
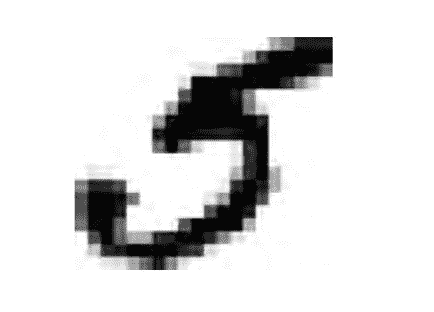
3
三、分类 译者:@时间魔术师 校对者:@Lisanaaa、@飞龙、@ZTFrom1994、@XinQiu、@tabeworks、@JasonLee、@howie.hu 在第一章我们提到过最常用的监督学习任务是回归(用于预测某个值)和分类(预测某个类别)。在第二章我们探索了一个回归任务:预测房价。我们使用了多种算法,诸如线性回归,决策树,和随机森林(这个将会在后面的章节更详细地讨论)。现在我们将我们的注意力转到分类任务上。 MNIST在本章当中,我们将会使用 MNIST 这个数据集,它有着 70000 张规格较小的手写数字图片,由美国的高中生和美国人口调查局的职员手写而成。这相当于机器学习当中的“Hello World”,人们无论什么时候提出一个新的分类算法,都想知道该算法在这个数据集上的表现如何。机器学习的初学者迟早也会处理 MNIST 这个数据集。 Scikit-Learn 提供了许多辅助函数,以便于下载流行的数据集。MNIST 是其中一个。下面的代码获取 MNIST 12345678910111213>>> from sklearn.datasets im...
2
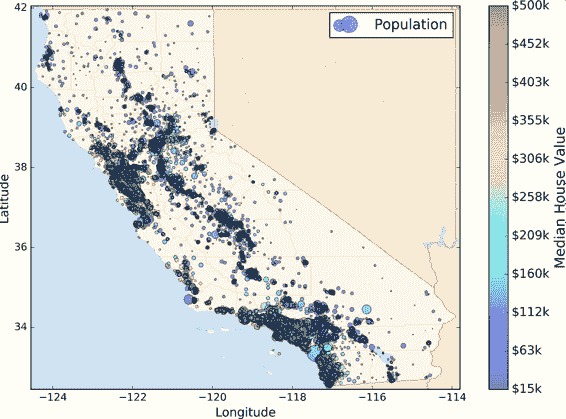
二、端到端的机器学习项目 译者:@SeanCheney 校对者:@Lisanaaa、@飞龙、@PeterHo、@ZhengqiJiang、@tabeworks 本章中,你会假装作为被一家地产公司刚刚雇佣的数据科学家,完整地学习一个案例项目。下面是主要步骤: 项目概述。 获取数据。 发现并可视化数据,发现规律。 为机器学习算法准备数据。 选择模型,进行训练。 微调模型。 给出解决方案。 部署、监控、维护系统。 使用真实数据学习机器学习时,最好使用真实数据,而不是人工数据集。幸运的是,有上千个开源数据集可以进行选择,涵盖多个领域。以下是一些可以查找的数据的地方: 流行的开源数据仓库: UC Irvine Machine Learning Repository Kaggle datasets Amazon’s AWS datasets 准入口(提供开源数据列表) http://dataportals.org/ http://opendatamonitor.eu/ http://quandl.com/ 其它列出流行开源数据仓库的网页: Wikipedia’...
5
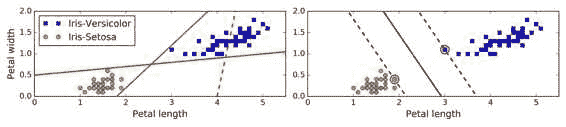
五、支持向量机 译者:@QiaoXie 校对者:@飞龙、@PeterHo、@yanmengk、@YuWang 支持向量机(SVM)是个非常强大并且有多种功能的机器学习模型,能够做线性或者非线性的分类,回归,甚至异常值检测。机器学习领域中最为流行的模型之一,是任何学习机器学习的人必备的工具。SVM 特别适合应用于复杂但中小规模数据集的分类问题。 本章节将阐述支持向量机的核心概念,怎么使用这个强大的模型,以及它是如何工作的。 线性支持向量机分类SVM 的基本思想能够用一些图片来解释得很好,图 5-1 展示了我们在第 4 章结尾处介绍的鸢尾花数据集的一部分。这两个种类能够被非常清晰,非常容易的用一条直线分开(即线性可分的)。左边的图显示了三种可能的线性分类器的判定边界。其中用虚线表示的线性模型判定边界很差,甚至不能正确地划分类别。另外两个线性模型在这个数据集表现的很好,但是它们的判定边界很靠近样本点,在新的数据上可能不会表现的很好。相比之下,右边图中 SVM 分类器的判定边界实线,不仅分开了两种类别,而且还尽可能地远离了最靠近的训练数据点。你可以认为 SVM 分类器在两种类别之间保持...
