾驶您的汽车。 2、您项目中的机器学习现在你是不是对机器学习感到兴奋,并且很乐意加入到这个阵营中?也许你希望给自己制造...
11
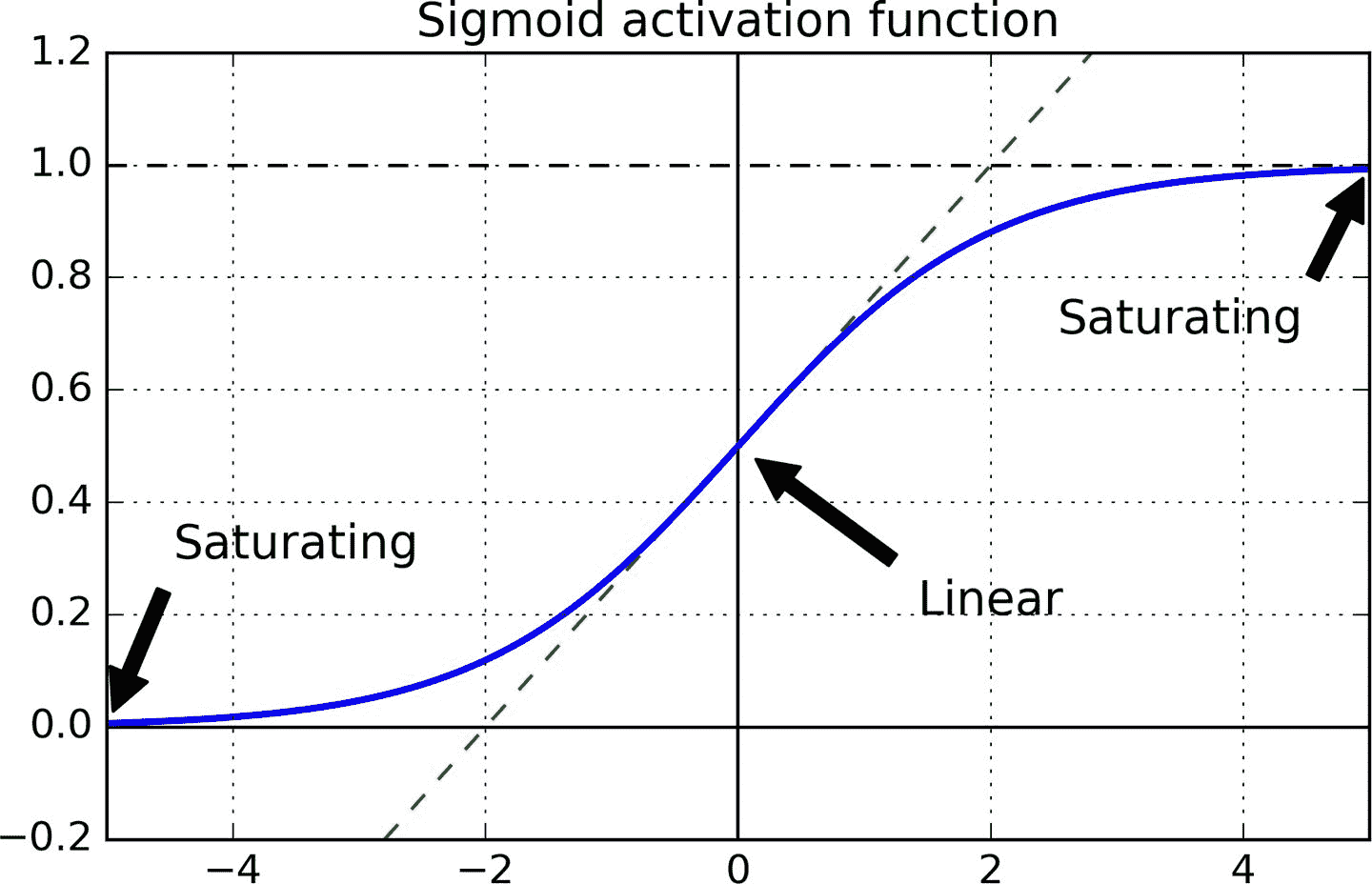
十一、训练深度神经网络 译者:@SeanCheney 第 10 章介绍了人工神经网络,并训练了第一个深度神经网络。 但它非常浅,只有两个隐藏层。 如果你需要解决非常复杂的问题,例如检测高分辨率图像中的数百种类型的对象,该怎么办? 你可能需要训练更深的 DNN,也许有 10 层或更多,每层包含数百个神经元,通过数十万个连接相连。 这可不像公园散步那么简单,可能碰到下面这些问题: 你将面临棘手的梯度消失问题(或相关的梯度爆炸问题):在反向传播过程中,梯度变得越来越小或越来越大。二者都会使较浅层难以训练; 要训练一个庞大的神经网络,但是数据量不足,或者标注成本很高; 训练可能非常慢; 具有数百万参数的模型将会有严重的过拟合训练集的风险,特别是在训练实例不多或存在噪音时。 在本章中,我们将依次讨论这些问题,并给出解决问题的方法。 我们将从梯度消失/爆炸问题开始,并探讨解决这个问题的一些最流行的解决方案。 接下来会介绍迁移学习和无监督预训练,这可以在即使标注数据不多的情况下,也能应对复杂问题。然后我们将看看各种优化器,可以加速大型模型的训练。 最后,我们将浏览一些流行的大型...