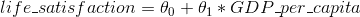
4
四、训练模型 译者:@C-PIG 校对者:@PeterHo、@飞龙、@YuWang、@AlecChen 在之前的描述中,我们通常把机器学习模型和训练算法当作黑箱子来处理。如果你实践过前几章的一些示例,你惊奇的发现你可以优化回归系统,改进数字图像的分类器,你甚至可以零基础搭建一个垃圾邮件的分类器,但是你却对它们内部的工作流程一无所知。事实上,许多场合你都不需要知道这些黑箱子的内部有什么,干了什么。 然而,如果你对其内部的工作流程有一定了解的话,当面对一个机器学习任务时候,这些理论可以帮助你快速的找到恰当的机器学习模型,合适的训练算法,以及一个好的假设集。同时,了解黑箱子内部的构成,有助于你更好地调试参数以及更有效的误差分析。本章讨论的大部分话题对于机器学习模型的理解,构建,以及神经网络(详细参考本书的第二部分)的训练都是非常重要的。 首先我们将以一个简单的线性回归模型为例,讨论两种不同的训练方法来得到模型的最优解: 直接使用封闭方程进行求根运算,得到模型在当前训练集上的最优参数(即在训练集上使损失函数达到最小值的模型参数) 使用迭代优化方法:梯度下降(GD),在训练集上,它可...
7
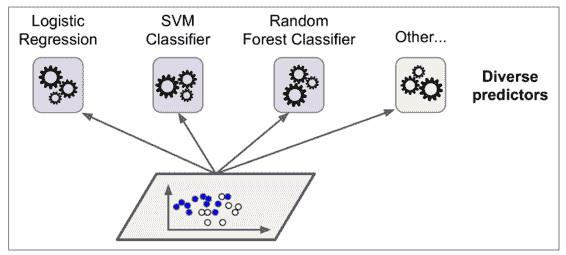
七、集成学习和随机森林 译者:@friedhelm739 校对者:@飞龙、@PeterHo、@yanmengk、@XinQiu、@YuWang 假设你去随机问很多人一个很复杂的问题,然后把它们的答案合并起来。通常情况下你会发现这个合并的答案比一个专家的答案要好。这就叫做群体智慧。同样的,如果你合并了一组分类器的预测(像分类或者回归),你也会得到一个比单一分类器更好的预测结果。这一组分类器就叫做集成;因此,这个技术就叫做集成学习,一个集成学习算法就叫做集成方法。 例如,你可以训练一组决策树分类器,每一个都在一个随机的训练集上。为了去做预测,你必须得到所有单一树的预测值,然后通过投票(例如第六章的练习)来预测类别。例如一种决策树的集成就叫做随机森林,它除了简单之外也是现今存在的最强大的机器学习算法之一。 向我们在第二章讨论的一样,我们会在一个项目快结束的时候使用集成算法,一旦你建立了一些好的分类器,就把他们合并为一个更好的分类器。事实上,在机器学习竞赛中获得胜利的算法经常会包含一些集成方法。 在本章中我们会讨论一下特别著名的集成方法,包括 bagging, boosting, s...
6
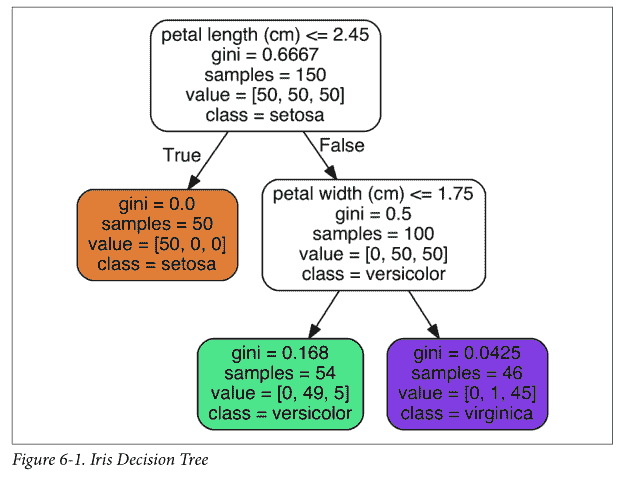
# 六、决策树 > 译者:[@Lisanaaa](https://github.com/Lisanaaa)、[@y3534365](https://github.com/y3534365) > > 校对者:[@飞龙](https://github.com/wizardforcel)、[@YuWang](https://github.com/bigeyex) 和支持向量机一样, 决策树是一种多功能机器学习算法, 即可以执行分类任务也可以执行回归任务, 甚至包括多输出(multioutput)任务. 它是一种功能很强大的算法,可以对很复杂的数据集进行拟合。例如,在第二章中我们对加利福尼亚住房数据集使用决策树回归模型进行训练,就很好的拟合了数据集(实际上是过拟合)。 决策树也是随机森林的基本组成部分(见第 7 章),而随机森林是当今最强大的机器学习算法之一。 在本章中,我们将首先讨论如何使用决策树进行训练,可视化和预测。 然后我们会学习在 Scikit-learn 上面使用 CART 算法,并且探讨如何调整决策树让它可以用于执行回归任务。 最后,我们当然也需要讨论一...
8
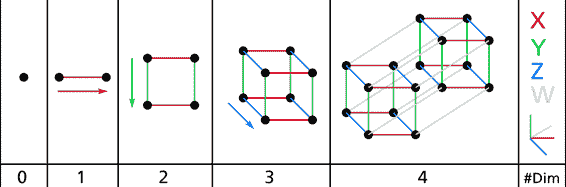
八、降维 译者:@loveSnowBest 校对者:@飞龙、@PeterHo、@yanmengk、@XinQiu、@Lisanaaa 很多机器学习的问题都会涉及到有着几千甚至数百万维的特征的训练实例。这不仅让训练过程变得非常缓慢,同时还很难找到一个很好的解,我们接下来就会遇到这种情况。这种问题通常被称为维数灾难(curse of dimentionality)。 幸运的是,在现实生活中我们经常可以极大的降低特征维度,将一个十分棘手的问题转变成一个可以较为容易解决的问题。例如,对于 MNIST 图片集(第 3 章中提到):图片四周边缘部分的像素几乎总是白的,因此你完全可以将这些像素从你的训练集中扔掉而不会丢失太多信息。图 7-6 向我们证实了这些像素的确对我们的分类任务是完全不重要的。同时,两个相邻的像素往往是高度相关的:如果你想要将他们合并成一个像素(比如取这两个像素点的平均值)你并不会丢失很多信息。 警告:降维肯定会丢失一些信息(这就好比将一个图片压缩成 JPEG 的格式会降低图像的质量),因此即使这种方法可以加快训练的速度,同时也会让你的系统表现的稍微差一点。降维...

SUMMARY
Sklearn 与 TensorFlow 机器学习实用指南第二版 零、前言 一、机器学习概览 二、端到端的机器学习项目 三、分类 四、训练模型 五、支持向量机 六、决策树 七、集成学习和随机森林 八、降维 十、使用 Keras 搭建人工神经网络 十一、训练深度神经网络 十二、使用 TensorFlow 自定义模型并训练 十三、使用 TensorFlow 加载和预处理数据 十四、使用卷积神经网络实现深度计算机视觉 十五、使用 RNN 和 CNN 处理序列 十六、使用 RNN 和注意力机制进行自然语言处理 十七、使用自编码器和 GAN 做表征学习和生成式学习 十八、强化学习 十九、规模化训练和部署 TensorFlow 模型

AI学习路线
基础知识 1.数学数学是学不完的,也没有几个人能像博士一样扎实地学好数学基础,入门人工智能领域,其实只需要掌握必要的基础知识就好。AI的数学基础最主要是高等数学、线性代数、概率论与数理统计三门课程,这三门课程是本科必修的。这里整理了一个简易的数学入门文章。数学基础: 高等数学https://zhuanlan.zhihu.com/p/36311622数学基础: 线性代数https://zhuanlan.zhihu.com/p/36584206数学基础: 概率论与数理统计https://zhuanlan.zhihu.com/p/36584335 机器学习的数学基础资料下载:1.机器学习的数学基础.docx中文版,对高等数学、线性代数、概率论与数理统计三门课的公式做了总结2) 斯坦福大学机器学习的数学基础.pdf原版英文材料,非常全面,建议英语好的同学直接学习这个材料下载链接: https://pan.baidu.com/s/1LaUlrJzy98CG1Wma9FgBtg 提取码: hktx 推荐教材相比国内浙大版和同济版的数学教材,通俗易懂,便于初学者更好地奠定数学基础下载链接: ...

00SUMMARY
莫烦 PyTorch 系列教程 PyTorch 简介 1.1 – Why PyTorch? 1.2 – 安装 PyTorch PyTorch 神经网络基础 2.1 – Torch vs Numpy 2.2 – 变量 (Variable) 2.3 – 激励函数 (Activation) 建造第一个神经网络 3.1 – 关系拟合 (回归 Regression) 3.2 – 区分类型 (分类 Classification) 3.3 – 快速搭建回归神经网络 3.4 – 保存和恢复模型 3.5 – 数据读取 (Data Loader) 3.6 – 优化器 (Optimizer) 高级神经网络结构 4.1 – CNN 卷积神经网络 4.2 – RNN 循环神经网络 (分类 Classification) 4.3 – RNN 循环神经网络 (回归 Regression) 4.4 – AutoEncoder (自编码/非监督学习) 4.5 – DQN 强化学习 (Reinforcement Learning) 4.6 – GAN (Generative Adversar...




